R语言如何去除表格中的重复的单词?
这里有一组数据,请问如何将整个表中出现过的词提取出来放在year 2018后面一行,重复的只提取一次。用R语言,谢谢!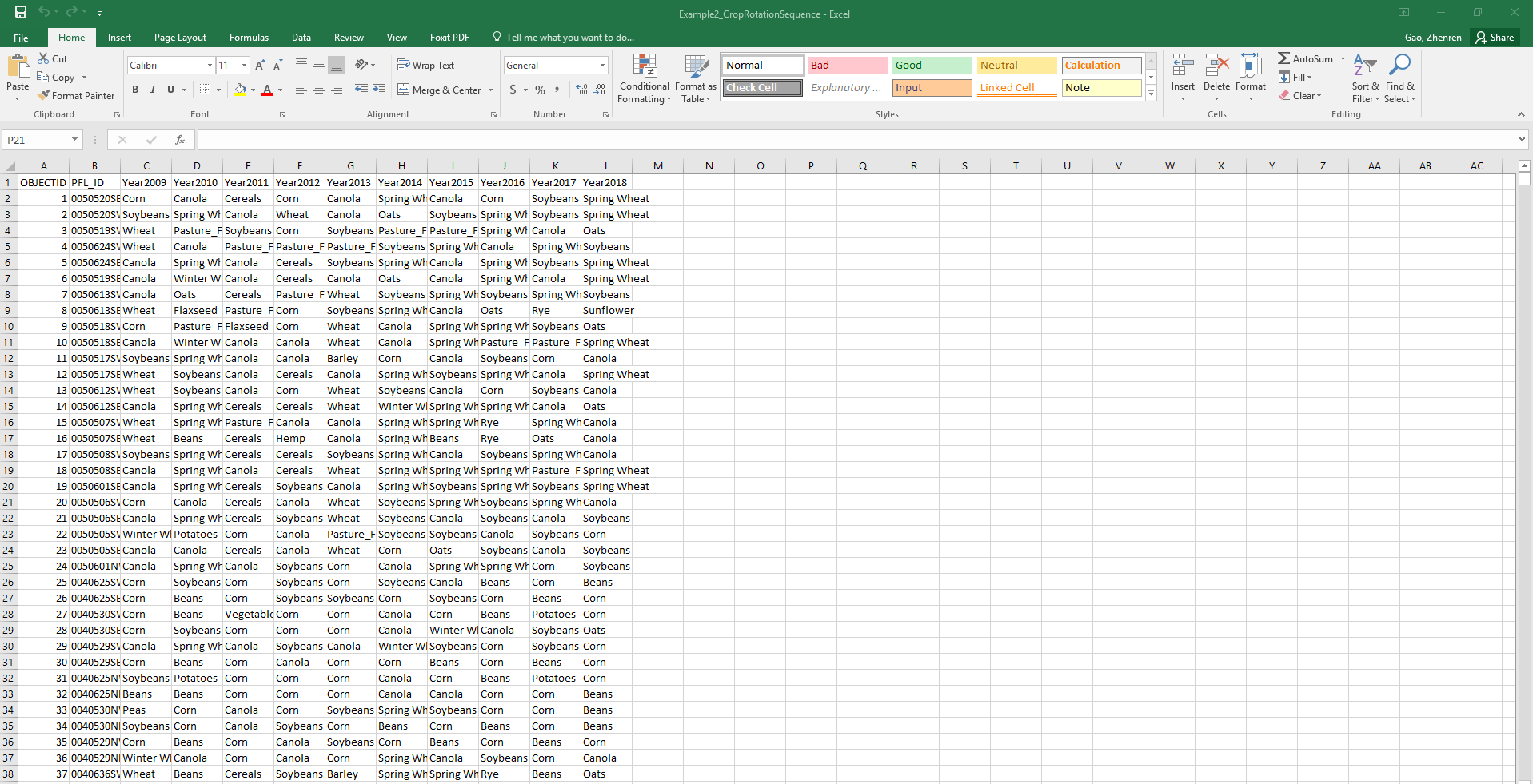
不知道你去重复的标准是什么,是不是按照行,那么首先需要导入
library(rjava)
library(xlsx)
然后用
dat <- read.xlsx(excel文件名)
dat %>% distinct()
这里有一组数据,请问如何将整个表中出现过的词提取出来放在year 2018后面一行,重复的只提取一次。用R语言,谢谢!
不知道你去重复的标准是什么,是不是按照行,那么首先需要导入
library(rjava)
library(xlsx)
然后用
dat <- read.xlsx(excel文件名)
dat %>% distinct()