如何用pypsark实现多任务并发处理?
需求:Spark的一个非常常见的用例是并行运行许多作业。如同一时间的10张表同并行做处理,如何通过pyspark实现?
from pyspark.sql import SparkSession
from pyspark.sql import HiveContext
import sys
import logging
import time
from multiprocessing.dummy import Pool as ThreadPool
logging.basicConfig(format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s',
level=logging.INFO)
def test(spark,a,b):
spark.sql('use %s' %(a))
spark.sql('select * FROM b limit 1' %(b)
if __name__ == '__main__':
spark = SparkSession.builder \
.appName("datapre_dropd") \
.config("hive.metastore.uris", "thrift://***:***")\
.enableHiveSupport()\
.getOrCreate()
a="ss"
tbs=['test1','test2']
end1=time.time()
#多线程方式:
tpool = ThreadPool(len(tbs)) # 创建一个线程池
for tb in tbs:
tpool.apply_async(test,args=(spark,a,tb))
end2=time.time()
logging.info("并发任务数:%s,并发任务执行时间:%s" %(str(len(tbs)),str(end2-end1)))
spark.stop()
client模式下可以正常提交任务,但不会实际执行。如下图,可以看到执行了第一句就跳出了。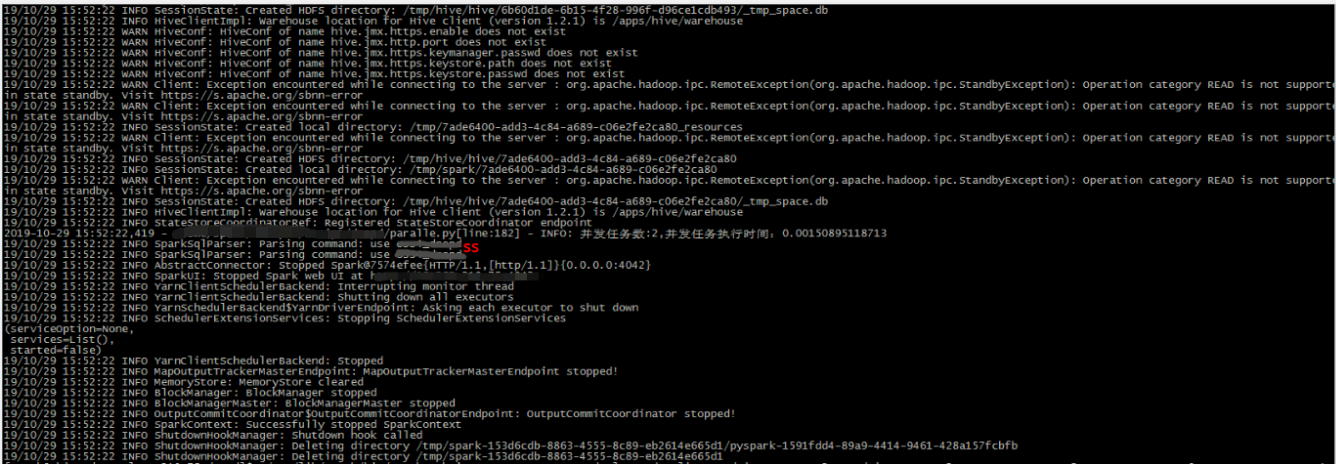
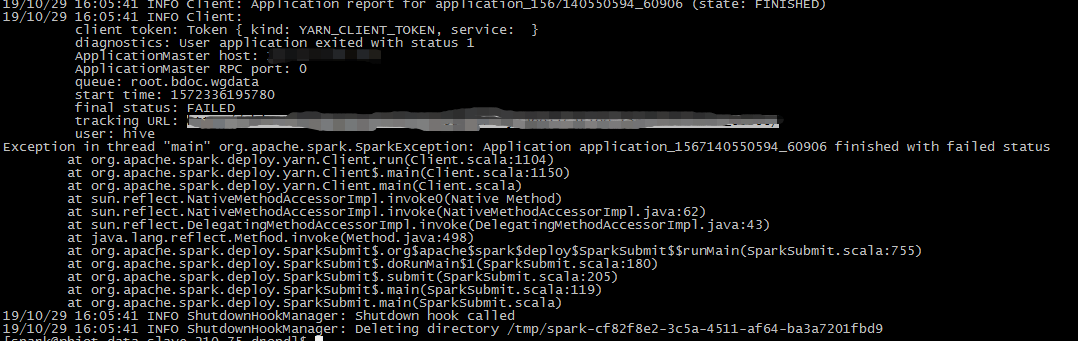
cluster模式下执行会报错: