进行MySQL安装时遇到的问题

用户名错误,无法进行后续操作,无法正常安装,需找到解决方法,继续进行配置
这里填的是mysql的服务名,不能重复,可能已经有同名服务了。
【相关推荐】
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7542918
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:关于安装mysql时出现安装错误之后的万能解决方案(目前解决了本人安装时的各种问题和同学的问题)
- 您还可以看一下 陈贺群老师的软件测试教程系列之MySQL数据库教学视频(中)课程中的 数据库_当前系统时间添加到表中的介绍和列值查询介绍小节, 巩固相关知识点
- 除此之外, 这篇博客: 一文整理14道MySQL索引相关面试题中的 聚集索引相对于非聚集索引的区别? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
聚集索引介绍聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分,每张表只能拥有一个聚簇索引。
- 如果表设置了主键,则主键就是聚簇索引
- 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引
- 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引
聚集索引的叶子节点就是整张表的行记录。InnoDB 主键使用的是聚簇索引。聚集索引要比非聚集索引查询效率高很多。
非聚集索引介绍普通索引也叫二级索引,除聚簇索引外的索引,即非聚簇索引。
InnoDB的普通索引叶子节点存储的是
主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。示例
create table user( id int(10) auto_increment, name varchar(30), age tinyint(4), primary key (id), index idx_age (age) )engine=innodb charset=utf8mb4;id 字段是聚簇索引,age 字段是普通索引(二级索引)
填充数据
insert into user(name,age) values('张三',30); insert into user(name,age) values('李四',20); insert into user(name,age) values('王五',40); insert into user(name,age) values('赵六',10); insert into user(name,age) values('田七',20); mysql> select * from user; +----+--------+------+ | id | name | age | +----+--------+------+ | 1 | 张三 | 30 | | 2 | 李四 | 20 | | 3 | 王五 | 40 | | 4 | 赵六 | 10 | | 5 | 田七 | 20 | +----+--------+------+聚簇索引存储结构id 是主键,所以是聚簇索引,其叶子节点存储的是对应行记录的数据
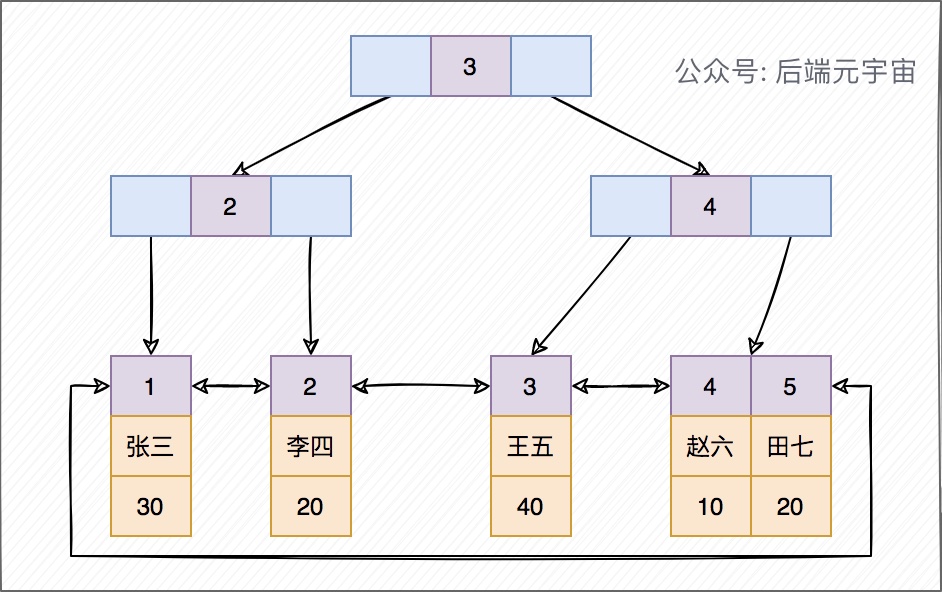
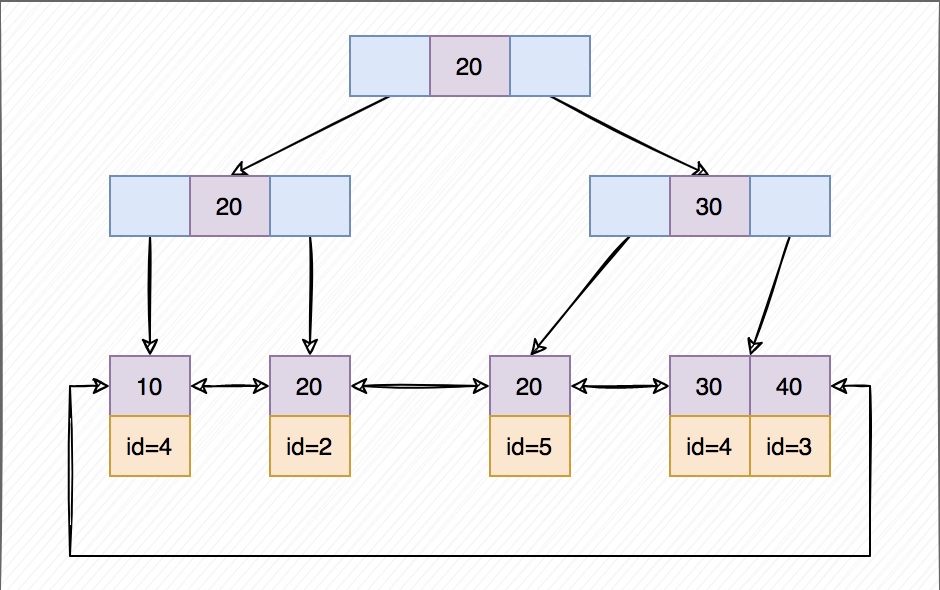
非聚簇索引存储结构age 是普通索引(二级索引),非聚簇索引,其叶子节点存储的是聚簇索引的的值
聚簇索引查询
如果查询条件为主键(聚簇索引),则只需扫描一次B+树即可通过聚簇索引定位到要查找的行记录数据。
如:select * from user where id = 3;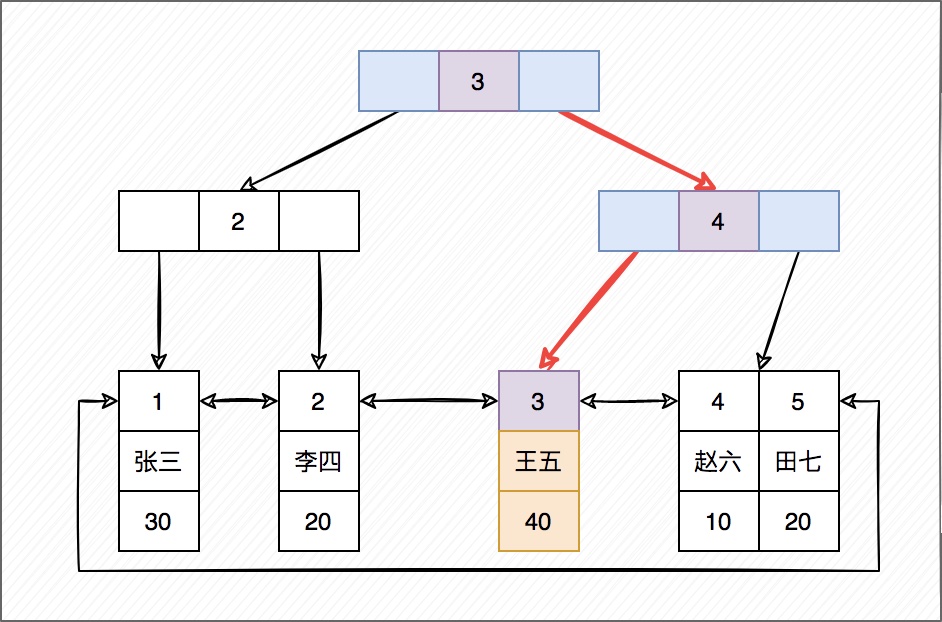
非聚簇索引查询如果查询条件为普通索引(非聚簇索引),需要扫描两次B+树,第一次扫描通过普通索引定位到聚簇索引的值,然后第二次扫描通过聚簇索引的值定位到要查找的行记录数据。
如:select * from user where age = 40;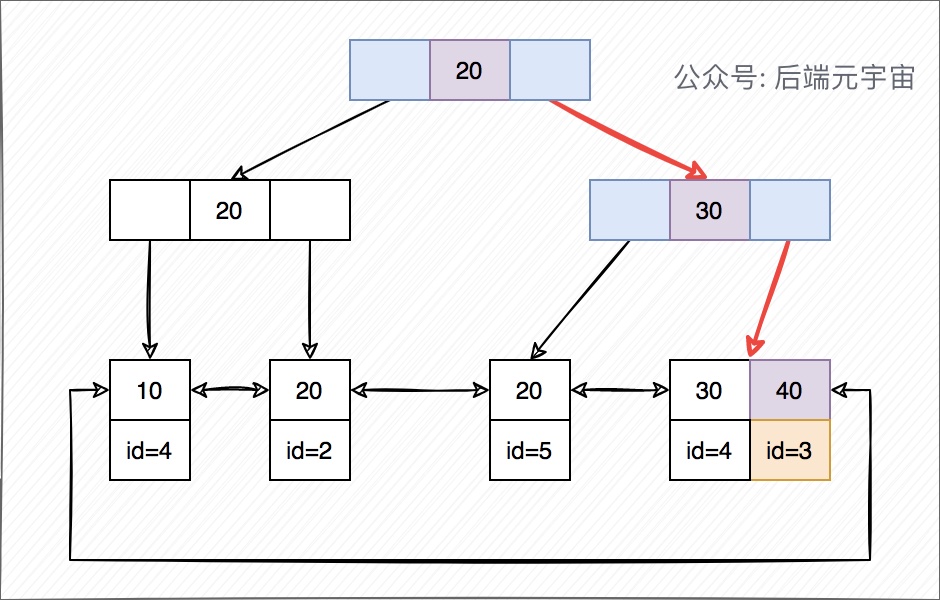
- 先通过普通索引 age=40 定位到主键值 id=3
- 再通过聚集索引 id=3 定位到行记录数据(就是上面这一步)
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^