Apache Doris实现漏斗分析
之前看了这篇播文DORIS----漏斗转化分析案例实现_咚动咚的博客-CSDN博客,大致了解了如何计算漏斗分析。如果在这个基础上增加关联属性功能,应该如何实现呢?关联属性的意思是指在在转化的过程中都是同一个商品。比如:点击秒杀活动–>参加活动—>参与秒杀–>秒杀成功—>成功支付的都是同一个商品
另外,这篇博文写的计算方式应该是按照人数计算转化率,如果按次数计算该如何改造呢?
@咚动咚 您要有时间帮忙解答下
语法:
window_funnel(window, mode, timestamp_column, event1, event2, ... , eventN)
漏斗分析函数搜索滑动时间窗口内最大的发生的最大事件序列长度。
-- window :滑动时间窗口大小,单位为秒。
-- mode :保留,目前只支持default。-- 相邻两个事件之间没有时间间隔要求,并且相邻两个事件中可以做其他的事件
-- timestamp_column :指定时间列,类型为DATETIME, 滑动窗口沿着此列工作。
-- eventN :表示事件的布尔表达式。
select
user_id,
window_funnel(3600*24, 'default', event_time, event_id='e1', event_id='e2' , event_id='e4', event_id='e5') as step
from event_info_log
group by user_id
+---------+------+
| user_id | step |
+---------+------+
| u006 | 4 |
| u007 | 2 |
| u005 | 3 |
| u004 | 3 |
| u010 | 0 |
| u001 | 3 |
| u003 | 2 |
| u002 | 3 |
| u008 | 3 |
| u009 | 2 |
+---------+------+
-- 算每一层级的转换率
select
'购买转化漏斗' as funnel_name,
sum(if(step >= 1 ,1,0)) as step1,
sum(if(step >= 2 ,1,0)) as step2,
sum(if(step >= 3 ,1,0)) as step3,
sum(if(step >= 4 ,1,0)) as step4,
round(sum(if(step >= 2 ,1,0))/sum(if(step >= 1 ,1,0)),2) as 'step1->step2_radio',
round(sum(if(step >= 3 ,1,0))/sum(if(step >= 2 ,1,0)),2) as 'step2->step3_radio',
round(sum(if(step >= 4 ,1,0))/sum(if(step >= 3 ,1,0)),2) as 'step3->step4_radio'
from
(
select
user_id,
window_funnel(3600*24, 'default', report_date, event_id='e1', event_id='e2' , event_id='e4', event_id='e5') as step
from event_info_log
where to_date(report_date) = '2022-11-01'
and event_id in('e1','e4','e5','e2')
group by user_id
) as t1
-- res
+--------------------+-------+-------+-------+-------+--------------------+--------------------+--------------------+
| funnel_name | step1 | step2 | step3 | step4 | step1->step2_radio | step2->step3_radio | step3->step4_radio |
+--------------------+-------+-------+-------+-------+--------------------+--------------------+--------------------+
| 购买转化漏斗 | 9 | 9 | 6 | 1 | 1 | 0.67 | 0.17 |
+--------------------+-------+-------+-------+-------+--------------------+--------------------+--------------------+
所有回答麻烦请基于此SQL进行回复,不要复制粘贴概念理论
按照次数来统计的话,可供参考
SELECT
user_id,
count(CASE WHEN event_id='e1' THEN 1 END) as step_1_count,
count(CASE WHEN event_id='e2' THEN 1 END) as step_2_count,
count(CASE WHEN event_id='e4' THEN 1 END) as step_3_count,
count(CASE WHEN event_id='e5' THEN 1 END) as step_4_count,
window_funnel(3600 * 24, 'default', event_time, event_id='e2', before_event_id='e1') as step_2_conversion,
window_funnel(3600 * 24, 'default', event_time, event_id='e4', before_event_id='e2') as step_3_conversion,
window_funnel(3600 * 24, 'default', event_time, event_id='e5', before_event_id='e4') as step_4_conversion
FROM
event_info_log
GROUP BY
user_id;
该问题已经自行解决,分享最终答案给大家
select
d,
sum(if(step >= 1 , 1, 0)) as 启动,
sum(if(step >= 1 , 1, 0) * cnt) as 启动次数,
sum(if(step >= 2 , 1, 0)) as 首页,
sum(if(step >= 2 , 1, 0) * cnt) as 首页次数,
sum(if(step >= 3 , 1, 0)) as 详情,
sum(if(step >= 3 , 1, 0) * cnt) as 详情次数,
sum(if(step >= 4 , 1, 0)) as 下载,
sum(if(step >= 4 , 1, 0) * cnt) as 下载次数,
round(sum(if(step >= 2 , 1, 0))/ sum(if(step >= 1 , 1, 0)), 2) as '启动->首页',
round(sum(if(step >= 3 , 1, 0))/ sum(if(step >= 2 , 1, 0)), 2) as '首页->详情',
round(sum(if(step >= 4 , 1, 0))/ sum(if(step >= 3 , 1, 0)), 2) as '详情->下载'
from
(
select
userid,
count(1) cnt,
to_date(day) as d,
window_funnel(86400,
'default',
day,
event = '启动',
event = '首页',
event = '详情',
event = '下载') as step
from
funnel_test
where
date(day) >= '2023-07-01'
and date(day) <= '2023-07-30'
and (
(event = '启动' )
Or (event = '首页' )
Or (event = '详情' )
Or (event = '下载' )
)
group by
userid, productid, to_date(day)
order by userid, to_date(day)
) as t1
group by d
order by d;
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7642297
- 你也可以参考下这篇文章:计算机三级数据库分析与设计练习题(三)、整性约束按照其约束条件的作用对象可以划分为不同级别、下列SQL语句中定义了一个唯一辅索引的是、论证是否具备数据库应用系统开发所需的人力资源、其中矩形框上方的箭头
- 除此之外, 这篇博客: 数据库语句执行过程理解,存储引擎的学习,字符集的理解,加各种sql数据类型理解介绍加之SQL各种数据查询分析和题目专练中的 六.查询这些基本语法是学的差不多点了,可是需要练习呀,接下来请你按照我给的sql文件进行导入数据库,然后请你根据题目进行练习,练完之后最下面有答案. (数据库就是需要操作,小杰初学者小感受) 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 第一步,导入数据库: 方式,两种:
- 第一种 指定导入:
source xxx/test.sql导入sql文件,sql文件实际上是一个脚本文件,里面有多行SQL语句,通过source命令可以批量执行。 (命令导入)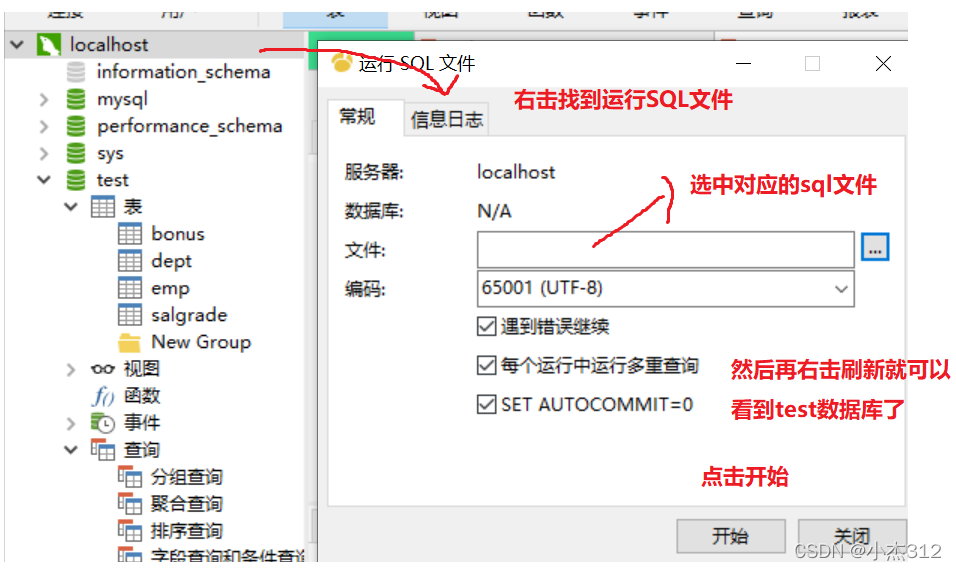
sql 文件代码:
comm SMALLINT ) ; CREATE TABLE IF NOT EXISTS salgrade ( grade INT, losal INT, hisal INT ); -- 插入测试数据 —— dept INSERT INTO dept VALUES (10,'ACCOUNTING','NEW YORK'); INSERT INTO dept VALUES (20,'RESEARCH','DALLAS'); INSERT INTO dept VALUES (30,'SALES','CHICAGO'); INSERT INTO dept VALUES (40,'OPERATIONS','BOSTON'); -- 插入测试数据 —— emp INSERT INTO emp VALUES (7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20); INSERT INTO emp VALUES (7499,'ALLEN','SALESMAN',7698,'1981-2-20',1600,300,30); INSERT INTO emp VALUES (7521,'WARD','SALESMAN',7698,'1981-2-22',1250,500,30); INSERT INTO emp VALUES (7566,'JONES','MANAGER',7839,'1981-4-2',2975,NULL,20); INSERT INTO emp VALUES (7654,'MARTIN','SALESMAN',7698,'1981-9-28',1250,1400,30); INSERT INTO emp VALUES (7698,'BLAKE','MANAGER',7839,'1981-5-1',2850,NULL,30); INSERT INTO emp VALUES (7782,'CLARK','MANAGER',7839,'1981-6-9',2450,NULL,10); INSERT INTO emp VALUES (7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20); INSERT INTO emp VALUES (7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10); INSERT INTO emp VALUES (7844,'TURNER','SALESMAN',7698,'1981-9-8',1500,0,30); INSERT INTO emp VALUES (7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20); INSERT INTO emp VALUES (7900,'JAMES','CLERK',7698,'1981-12-3',950,NULL,30); INSERT INTO emp VALUES (7902,'FORD','ANALYST',7566,'1981-12-3',3000,NULL,20); INSERT INTO emp VALUES (7934,'MILLER','CLERK',7782,'1982-1-23',1300,NULL,10); -- 插入测试数据 —— salgrade INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999);新建一个文件命名为test.sql 将上述拷贝进去,导入执行上述语句创建数据库即可
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
Apache Doris是一种高性能、低延迟、分布式SQL查询引擎,适用于各种复杂的数据分析场景。在业务分析中,漏斗分析是一种经常使用的分析方法,可以帮助企业精确定位业务流程中的瓶颈,从而优化业务流程并提升业务效率。本文将介绍如何利用Apache Doris实现漏斗分析。
- 数据准备
漏斗分析需要准备的是一组有序的事件流,这些事件流通常会记录用户在业务过程中执行的不同步骤。在准备数据时,需要将每个步骤的事件数据收集到一张表中,并确保每个事件都能够被唯一地标识,例如每个事件都有一个唯一的ID。此外,需要在事件表中添加一列来标识事件的顺序,以确保数据是有序的。最终的事件表应该包含以下列:
• ID:唯一的事件ID
• Event:事件名称或类型
• Timestamp:事件发生时间
• User:事件关联的用户ID
• Step:事件在漏斗中的顺序
- 创建漏斗模型
在Apache Doris中创建漏斗模型的步骤如下:
• 创建一个包含所有必要字段的表。该表应包括以下列的定义:
◦ ID:事件标识符
◦ Event:事件名称或类型
◦ Timestamp:事件发生时间
◦ User:事件关联的用户ID
◦ Step:事件在漏斗中的顺序
◦ Result:标识该步骤是否通过漏斗
• 创建漏斗模型,该模型应该包括所有必要的维度和指标。在创建漏斗模型时,需要确保正确地定义漏斗的步骤和排序。
• 在漏斗模型上创建合适的度量,例如通过漏斗的用户数、漏斗的转化率等。
- 编写SQL查询
通过Apache Doris查询漏斗模型来执行漏斗分析。下面是一个漏斗分析的示例查询:
SELECT
step,
COUNT(DISTINCT CASE WHEN result=0 THEN user END) AS drop_off,
COUNT(DISTINCT CASE WHEN result=1 AND step=1 THEN user END) AS step1,
COUNT(DISTINCT CASE WHEN result=1 AND step=2 THEN user END) AS step2,
COUNT(DISTINCT CASE WHEN result=1 AND step=3 THEN user END) AS step3
FROM
funnel_table
GROUP BY
step;
在此查询中,我们使用了不同的聚合函数来统计漏斗的不同步骤的用户数,例如COUNT(DISTINCT CASE WHEN result=0 THEN user END),它将统计在第一步停留的用户数量。通过类似的方式,我们可以计算漏斗的每个步骤的用户数量和转化率。
- 结论
漏斗分析是一种难以避免的业务分析方法,可以帮助企业轻松地发现业务流程中的瓶颈和问题,并对其进行优化。Apache Doris是一个强大的分布式SQL查询引擎,可以支持各种复杂的数据分析场景,包括漏斗分析。通过利用Apache Doris实现漏斗分析,企业可以轻松地收集和分析事件数据,并优化业务流程,从而提高业务效率和准确性。
随着智能手机的普及,移动阅读也变得越来越受欢迎。QQ阅读作为其中的一款阅读软件,在用户中也有着广泛的用户群体。但是,由于QQ阅读的限制,有些用户可能会想要刷机或者强制安装第三方APP。这个问题涉及到许多方面,下面将进行详细探讨。
首先,我们需要明确一点,刷机和强制安装第三方APP都是违反软件使用条款和智能手机操作系统的第一个原则的。因此,我们不建议用户进行这样的行为。刷机和强制安装第三方APP都可能会破坏设备的稳定性、安全性和功能性。如果用户执意要进行这样的操作,那么需要在足够了解相关知识并做好备份的情况下进行操作。
接下来,我们来分析刷机和强制安装第三方APP的两种情况。
一、刷机
刷机是通过更改智能手机的操作系统来实现自己的需求。这意味着你需要将设备的原有操作系统改为其他系统,如更改Android系统为iOS系统、更改iOS系统为安卓系统等。刷机需要具备相关的技术和经验,需要用户了解设备的硬件、操作系统、刷机工具等信息,对于新手来说,这是一项十分复杂的操作。此外,刷机在技术层面上是违反智能手机的使用规定的,因此,刷机后可能会出现诸如设备变砖、系统无法启动、丢失数据等问题。
二、强制安装第三方APP
有些用户在使用QQ阅读时,感觉不够方便,想要通过安装其他APP来进行阅读,但是QQ阅读并不支持这样的操作,因此他们尝试通过强制安装第三方APP来实现。强制安装第三方APP需要用户找到相应的APP,并将其下载到设备上,然后打开设备的设置页面,进入应用管理,找到“安装未知来源的应用程序”并打开该选项,然后选择安装包,进行安装。这种方法比较简单,但是需要注意的是,对于一些不明来源的APP,可能会带来安全方面的风险,因此在安装之前需要仔细确认。
总结来说,刷机和强制安装第三方APP都是涉及到安全与稳定性的问题,对设备有潜在的危害,因此我们不建议用户进行这样的操作。如果用户需要阅读其他书籍,可以尝试下载其他阅读软件,而不是通过刷机或强制安装第三方APP来实现。