python写sparkstreaming模拟数据流处理得到的wordcount中的word的值都是乱码
最近准备对B站标签做一个流处理,写了以下代码


上面是从log文件夹里面读数据,log文件夹是一个不断生成日志文件的文件夹,相关代码已经写好,只是上面的代码有问题,我通过打印这个record发现得到的key的值都是乱码,不是我想要的中文,我的数据来自以下这张图
可是控制台和写入的文件是这样的: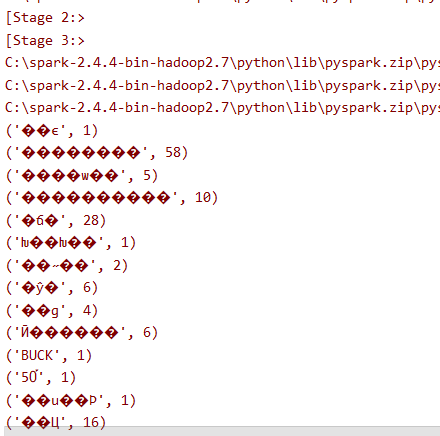

我写了好多种编码的方式,我发现好像从计算word的数量那段代码就开始出错了,不知道为什么。
恳请各位大神指教!!!