这些怎么弄啊 实在是不会啊
Hadoop平台部署与维护 使用Java API上传文件
Linux服务器 samba 服务的部署及测试
大数据分析 Spark Spark集群部署及测试
引用 皆我百晓生 小程序回复内容作答:
如果你不熟悉这些技术和操作系统,可以按照以下步骤来学习和掌握它们:
先学习并了解这些技术和操作系统的基础知识。可以通过查阅相关的书籍、教程或在线教育平台上的课程来学习。了解它们的特点、功能和用途。
安装学习环境。根据你的需求和情况,选择合适的版本和安装方式来安装这些技术和操作系统。建议先在本地电脑或虚拟机上安装和配置,进行学习和测试。
跟着教程或指南进行实践和练习。选择一个合适的教程或指南来跟着做实际的操作和练习,逐步掌握相关的操作和功能。可以通过网络搜索相关的教程或查阅官方文档来找到适合自己的学习资源。
加强练习和实践。通过解决问题、编写代码或实际应用来加强自己的掌握程度。可以尝试自己搭建一个小规模的实验环境,进行更复杂的操作和应用场景的练习。
寻求帮助和交流。如果遇到问题或困惑,可以通过向论坛、社区或专业的技术人员寻求帮助。参与相关的讨论和交流,借助他人的经验和解决方案来解决自己的问题。
总之,通过不断学习和实践,逐步掌握这些技术和操作系统是实现的最佳方法。
Hadoop是一个分布式计算框架,用于处理和分析大规模数据集。要使用Java API上传文件到Hadoop平台,您需要使用Hadoop的Java API提供的类和方法。
以下是一个简单的示例代码,演示如何使用Java API上传文件到Hadoop分布式文件系统(HDFS):
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HadoopFileUpload {
public static void main(String[] args) throws Exception {
// 1. 配置Hadoop环境
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
// 2. 创建FileSystem对象
FileSystem fs = FileSystem.get(conf);
// 3. 上传文件
String localFilePath = "/path/to/local/file";
String hdfsFilePath = "/path/to/hdfs/file";
File localFile = new File(localFilePath);
FSDataOutputStream out = fs.create(new Path(hdfsFilePath));
try (InputStream in = new BufferedInputStream(new FileInputStream(localFile))) {
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = in.read(buffer)) > 0) {
out.write(buffer, 0, bytesRead);
}
}
out.close();
// 4. 关闭FileSystem对象
fs.close();
}
}
在这个示例中,我们首先配置Hadoop环境,指定HDFS的地址。然后,我们创建FileSystem对象,该对象是访问HDFS的入口点。接下来,我们使用FSDataOutputStream类创建一个新的HDFS文件,并使用BufferedInputStream类读取本地文件的内容,然后将其写入HDFS文件。最后,我们关闭FSDataOutputStream和FileSystem对象。
请注意,这只是一个简单的示例代码,实际应用中可能需要更多的错误处理和异常处理。此外,您还需要根据您的实际情况修改代码中的路径和其他参数。
在网上找教程学习呗
【相关推荐】
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7699273
- 这篇博客你也可以参考下:Hadoop2.7与Spark1.6的集群搭建
- 您还可以看一下 石逸凡老师的大数据教程---Hadoop/Spark的技术与实践课程中的 Spark运行结构小节, 巩固相关知识点
- 除此之外, 这篇博客: Ubuntu从零安装 Hadoop And Spark中的 Spark的测试 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
运行的代码

出现一个问题
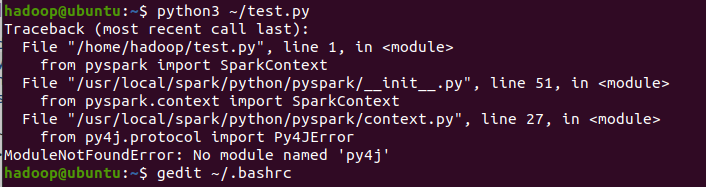
原来是路径写错了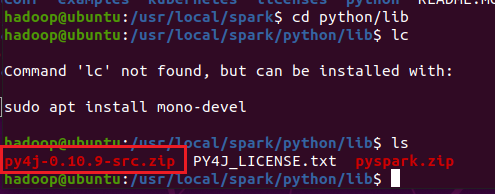



如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
结合GPT给出回答如下请题主参考
- Hadoop平台部署与维护:
步骤1:安装Java和SSH
步骤2:下载Hadoop
步骤3:配置Hadoop
步骤4:启动Hadoop
步骤5:测试Hadoop
步骤6:维护Hadoop
- 使用Java API上传文件Linux服务器:
步骤1:创建一个Java项目
步骤2:使用SSH连接Linux服务器
步骤3:使用Java API上传文件到Linux服务器
- Samba服务的部署及测试:
步骤1:安装Samba
步骤2:配置Samba
步骤3:测试Samba
- 大数据分析Spark:
步骤1:安装Spark
步骤2:配置Spark
步骤3:使用Spark进行大数据分析
- Spark集群部署及测试:
步骤1:准备集群环境
步骤2:安装Spark
步骤3:配置Spark集群
步骤4:测试Spark集群
以上是大致的步骤,具体实现过程需要参考相应的文档和教程,希望能对您有所帮助。
可以在b站找一些视频来看。
跟着视频一个一个的去写,主要是自己要有足够的耐心,慢慢的自己就会了。
具体是要干啥,可以说详细一点吗
Hadoop平台部署与维护以及使用Java API上传文件:
使用HDFS Java API:编写Java代码,使用HDFS Java API连接到Hadoop集群的HDFS(分布式文件系统)。
实现上传逻辑:编写代码来实现文件上传逻辑,包括打开文件、创建输出流、写入数据等。
执行上传:运行Java程序,将文件上传到HDFS中。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HdfsUploader {
public static void main(String[] args) throws Exception {
String hdfsUri = "hdfs://namenode:8020"; // HDFS URI
String localFilePath = "/path/to/local/file.txt";
String hdfsFilePath = "/user/username/file.txt"; // HDFS路径
Configuration conf = new Configuration();
conf.set("fs.defaultFS", hdfsUri);
FileSystem fs = FileSystem.get(conf);
Path srcPath = new Path(localFilePath);
Path destPath = new Path(hdfsFilePath);
fs.copyFromLocalFile(srcPath, destPath);
System.out.println("File uploaded to HDFS.");
}
}
Linux服务器Samba服务的部署与测试:
安装Samba:使用包管理工具安装Samba软件包。
配置Samba:编辑Samba的配置文件,如smb.conf,设置共享目录、用户权限等。
创建Samba用户:使用sudo smbpasswd -a username命令创建Samba用户密码。
大数据分析Spark和Spark集群部署与测试:
安装Spark:下载Spark软件包并解压。
编写Spark应用:使用Scala、Java或Python编写Spark应用,构建数据处理流程。
运行应用:使用spark-submit命令提交Spark应用,将其运行在本地或集群模式下。
Spark集群部署与测试:
设置集群环境:安装和配置Hadoop集群(如果尚未设置),确保所有节点可以访问Spark。
配置Spark集群:编辑Spark的配置文件,如spark-env.sh、spark-defaults.conf,配置集群参数。
启动集群:启动Spark集群的主节点(Master)和工作节点(Workers)。
提交应用:使用spark-submit命令提交应用到Spark集群,观察应用的执行情况。
把这几个服务搭起来就可以了呀。
帮你找了几篇,可以试试
Hadoop——HDFS文件系统的Java API操作(上传、下载、查看、删除、创建文件)详细教学
参考结合AI智能、文心一言,如对您有帮助,恭请采纳。
- Hadoop平台部署与维护 - 使用Java API上传文件
首先需要安装Hadoop并配置环境变量,以便在终端中使用Hadoop命令。
接下来,可以使用Java API上传文件到Hadoop文件系统。
以下是一个示例代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HadoopFileUploader {
public static void main(String[] args) throws IOException, URISyntaxException {
String localFilePath = "/path/to/local/file";
String hdfsFilePath = "/path/to/hdfs/file";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf);
Path localPath = new Path(localFilePath);
Path hdfsPath = new Path(hdfsFilePath);
fs.copyFromLocalFile(localPath, hdfsPath);
System.out.println("File uploaded successfully!");
}
}
- Linux服务器samba服务的部署及测试
Samba是一个开源的网络共享协议,可以在Linux服务器上部署Samba服务以便在Windows系统上访问Linux服务器上的文件共享。
以下是Samba服务的安装和配置步骤:
- 安装Samba服务:
sudo apt-get update
sudo apt-get install samba
- 创建共享目录:
sudo mkdir /path/to/shared/directory
sudo chmod 777 /path/to/shared/directory
- 配置Samba服务:
sudo vi /etc/samba/smb.conf
在文件末尾添加以下配置信息:
[shared_directory]
comment = Shared directory
path = /path/to/shared/directory
browseable = yes
writeable = yes
guest ok = yes
create mode = 0666
directory mode = 0777
- 创建Samba用户:
sudo smbpasswd -a username
- 重启Samba服务:
sudo service smbd restart
现在可以在Windows系统上访问Linux服务器上的共享目录。
- 大数据分析Spark - Spark集群部署及测试,分别用代码实现
以下是Spark集群部署和测试的步骤:
安装和配置Java和Scala环境变量。
下载和解压Spark:
wget https://downloads.apache.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgz
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz
- 配置Spark集群:
cd spark-3.0.1-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
在文件末尾添加以下配置信息:
export SPARK_MASTER_HOST=<master_node_hostname>
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=2g
- 启动Spark集群:
在Master节点上运行以下命令:
./sbin/start-master.sh
在Worker节点上运行以下命令:
./sbin/start-worker.sh spark://<master_node_hostname>:7077
- 编写Spark应用程序:
以下是一个简单的Spark应用程序示例,可在Spark集群上运行:
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("Simple Application").getOrCreate()
val logData = spark.read.textFile(args(0)).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
spark.stop()
}
}
- 提交Spark应用程序:
在Master节点上运行以下命令:
./bin/spark-submit --class SimpleApp --master spark://<master_node_hostname>:7077 /path/to/jar-file.jar /path/to/input-file.txt
这将在Spark集群上运行SimpleApp应用程序,统计输入文件中包含字母"a"和"b"的行数并输出结果。
这是一些大数据分析的基本步骤,可以根据实际需求进行调整和修改。
部署Hadoop需要以下步骤:
在服务器上安装Java环境。
下载并解压Hadoop软件包。
配置文件 core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。
格式化HDFS。
启动Hadoop。
维护Hadoop主要是监控和维护HDFS和YARN,保证其正常运行。
使用Java API上传文件到Hadoop:
可以使用Hadoop的分布式文件系统(HDFS)API进行文件上传。
这个,网上代码一大把,找找
Linux服务器Samba服务的部署和测试:
部署Samba服务需要在Linux服务器上安装Samba软件包,并配置Samba共享目录。
Spark集群部署及测试:
Spark可以在多种集群管理器(包括 standalone、Mesos、YARN、Kubernetes等)上运行。以standalone集群为例,需要先下载并解压Spark软件包,配置Spark master和worker的配置文件。然后启动Spark standalone manager和Spark worker,启动Spark shell或者提交Spark job进行测试。同时,也需要监控Spark的运行状态,以保证其正常运行。
参考gpt
对于Hadoop平台部署与维护,使用Java API上传文件,Linux服务器samba服务的部署及测试,以及大数据分析Spark集群部署及测试等方面的需求,涉及到比较复杂的技术和操作步骤,无法在此简单地一一介绍和解答。这些需求需要具备一定的技术背景和经验,并且需要详细的操作步骤和环境配置。
建议您可以参考相关的官方文档、教程或者书籍,以获得更详细的指导。以下是一些学习资源的推荐:
- Hadoop官方文档:https://hadoop.apache.org/documentation/
- Spark官方文档:https://spark.apache.org/documentation.html
- Linux命令大全:https://man.linuxde.net/
- Linux服务器搭建Samba服务:https://www.linuxidc.com/Linux/2018-10/154318.htm
此外,您还可以考虑参加相关的培训课程或者咨询专业的技术人员,以获得更系统和专业的指导。
先学习一下技术文档,然后按照案例来操作
你需要的是更具体一点的步骤,我建议你加班看看一些详细步骤,其实看一下就会了,不要怕,要多去尝试,都是固定操作
具体要做什么呢,可以先学习学习文档