两个表inner join后 order by 两个字段排序,一个 ASC 一个DESC 查询很慢,改怎么优化?
A是小表 3000条,B是大表 50万条
CREATE TABLE A (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL,
`creator` varchar(24) NOT NULL,
`price` varchar(64) NOT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` tinyint(1) not null,
PRIMARY KEY (`id`)
);
CREATE TABLE B (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL,
`pid` bigint(20) NOT NULL,
`status` int not null,
`type` varchar(12) NOT NULL DEFAULT '0',
`quantity` int not null default 1,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
);
有这样的一句sql
SELECT * FROM A t1 INNER JOIN B t2 ON t2.pid = t1.id ORDER BY t1.status ASC, t2.ctime DESC LIMIT 0, 30;
如果不用 t1.status 排序,速度会快很多,加上之后就变慢了,要3s 才能查出来,这样的sql 该怎么优化了?
status字段为什么要对它进行排序呢?有意义吗?
用真实的数据举个例子
person_pool:65w行 tracking_info:26w行
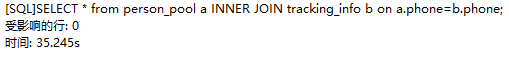
不用连接查询的速度明显快了
你可以把连接查询改成普通的条件查询,然后给B表的pid加个索引,最好把select后面的* 改成具体的列名,效果会更好
自己去参考一下反转索引的用法,应该能解决你说的问题。如果实在不懂,可在底下留言。