小型服务器上的大内存使用量(优化问题)
I have an application that analyzes data from input files that are generated by our core system. Depending on the client, that file can vary in size (files contain online marketing metrics such as clicks, impressions, etc..). One of our clients has a website that gets a fairly large amount of traffic, and the metric files generated are around 3-4 megabytes in size. This application currently analyzes three files at a time, each file being a different time aggregate.
I'm reading in the file using a CSV iterator, and it stores the contents of the entire file into a multi-dimensional array. The array for one of the particular files is around 16000 elements long, with each subarray being 31 elements. The dataprocessor object that handles loading this data utilizes about 50MB of memory. Currently the PHP memory limit is set to 100MB. Unfortunately the server this application is on is old and can't handle much of a memory increase.
So this brings me to the question: how can I optimize processing a file this size?
Could a possible optimization be reading in parts of the file, calculate, store, repeat?
You're on the right track. If at all possible, read a line, do whatever you need to do to it (counting whatever you're counting, etc), and then discard the line.
See the example for fgets()
Why not simply read the file line by line... -> read line -> store what you need, update your statistics -> read next line, etc.
You could modify CSVIterator and read parts of the file at a time or a line at a time.
$handle = fopen("/tmp/inputfile.txt", "r");
if ($handle) {
while(!feof($handle)){
$buffer = fread($handle, 4096);
echo $buffer;
}
}
or
$handle = fopen("/tmp/inputfile.txt", "r");
if ($handle) {
while (!feof($handle)) {
$buffer = fgets($handle, 4096);
echo $buffer;
}
fclose($handle);
}
可以看看用火焰图来分析,然后调试CPU:
全文,请参见原文:如何使用性能分析来调试Python的性能问题 【使用火焰图找出问题根源】
https://blog.csdn.net/SusyYang/article/details/113927192
如何使用火焰图调试性能问题(并在服务器上节省下6.6万美元)
假设下面的火焰图对应呈现上图中央处理器利用率飙升的时段。在此高峰期间,服务器的中央处理器的使用情况如下:
- Foo()消耗的时间是75%
- Bar()消耗的时间是25%
- 10万美元的服务器成本
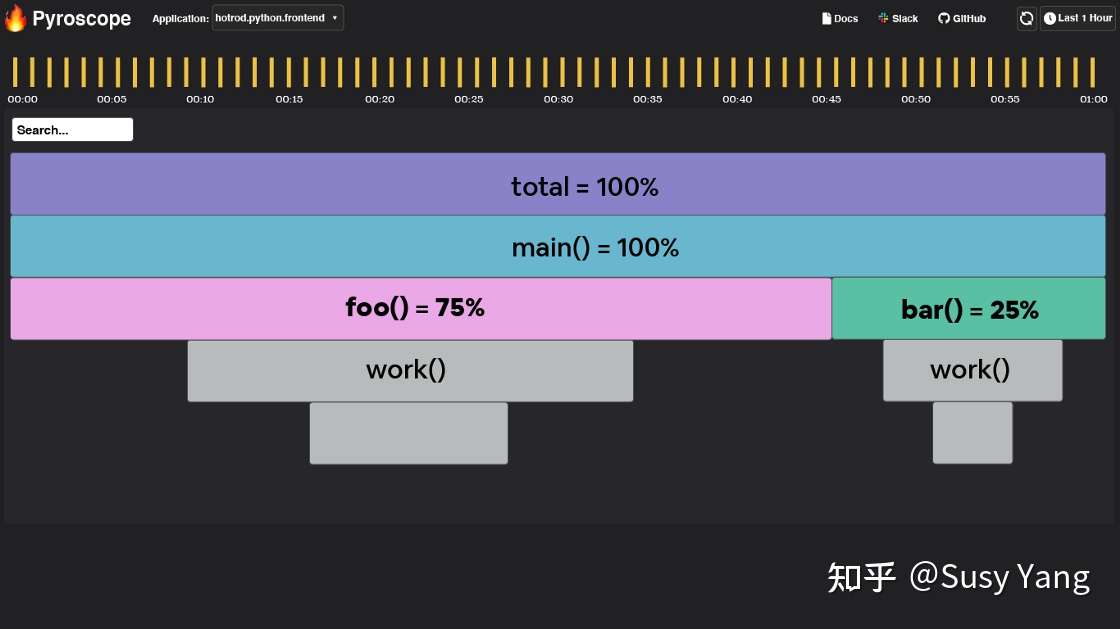
您可把火焰图视为超详细的饼图,其中:
- 火焰图的宽度代表着整个时段
- 每个节点代表一个功能
- 最大的节点占用了大部分中央处理器资源
- 每个节点被其上方的节点调用
在这种情况下,’foo()’ 占据了整时间范围的75%,因此我们可以改进`foo()`及其调用的函数来减少中央处理器的利用率(并节省$$)。
用Pyroscope工具创建火焰图和表格
为了用代码重现上文的例子,我们将使用Pyroscope工具 — 专门针对性能调试问题提供持续的性能分析,并且是开源。
为了模拟服务器,我写了 ’work(duration)’ 函数,该函数在该持续时间段内模拟工作。这样,我们就可以通过下述代码构建火焰图,来复现’foo()’ 所用的75%时间和 ‘bar()’ 所用的25%时间:

# 模拟每次迭代中央处理器的时间
def work(n):
i = 0
while i < n:
i += 1
# 模拟中央处理器运行7.5秒
def foo():
work(75000)
# 模拟中央处理器运行2.5秒
def bar():
work(25000)