爬虫request返回和浏览器元素不一样
python爬虫小学生,这边看了爬数据,然后就实操一下。
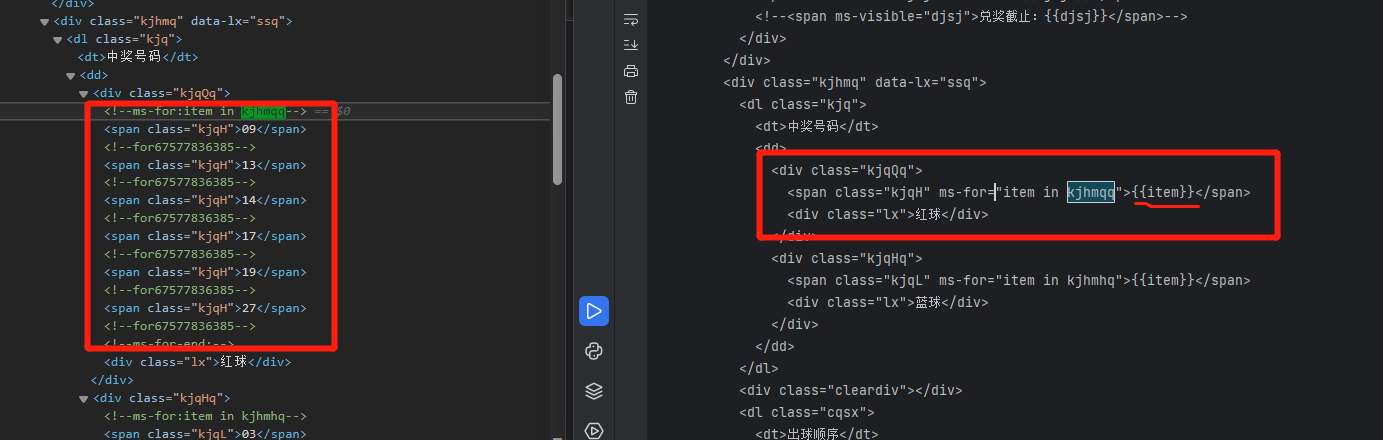
想爬双色球历史期数
地址:https://www.zhcw.com/kjxx/ssq/kjxq/?kjData=2023084
为啥浏览器上的元素和pycharm的request的数据不一样,导致没有办法xpath到红球信息

这边是需要怎么操作捏捏不知道你这个问题是否已经解决, 如果还没有解决的话:
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7662576
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:Python爬虫之批量爬取B站视频封面(内含爬虫概念理解、requests、xpath初级教学及爬虫遇反爬和内容乱码的解决手段)
- 除此之外, 这篇博客: python爬取豆瓣高分书籍信息(request+xpath)中的 看看爬取的数据文件 部分也许能够解决你的问题。
- 以下回答由chatgpt基于相关博客总结生成:
问题截图:问题截图
问题分析: 从截图可以看到,通过浏览器查看的页面元素和使用requests获取的数据不一样。这可能是因为网页使用了JavaScript来动态加载内容,而requests只能获取网页的静态内容。
解决方案: 要解决这个问题,可以使用一个模拟浏览器行为的工具,比如Selenium。Selenium能够启动一个真实的浏览器,模拟用户的操作并获取完整的页面内容。
以下是解决该问题的步骤:
步骤1:安装Selenium库 在PyCharm中,打开终端,并执行以下命令来安装Selenium库:
pip install selenium步骤2:安装浏览器驱动程序 Selenium需要与浏览器进行交互,所以你需要安装相应的浏览器驱动程序。这里以Chrome浏览器为例,你可以根据自己的需要选择其他浏览器。
首先检查你的Chrome浏览器的版本,然后从ChromeDriver官网下载对应版本的驱动程序。下载地址:ChromeDriver下载地址
下载完成后,将驱动程序添加到系统的PATH环境变量中。
步骤3:使用Selenium模拟浏览器操作 在你的Python脚本中,导入Selenium库并创建一个WebDriver对象。然后使用该对象来模拟浏览器的行为,加载页面并获取完整的页面内容。
下面是示例代码:
from selenium import webdriver # 创建一个Chrome浏览器的WebDriver对象 driver = webdriver.Chrome() # 加载页面 url = "https://www.zhcw.com/kjxx/ssq/kjxq/?kjData=2023084" driver.get(url) # 获取完整的页面内容 page_source = driver.page_source # 打印页面内容 print(page_source) # 关闭浏览器 driver.quit()上述代码中,首先导入了
webdriver模块,并创建了一个Chrome浏览器的WebDriver对象。然后使用get()方法加载网页,并使用page_source属性获取了完整的页面内容。最后关闭了浏览器。你可以根据自己的需求对页面进行进一步的处理,比如使用XPath提取所需的红球信息。
注意:使用Selenium需要谨慎使用,避免给服务器带来不必要的负载。在实际的爬虫应用中,可以先尝试使用requests库获取静态页面内容,如果无法获取到所需的数据,则可以考虑使用Selenium进行模拟操作。
希望上述解决方案能对你有所帮助!如果还有其它问题,请随时向我提问。
{kind=link}
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
动态网页
import requests
headers = {
'Referer': 'https://www.zhcw.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}
params = {
'transactionType': '10001002',
'lotteryId': '1',
'issue': '2023084',
'tt': '0.850612582264495',
'_': '1690324560803',
}
response = requests.get('https://jc.zhcw.com/port/client_json.php', params=params,headers=headers).json()

你可以用Selenium来模拟,这个是拟环境爬虫
直接去请求,目标网站可能是动态生成的