爬东方财富网遇到的ip代理问题
爬东方财富网遇到的ip代理问题
我使用快代理的限时6小时的免费ip去代理请求爬虫
我测试过先对
进行访问,返回的ip信息确实是代理ip,而非本地ip。
但是随后对东方财富网进行爬虫,没过一会还是被封了,封的还是我的本地ip,然后我继续用代理ip请求返回的结果又是变成了403。
它到底是怎么获取到我的本地ip的?
这是一段重点代码:
import random
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
response = requests.get(
'快代理的api链接',
headers=headers, timeout=1) #
if response.status_code == 200:
pp = response.text.split('\r\n')
www = random.choice(pp)
req2 = requests.get('https://caifuhao.eastmoney.com/news/20230827185253791253180',
headers=headers, proxies={'http': 'http://'+www})
ipconfig = requests.get('http://icanhazip.com/',
headers=headers, proxies={'http': 'http://'+www})
print(pp)
print(www)
print(ipconfig.status_code,ipconfig.text)
print(req2)
【相关推荐】
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7403982
- 你也可以参考下这篇文章:IP划分子网的实训案例:某单位申请了一个IP为218.197.17.0,该单位需要建设四个网络,分别用于管理四个部门,要求分配各主机数量相同,试对该单位进行规划并配置。
- 您还可以看一下 张先凤老师的《计算机体系结构—网络篇3、4》之IP分类与组成、网络标识、子网掩码、私网组建等课程中的 计算网段所允许分配的ip数量小节, 巩固相关知识点
- 除此之外, 这篇博客: 【爬虫】IP代理池的总结、实现与维护,IP代理池小工具(小框架),自建代理ip池中的 使用教程 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
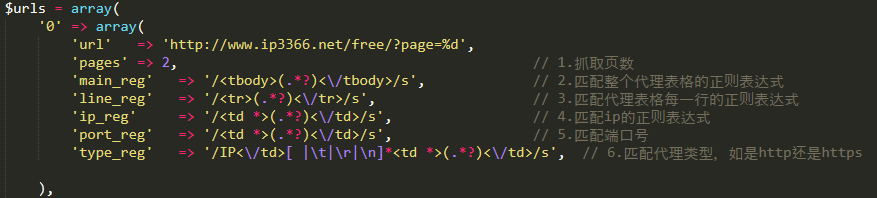
此处以某网站为例,如图,需配置网站的地址、抓取的页数,然后再配置需抓取内容的正则表达式:
下面举例解释一下如何分析出正则表达式:
如上图,可看到该代理网站的免费代理是一个表格,我们在网页上点击鼠标右键,选择“查看网页源代码”,然后就可以到下图的源码:
很明显的可以看出,整个表格的内容是由<tbody> </tbody>标签包裹着的,每行代理数据是由<tr> </tr>标签包裹着的,而每一列数据是由<td > </td>包裹着的,于是可以写出如下正则表达式:
如果没学过正则表达式,建议先去看一下正则表达式的基本语法(很快就能学会)。ip_reg和port_reg可以设置成一样,因为ip之后的下一列肯定是端口号port,再匹配完ip之后,将ip那一部分截取掉,再匹配端口号,这样就比较方便。而代理类型所在列是不固定的,所以我们不能使用与端口号一样的处理方式。
先分析源码,发现代理类型所在列都是在'代理IP</td>'这个字符串之后的,所以可以将代理类型的匹配正则表达式写成/IP<\/td>[ |\t|\r|\n]*<td *>(.*?)<\/td>/s配置好之后就可以直接运行该代理池小工具了,直接运行 " operateProxyPool.php " 这个文件就行。
程序运行结束之后,文件夹下会生成一个“proxyPool.dat”文件,该文件就是代理池。
当然,作为代理池肯定需要持续更新的,所以你可以根据需要改进本工具的代码,让其一直运行,不断更新“proxyPool.dat”里的数据。还有一点是如果需要提高更新效率,可以将改成多线程模式。个人认为当前的更新效率已经足够大多数人使用了。
附上抓取两个网站的例子:
每个网站都是一页15个代理,我们各抓两页,结果应该会抓取到60个代理数据


配置如下:
抓取结果如下:
使用格式化工具格式化之后:

可以看到刚好60个,说明抓取代理数据成功,没有漏掉。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
东方财富不需要ip代理,没有任何限制的。看看我写的软件,你就知道该怎么爬取东方了