用torchtext建立text-cnn的数据集时,一直报相同的错误,请问如何解决?
这是代码
from torchtext import data
TEXT = data.Field(sequential=True, fix_length=1000)
LABEL = data.Field(sequential=False, use_vocab=False)
train, test = data.TabularDataset.splits(
path='./', train='train3.csv', test='train3.csv',
format='csv', delimiter=',',
fields=[('text', TEXT), ('label', LABEL)])
这是csv文件
text,label
a,1
b,0
c,1
这是报错
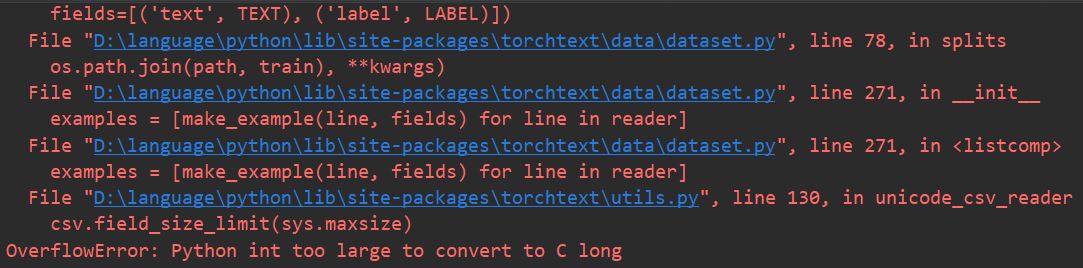
谢谢!!
---------------------------分割线-------------------------------
已自行解决!
把python\lib\site-packages\torchtext\utils.py文件中的unicode_csv_reader函数以下代码段
maxInt = sys.maxsize
while True:
# decrease the maxInt value by factor 10
# as long as the OverflowError occurs.
try:
csv.field_size_limit(maxInt)
break
except OverflowError:
maxInt = int(maxInt / 10)
csv.field_size_limit(sys.maxsize)
最后一行csv.field_size_limit(sys.maxsize)删去即可