python爬取网站时抓不到网站源代码?
爬取这个网站时:http://www.mafengwo.cn/poi/18972.html,抓取不到网站源代码,网页查看时有,但是python get不到,soup、xpath都查不到,请问是什么问题,怎么爬取呢?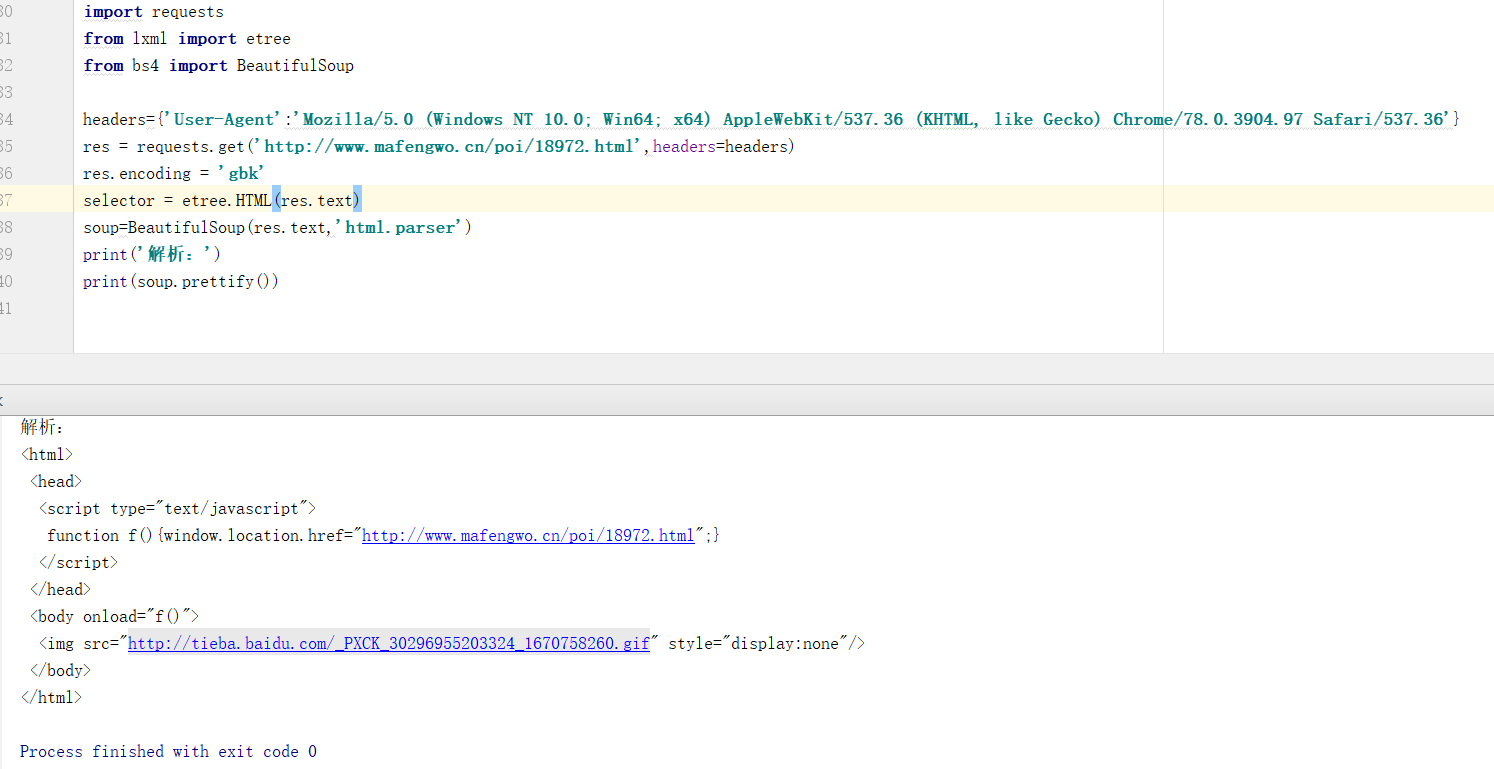
我这里看了下,用到了gzip压缩,你有正确解压缩么,文本的编码是否正确。
你可以看看是否为动态加载页面,如果是,你可以使用selenium库的webdriver来动态爬取
首先在你的浏览器上安装对应的插件(例如我的浏览器是chrome)
driver = webdriver.Chrome
driver.get('website')
如果要想保存登录信息,可以去我的博文里看看