python 如何将CSV表格中相同的两行内容合并在一起,并为其加上数字统计?

我尝试过的代码
import pandas as pd
data_cvs = pd.read_csv("tt.csv", engine='python',header=None,skiprows=1)
data_list = []
for item in zip(data_cvs[0], data_cvs[1]):
data_list.append((item [0],item [1],1)) # 增加一列 全为 1 ,用于表示已读取过的行
listtt = data_list
ListTT = []
for tt in range (len(listtt)):
vv = 1
for tt1 in range (len(listtt)):
if listtt[tt][0] == listtt[tt1][0] and listtt[tt][1] == listtt[tt1][1] and tt != tt1 and listtt[tt][2] !=0: #条件判断 判断前两列对于相同的行,跳过已经读取过的行
vv += 1
listtt[tt1][2] = 0 #将已经读取过的行 标识码归零
ListTT.append((listtt[tt][0],listtt[tt][1],vv))
CsvFile = pd.DataFrame(ListTT)
CsvFile.to_csv('ListTT.csv', index=False)
但是一直报错 ,没找到原因
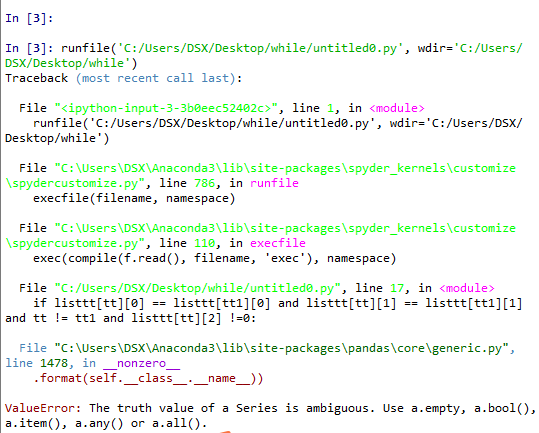
import pandas as pd
data_cvs = pd.read_csv('D://testdata//1.csv',header=None)
print(data_cvs)
data_list = []
for item in zip(data_cvs[0], data_cvs[1]):
data_list.append([item[0], item[1], 1]) # 增加一列 全为 1 ,用于表示已读取过的行
listtt = data_list
ListTT = []
for tt in range(len(listtt)):
if listtt[tt][2] != 0:
listtt[tt][2] = 0
else:
continue
vv = 1
for tt1 in range(len(listtt)):
if listtt[tt][0] == listtt[tt1][0] and listtt[tt][1] == listtt[tt1][1] and tt != tt1 and listtt[tt1][
2] != 0: # 条件判断 判断前两列对于相同的行,跳过已经读取过的行
vv += 1
print(listtt[tt1][2])
print('-------------')
listtt[tt1][2] = 0
ListTT.append((listtt[tt][0], listtt[tt][1], vv))
CsvFile = pd.DataFrame(ListTT)
CsvFile.to_csv('D://testdata//result.csv', index=False)
我帮你改了改 你有几个问题 你这种写法要用列表作为列表的元素 你用元组的话没法修改
而且之后的循环写的有问题 你看看吧