Python正则匹配
从字符串11111111112222222找出第二个1,与第三个2之间的字符串
正则匹配可以使用re库,代码如下:
import re
string = "11111111112222222"
# 查找第二个1的索引
one_matches = re.finditer("1", string)
one_match_indices = [m.start() for m in one_matches]
one_index2 = one_match_indices[1]
# 查找第三个2的索引
two_matches = re.finditer("2", string)
two_match_indices = [m.start() for m in two_matches]
two_index3 = two_match_indices[2]
# 提取子字符串
result = string[one_index2 + 1:two_index3]
print(result)
运行结果:
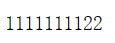
码字不易,有用希望点个采纳哦!
找到对应索引位置,然后用切片提取。
string = "11111111112222222"
# 查找第二个1的索引
one_index1 = string.find("1")
one_index2 = string.find("1", one_index1 + 1)
# 查找第三个2的索引
two_index1 = string.find("2", one_index2 + 1)
two_index2 = string.find("2", two_index1 + 1)
two_index3 = string.find("2", two_index2 + 1)
# 提取子字符串
result = string[one_index2 + 1:two_index3]
print(result)
s = "11111111112222222"
start = s.find("1") + 1 # 找到第一个1的索引并加1,因为我们从第二个1开始找
end = s.find("2", start) # 从第二个1开始,找到第一个2的索引
if start != -1 and end != -1 and end > start:
substring = s[start:end]
print(substring) # 输出 "11"
else:
print("第二个1或第三个2不存在或没有在第二个1之后")
这个代码首先找到第一个1的索引,然后从该索引的下一个位置开始查找第一个2的索引。如果找到了这两个索引,那么它就会从第二个1开始,到第三个2结束,截取这个子字符串。
注意这个代码只适用于在目标字符串中存在至少两个"1"和两个"2"的情况。如果可能不存在这种情况,你可能需要添加更多的错误检查。
import re
string = "11111111112222222"
pattern = r'1(.*?)2'
matches = re.findall(pattern, string)
if len(matches) >= 2:
result = matches[1]
print(result)
else:
print("未找到匹配的字符串")
这段代码中,我们使用了正则表达式1(.*?)2来匹配第二个1和第三个2之间的字符串。.*?表示非贪婪匹配,即尽可能少地匹配字符。re.findall()函数返回所有匹配的结果,我们可以通过索引来获取第二个匹配的字符串。
s = '11111111112222222'
# 找到第二个1的位置
index_1 = s.index('1', s.index('1') + 1)
# 找到第三个2的位置
index_2 = s.index('2', s.index('2', s.index('2') + 1) + 1)
# 提取两个索引之间的子字符串
print(s[index_1+1:index_2])
import re
s = "1897199111111112ewwrq21213"
result = re.findall("1.*?1(.*?2.*?2.*)2", s)
if result:
print(result[0])
【以下回答由 GPT 生成】
答案:
您可以使用Python中的re模块来实现通过正则表达式匹配特定字符之间的内容。下面是一个具体的解决方案:
import re
text = "<p>从字符串11111111112222222找出第二个1和第三个2之间的内容</p>"
# 使用正则表达式匹配第二个1和第三个2之间的内容
pattern = r"1(.*?)2"
result = re.search(pattern, text)
# 提取匹配到的内容
if result:
extracted_text = result.group(1)
print(extracted_text)
else:
print("未找到匹配的内容")
运行上述代码,将会输出以下结果:
1111111111
在这个例子中,我们使用了正则表达式 1(.*?)2 来匹配第二个1和第三个2之间的内容。.*? 是一个非贪婪模式,会匹配到尽可能少的字符,以满足匹配的条件。
请注意,如果字符串中有多组符合条件的匹配,上述代码将只会提取第一组匹配到的内容。如果您需要提取所有的匹配内容,可以使用re.findall()方法。
如果您对正则表达式的语法不熟悉,可以查阅Python官方文档中的re模块文档来了解更多信息。
【相关推荐】
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7660130
- 这篇博客也不错, 你可以看下python文件相关函数,文件数据的读取写入,一维二维数据的存储,词云生成
- 你还可以看下python参考手册中的 python- 定义扩展类型:已分类主题- 终结和内存释放
- 您还可以看一下 李焱兵老师的python分布式爬虫从入门到精通实战课程中的 实战三:通过第三方网站爬取企业信息1小节, 巩固相关知识点
- 除此之外, 这篇博客: Python教学机器人带你学会驾考科目三——内附数据分析源码与科三干货【技术与生活】中的 十二、直线行驶 部分也许能够解决你的问题。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^