python代码下标问题
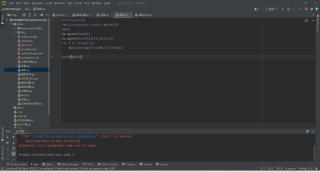

这个取数问题的思路我过了一遍是没有问题的但是这个代码输出之后一直报错下标越界但是我一直看不出来哪里出问题了请大家帮忙看看
很明显的一个内存未分配问题。
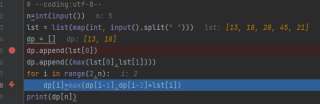
报错位置在for循环中,此时你的dp数组只有两个数,下标范围为[0, 1],而i的值为2,所以dp[i]报错。
解决办法1:
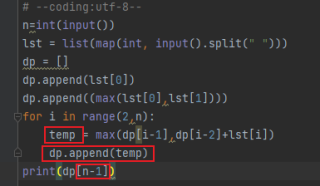
先计算得出要保存的值,再append入列表中。
解决办法2:
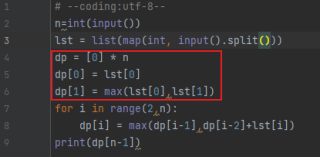
预分配空间,dp数组最终的总长度确定为n,所以是可以预分配的。
此外,因为dp列表下标从0开始分配的,最终结果应为dp[n-1]。
dp最初只有两个数,dp[2]能不越界吗
跟你的输入有关系,如果第二次的输入生成的数组长度为1就会报错。
dp[i] = max(dp[i-1], dp[i-2]+lst[i])
当i < len(dp)时,dp[i]的值会被修改。
当i>=len(dp)时,会报错。
【相关推荐】
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7765078
- 这篇博客你也可以参考下:python类小练习:请输入一周中某天的名称的第一个英文字母来判断一下是星期几,如果第一个字母一样,则继续判断第二个字母
- 你还可以看下python参考手册中的 python- 定义扩展类型:已分类主题- 终结和内存释放
- 您还可以看一下 jeevan老师的Python量化交易,大操手量化投资系列课程之内功修炼篇课程中的 讲师简介,量化交易介绍及自动化交易演示小节, 巩固相关知识点
- 除此之外, 这篇博客: python简单实现抓取英雄联盟皮肤原画:老玩家都哭了!中的 其实这个程序到这里已经完成了,但是知识无极限,我还利用了空闲时间,让它实现了其他功能,现在附上全部代码: 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
# 编号 英雄 列表 url=https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js import requests import os from PIL import Image import time def getjosn(): url0="https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js" try: r=requests.get(url0) r.raise_for_status() r.encoding=r.apparent_encoding herolist=r.json() #转换为josn格式 except: print("爬取失败:") print(herolist) herolists=herolist["hero"] #获得hero对应的字典类型 heronumber=list(map(lambda x:x["heroId"],herolists)) #获得英雄的编号列表 heroname=list(map(lambda x:x["name"],herolists)) #获得英雄的名称列表 return heroname,heronumber def strs(k): if k>=0 and k<10: return "00"+str(k) else: return "0"+str(k) def down(): name,number=getjosn() #获得name 和 编号 第一个黑暗之女 001 第二个狂战士 002 i=0 #计数 if not os.path.exists("D://英雄联盟壁纸//"): #判断英雄联盟壁纸这个目录是否存在 os.mkdir("D://英雄联盟壁纸//") #创建这个目录 for j in number: #遍历每个编号 if not os.path.exists("D://英雄联盟壁纸//"+name[i]): #判断这个英雄文件夹是否存在 os.mkdir("D://英雄联盟壁纸//"+name[i]) #创建这个英雄文件夹 os.chdir("D://英雄联盟壁纸//"+name[i]) #进入这个文件夹 i+=1 for k in range(20): #假设有20个皮肤 path="https://game.gtimg.cn/images/lol/act/img/skin/big"+str(j)+str(strs(k))+".jpg" print(path) rr=requests.get(path) if rr.status_code==200: #请求正常 with open(str(k)+".jpg","wb") as f: #写入文件 f.write(rr.content) f.close() print("{}的原壁纸已经下载了{}张\r".format(name[i-1],k)) def look(): hero=input("欢迎查询英雄皮肤,请选择你要查询的英雄:") m="D://英雄联盟壁纸//"+str(hero) if not os.path.exists(m): #判断改英雄皮肤是否已经下载 ys=input("很抱歉,这个英雄的壁纸暂时未下载,是否调入下载功能yes/no:") if ys=="yes": print("正在全部下载中:") down() else: print("请重新输入英雄:") look() for i in range(20): #查看此英雄的所有皮肤壁画 image=Image.open(m+"//"+str(i)+".jpg") image.show() time.sleep(1) def main(): print("该程序已经下载了部分英雄原壁纸(下载全部壁纸耗时且占用内存)") n=input("1、继续下载:/2、选择浏览:") if n=="1": down() else: look() main()这是大学生活中第一次写这个博客,好多东西不咋会,别喷我。对于这个代码来说,美中不足的是,我还没找到如何实现下载指定英雄的办法,这也是一个败笔 ,阅读代码如果有问题,或者有错误的话欢迎留言。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
你试试,看看能否解决你的问题:
在赋值之前,先将dp列表扩展到n的长度。可以使用dp.extend([0]*(n-len(dp)))来实现。
修改后的代码:
n = int(input())
lst = list(map(int, input().split()))
dp = []
dp.append(lst[0])
dp.append((max(lst[0], lst[1])))
dp.extend([0]*(n-len(dp)))
for i in range(2, n):
dp[i] = max(dp[i-1], dp[i-2] + lst[i])
print(dp[n-1])
# 编号 英雄 列表 url=https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js
import requests
import os
from PIL import Image
import time
def getjosn():
url0="https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js"
try:
r=requests.get(url0)
r.raise_for_status()
r.encoding=r.apparent_encoding
herolist=r.json() #转换为josn格式
except:
print("爬取失败:")
print(herolist)
herolists=herolist["hero"] #获得hero对应的字典类型
heronumber=list(map(lambda x:x["heroId"],herolists)) #获得英雄的编号列表
heroname=list(map(lambda x:x["name"],herolists)) #获得英雄的名称列表
return heroname,heronumber
def strs(k):
if k>=0 and k<10:
return "00"+str(k)
else:
return "0"+str(k)
def down():
name,number=getjosn() #获得name 和 编号 第一个黑暗之女 001 第二个狂战士 002
i=0 #计数
if not os.path.exists("D://英雄联盟壁纸//"): #判断英雄联盟壁纸这个目录是否存在
os.mkdir("D://英雄联盟壁纸//") #创建这个目录
for j in number: #遍历每个编号
if not os.path.exists("D://英雄联盟壁纸//"+name[i]): #判断这个英雄文件夹是否存在
os.mkdir("D://英雄联盟壁纸//"+name[i]) #创建这个英雄文件夹
os.chdir("D://英雄联盟壁纸//"+name[i]) #进入这个文件夹
i+=1
for k in range(20): #假设有20个皮肤
path="https://game.gtimg.cn/images/lol/act/img/skin/big"+str(j)+str(strs(k))+".jpg"
print(path)
rr=requests.get(path)
if rr.status_code==200: #请求正常
with open(str(k)+".jpg","wb") as f: #写入文件
f.write(rr.content)
f.close()
print("{}的原壁纸已经下载了{}张\r".format(name[i-1],k))
def look():
hero=input("欢迎查询英雄皮肤,请选择你要查询的英雄:")
m="D://英雄联盟壁纸//"+str(hero)
if not os.path.exists(m): #判断改英雄皮肤是否已经下载
ys=input("很抱歉,这个英雄的壁纸暂时未下载,是否调入下载功能yes/no:")
if ys=="yes":
print("正在全部下载中:")
down()
else:
print("请重新输入英雄:")
look()
for i in range(20): #查看此英雄的所有皮肤壁画
image=Image.open(m+"//"+str(i)+".jpg")
image.show()
time.sleep(1)
def main():
print("该程序已经下载了部分英雄原壁纸(下载全部壁纸耗时且占用内存)")
n=input("1、继续下载:/2、选择浏览:")
if n=="1":
down()
else:
look()
main()
问题点:列表取值问题.
分析思路:添加一个判断条件 n 是否大于列表长度
if n <= len(dp):
print(dp[n])
else:
print("n超出dp的列表长度")
print(n, len(dp),dp)

代码
n = int(input())
lst = list(map(int, input().split()))
dp = []
dp.append(lst[0])
dp.append(max(lst[0], lst[1]))
for i in range(2, n):
#dp[i] = max(dp[i-1], dp[i-2] + lst[i])
dp.append(max(dp[i - 1], dp[i - 2] + lst[i]))
print(dp[n-1])
你在循环前用lst的第一项和第二项初始化了列表dp,此时列表dp只有2项,在循环中,调用dp[i]时,i超过了2,所以会报错下标溢出。
解决方法:
n = int(input())
lst = list(map(int, input().split()))
dp = []
dp.append(lst[0])
dp.append(max(lst[0], lst[1]))
for i in range(2, n):
dp.append(max(dp[i-1], dp[i-2] + lst[i]))
print(dp[n-1])
有用就点个采纳吧,谢谢
注意下表越界得问题,-1就可以了
你具体的代码可否贴一下我分析下,具体情况具体分析
索引超出使用,建议使用之前先判断下标对应值是否存在
数组越界了
n修改为n-1就行了