关于#python#的问题:嵌套字典变为单层字典
原始字典为
{'param_3': {'or': {'body': {'param4': 'valu_e1', 'p1': 'p2'}}}}
```。进行转换后变为
```python
{'param3': 'request_data.get("body").get("param4")== "valu_e1" or request_data.get("body").get("p1")== "p2"'}
当然or里面可能还会包含and等逻辑关键字。
pre = {
'param3': {
'or': {
'body': {
'param4': 'valu_e1',
'p1': 'p2'
}
}
}
}
result = '{'
for key,value in pre.items():
result += f"'{key}': "
for k,v in value.items():
if k in ["or", "and"]:
body = list(v.keys())[0]
contents = v.get(body)
count, length = 0, len(contents)
result += "'"
for l, r in contents.items():
count += 1
result += f"request_data.get(\"{body}\").get(\"{l}\") == \"{r}\""
if count < length:
result += f" {k} "
result += "'"
result += "}"
print(result)
代码没有经过其它数据测试。
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7801430
- 这篇博客你也可以参考下:Python 如何知道系统默认的编码,并设置系统默认编码 or 编码解码, 以及如何知道系统目录
- 同时,你还可以查看手册:python- 位置或关键字参数 中的内容
- 除此之外, 这篇博客: Python 3.7 实现一个简单爬虫,简单爬数据,抓取数据,一行行代码教程你,总能教会你中的 了解页面结构 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
Google Chrome开发者工具查看,对于 web 开发的同鞋应该不陌生。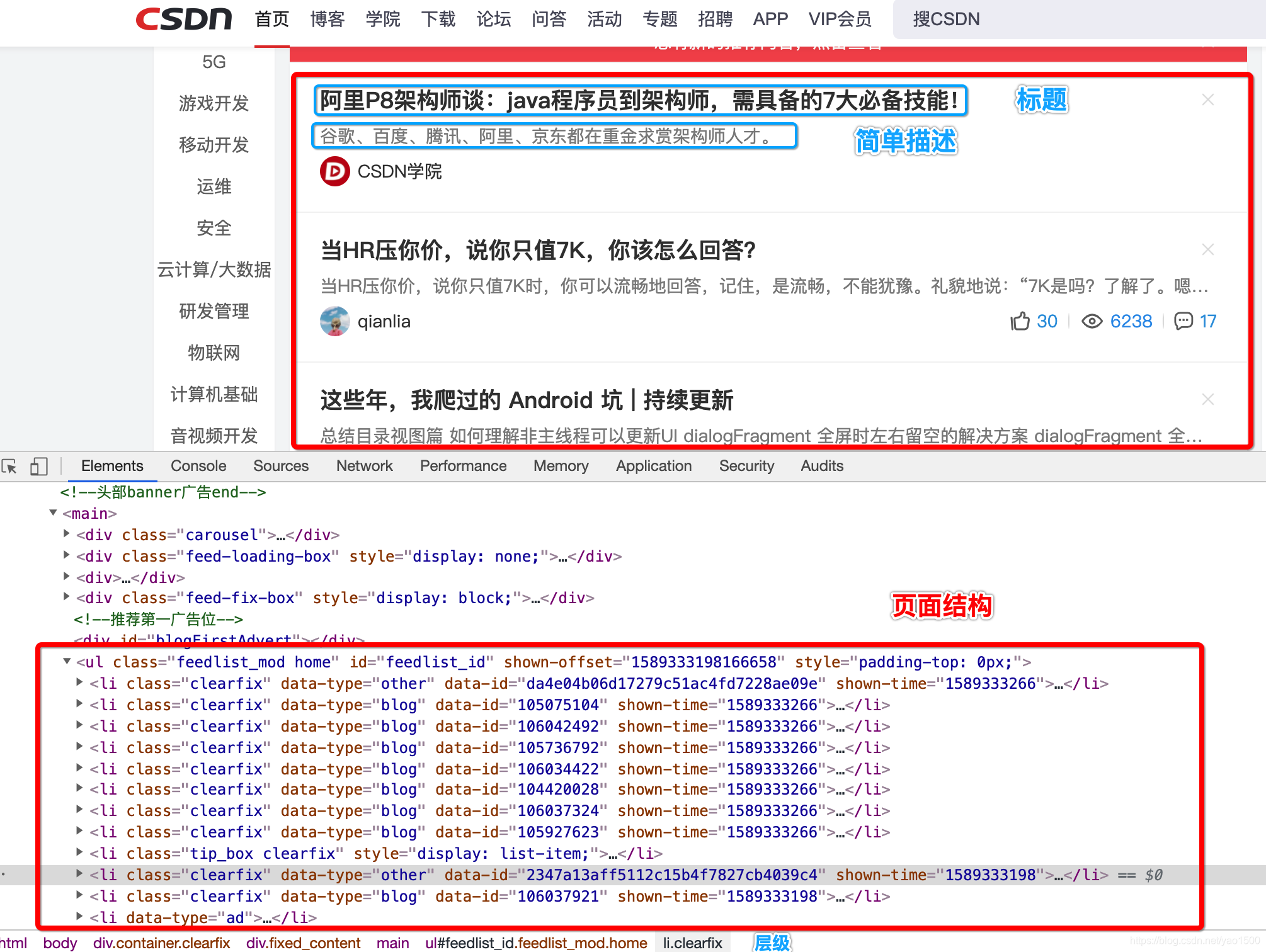
从截图我们看到,我们需要的数据都放在
li标签中,因此我们提取li标签是第一步。li的父容器ul的id选择器为feedlist_id,要记住这个,对后面的编码理解有帮助。看看
li标签内部结构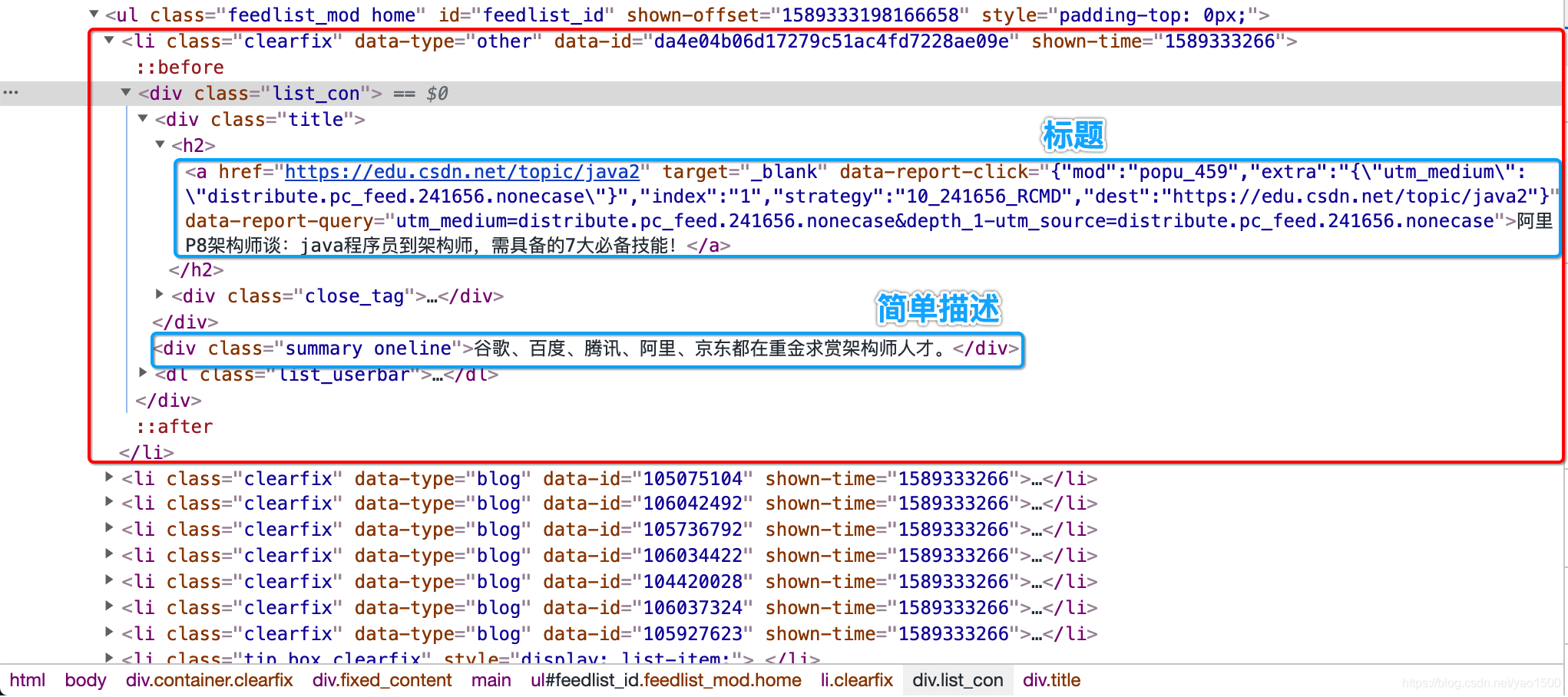
从截图看到,标题是放到
a标签中,简单描述是放到div中,所以我们第二步所这两个标签解析出来就算完事了- 您还可以看一下 CSDN就业班老师的Python爬虫技术和浏览器模拟,验证码识别视频教程课程中的 图片信息爬取实战小节, 巩固相关知识点