yolov5报错RuntimeError: indices should be either on cpu or on the same device as the indexed tensor
楼主最近在学习yolov5,处于刚起步阶段。我们要求使用yolov5的v1.0版本,在使用源代码的train.py的过程中楼主遇到了难以解决的问题,卡了十几个小时没有头绪。楼主用的是2.0.1的pytorch,cuda11.8
报错是这样的:
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
对于源码,楼主几乎没有进行任何的修改,只在yolo.py的大约第126行加了
with torch.no_grad()
实际代码块如下:
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for f, s in zip(m.f, m.stride): # from
mi = self.model[f % m.i]
# mi.to(device=torch.device('cuda:0'))
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
with torch.no_grad():
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
然后运行train.py时报错:
Traceback (most recent call last):
File "C:\Users\ASUS\Desktop\Study\DeepLearning\New Try\New try2\yolov5-1.0\train.py", line 409, in <module>
train(hyp)
File "C:\Users\ASUS\Desktop\Study\DeepLearning\New Try\New try2\yolov5-1.0\train.py", line 266, in train
loss, loss_items = compute_loss(pred, targets.to(device), model)
File "C:\Users\ASUS\Desktop\Study\DeepLearning\New Try\New try2\yolov5-1.0\utils\utils.py", line 423, in compute_loss
tcls, tbox, indices, anchors = build_targets(p, targets, model) # targets
File "C:\Users\ASUS\Desktop\Study\DeepLearning\New Try\New try2\yolov5-1.0\utils\utils.py", line 508, in build_targets
a, t = at[j], t.repeat(na, 1, 1)[j] # filter
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
想请教各位高人怎么办,感谢
这个错误提示表明索引张量 (at) 与被索引的张量 (t.repeat(na, 1, 1)) 不在同一个设备上。解决这个问题,可以将索引张量移到与被索引张量相同的设备上。
在代码中,可以使用以下方法将索引张量 at 移到与 t.repeat(na, 1, 1) 相同的设备上(例如,GPU):
at = at.to(t.device)
请在使用 at 之前添加这一行代码,以确保它们位于相同的设备上。这应该能够解决这个运行时错误。
【相关推荐】
- 这篇博客: 通过yolov5训练自己的模型中遇到的一些问题及解决办法中的 问题六:RuntimeError: All input tensors must be on the same device. Received cpu and cuda:0 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
是耗费我最多时间才得以解决的问题,一定要好好记录!
报错提示:stats = [torch.cat(x, 0).cpu().detach().numpy() for x in zip(*stats)] # to numpy
我的误解:根据报错提示进行思考,是因为Numpy是CPU-only的(在CUDA下训练中的数据不能直接转化为numpy),所以在我们先把GPU tensor张量转换成Numpy数组的时候,需要把GPU tensor转换到CPU tensor去,才导致tensor一会在GPU上跑,一会在CPU上跑。于是我尝试了三种方案:
方案一:numpy数组转化为GPU tensorstats = [torch.from_numpy(torch.cat(x, 0).cpu().detach().numpy()).cuda() for x in zip(*stats)]
运行之后发现还是报原来的错,仍然是在cpu和gpu两个设备上跑。.to(device) 可以指定CPU或GPU;.cuda()只能指定GPU
方案二:尝试寻找一种方法,将GPU tensor转换为Numpy变量时,仍在GPU上跑,不用转换到CPU上去。
Cupy是一个通过利用CUDA GPU库在Nvidia GPU上实现Numpy数组的库
下载安装Cupy库,参考:
https://wenku.baidu.com/view/ff9563f175eeaeaad1f34693daef5ef7ba0d12db.html
方案三:当把GPU tensor转换为CPU tensor此步骤去掉后,我发现还是会报原来的错误。所以推断应该不是torch.cat(x, 0).cpu().numpy()的问题。stats = [torch.cat(x, 0) for x in zip(*stats)]我的猜测:stats问题?
根据报错提示,出错语句在stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)],其中唯一的数据来源就是stats列表,stats列表结构如下:
①stats列表中包含很多个元组类型数据;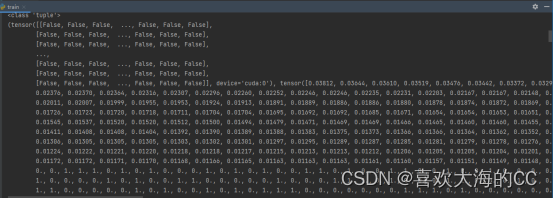
②每个元组中包含几个tensor张量;
用tensor.is_cuda判断其中每个tensor是否在GPU上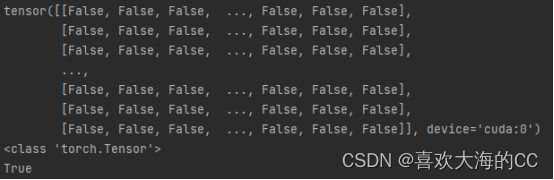



终于,发现问题所在,其中有几个tensor(tensor([]))是在CPU上,且通过判断这些tensor都不为空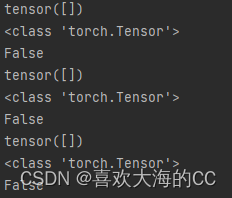
解决办法:将在CPU上的tensor都转移到GPU上
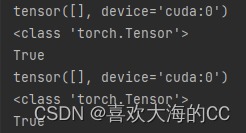
写了一段代码,保证能够将CPU上的tensor转移到GPU上,代码如下:# 把在CPU上的tensor转移到GPU上,使用range在for循环中修改list值 for i in range(len(stats)): stats[i] = list(stats[i]) # 修改元组中的元素:遵循”元组不可变,列表可变“,因此将元组转化为列表再进行修改 for j in range(len(stats[i])): if stats[i][j].is_cuda == False: stats[i][j] = stats[i][j].cuda() # print(stats[i][j].is_cuda) stats[i] = tuple(stats[i])验证:成功将CPU上的tensor转移到GPU上
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^