为什么我用Python抓不到豆瓣电影的信息?
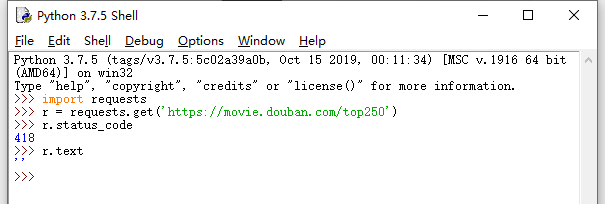
如图所示
状态码418是什么啊?
加上user-agent看看
你被服务器判断为非法爬虫而不是真实请求了。
给你一段完全可用的代码,使用前需要安装requests和beautifulsoup4
pip install requests
pip install beautifulsoup4下面的代码可以得到《肖申克的救赎》这部电影演员名称以及人物照片链接
import requests
import re
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/subject/1292052/'
ua = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15'
page = requests.get(url, headers={'User-Agent': ua})
soup = BeautifulSoup(page.text, 'html.parser')
[print(row.find('a')['title'], re.search(r'http[^\)]*', row.find('a').find('div')
['style']).group()) for row in soup.find_all('li', 'celebrity')]