python学习文件操作时发现报错
这是什么字符编码错误啊,改怎么解决呢能够大致讲解一下吗
文件里有几行乱打的文字,格式从docx到txt都不行


【相关推荐】
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7614742
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:使用python从docx中抽取特定段落并保存到txt文档中
- 您还可以看一下 赵帅老师的Python爬虫基础&商业案例实战课程中的 批量生成舆情报告准备知识点:自动生成txt文件小节, 巩固相关知识点
- 除此之外, 这篇博客: python爬虫实战一、爬取酷我音乐榜单并写入txt文件保存到本地中的 一、总代码和运行截图 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
#加载需要的库 import requests from bs4 import BeautifulSoup from lxml import etree f = open("C:\\Users\LeeChoy\Desktop\kuwomusic.txt",'w+',encoding='utf-8') #打开文件 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'} ##从浏览器复制张贴时注意删除agent:后面的空格 responce = requests.get("http://www.kuwo.cn/bang/index",headers=headers) ##为使抓取数据稳定,伪装成浏览器 soup = BeautifulSoup(responce.text,'html.parser') #BeautifulSoup解析网页 html = etree.HTML(responce.text) #XPath解析 #利用选择器获得数据 # 一、获得榜单的名字 names = soup.select( '#chartsContent > div.rightContentBox > ul > li > div.name > a') #二、获取歌曲歌手 singers = soup.select('#chartsContent > div.rightContentBox > ul > li > div.artist > a') #三、获取歌手的热度 xpath解析获得为一个列表 heats = html.xpath('//*[@id="chartsContent"]/div[2]/ul/li/div[4]/div/@style') i=0 #为了写序号以及便于列表输出和储存数据 for name ,singer, heat in zip(names,singers,heats): print((str)(i+1)+" "+name.get_text()+" "+singer.get_text()+" "+heats[i].replace("width:","")) f.write((str)(i + 1) + " " + name.get_text() + " "+singer.get_text() + " "+heats[i].replace("width:","")+'\n') i+=1 f.close() #关闭文件①打印的爬取结果
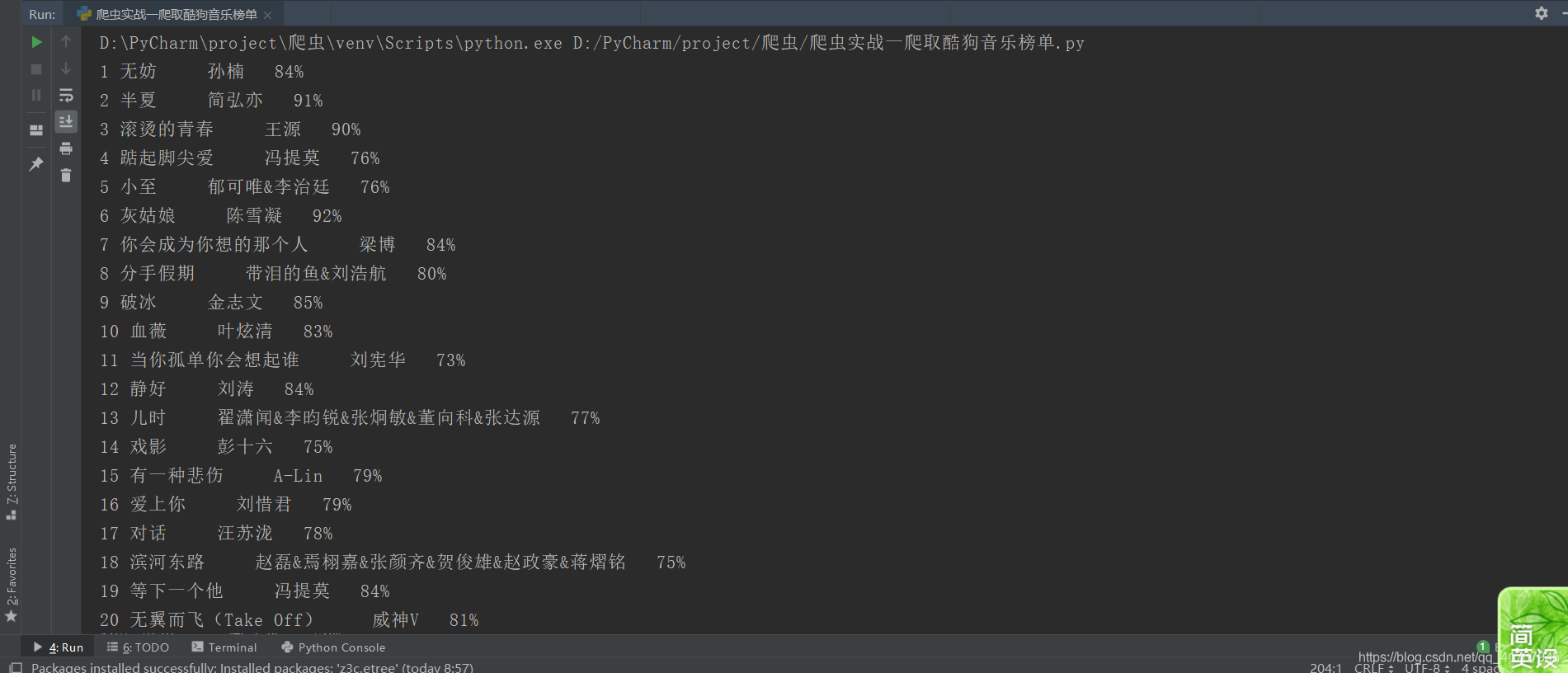
②写入的TXT文件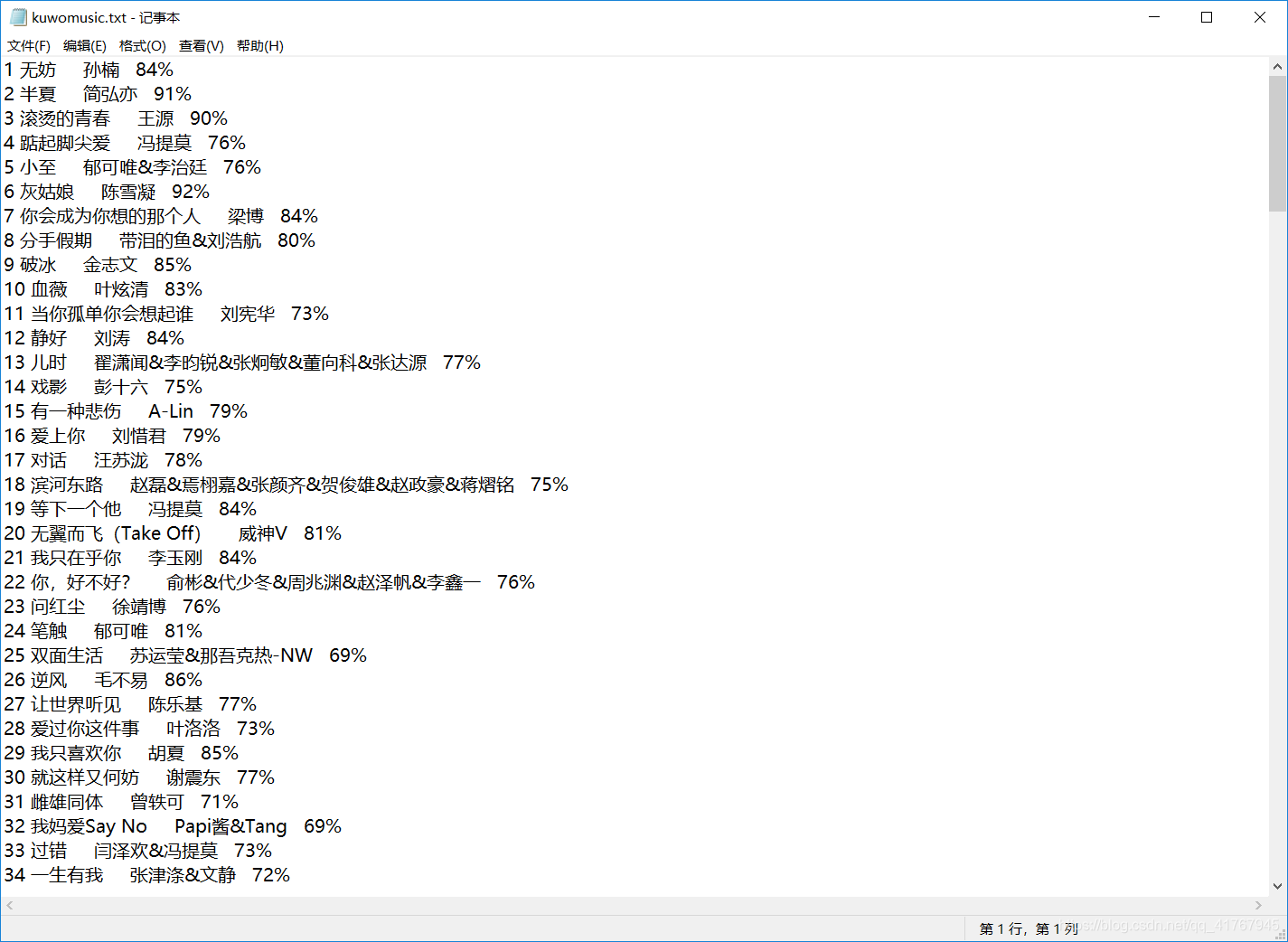
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^