C语言及其应用——整数求和
测试说明
输入:一行,五个正整数。所有正整数均不超过 109。
输出:一行,以空格分隔的两个数,分别为任意选出四个整数和的最小值和最大值。
例如测试集 1 的输入是: 1 2 3 4 5 测试集 1 的运行结果为: 10 14


整体修改如下,改动处见注释,供参考:
#include <stdio.h>
#include <stdlib.h>
void miniMaxSum(int*, long long*, long long*);
int main()
{
int i;
long long sum_max, sum_min;
long long* max_p = &sum_max, * min_p = &sum_min;
int* arr = (int*)malloc(sizeof(int) * 5); // 修改
for (i = 0; i < 5; i++)
scanf("%lld", arr + i);
miniMaxSum(arr, max_p, min_p);
printf("%lld %lld\n", sum_min, sum_max);
return 0;
}
void miniMaxSum(int* arr, long long* max_p, long long* min_p)
{
/***********Begin**********/
int i, j;
long long sum[5] = { 0 };
for (i = 0; i < 5; i++) {
for (j = 0; j < 5; j++)
if (j != i)
sum[i] += arr[j]; // 修改
}
for (i = 0; i < 5; i++) { // 修改
if (i == 0 || *max_p < sum[i]) // 修改
*max_p = sum[i];
if (i == 0 || *min_p > sum[i]) // 修改
*min_p = sum[i];
}
/***********End***********/
}

这也是数据类型转换问题:

这是数据类型冲突的问题
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7666052
- 这篇博客你也可以参考下:C语言 输入10个整数,将其中最小的数与第一个数对换,把最小的数与第一个数对换,把最大的数与最后一个数对换。写三个函数:1输入十个数;2进行处理;3输出十个数
- 除此之外, 这篇博客: 详解C语言的四种排序:冒泡排序、选择排序、插入排序、快速排序中的 1.排序原理 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
选择排序的实质其实还是冒泡排序,它与冒泡排序的最显著区别是:选择排序大多数时间都在比较,而很少排序。
它的整体思路在于:第一次从待排序的中数据元素选出最小的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。
我们还是假定有6个数,这6个数在数组a[ ]之中,选择排序为了便利我们直接将这6个数假设为:9、6、2、4、7、1.
第一轮:假设首元素9为最小的元素,然后用9去比较剩余的(6-1)数,一旦有比9小的就记住这个数,然后拿这个数继续比较,目的是寻找到最小的那个数,最后交换9与最小数的位置。第一轮排序完成得到1、6、2、4、7、9
第二轮:类似的,1已经在正确的位置了,则拿二号位的6作为最小元素,然后拿6去比较剩余的((6-1)-1),个数,一旦有比6小的就记住这个数,然后拿这个数继续比较,找到最小的那个数,最后与6交换位置。第二轮排序完成得到1、2、6、4、7、9.
余轮类推,在最坏的情况下我么需要经过5轮排序
经过5轮我们就把最小的、第二小的、第三小的……放在了正确的位置

我们也可以根据这个思路写一个简短的核心代码
for (i = 0; i < N- 1; i++) { min = i;//因为是数组,只需要记录下标的值 for (j = i + 1; j < N; j++) { if (a[j] < a[min])//不断找寻最小的数 { min = j; } } { if(i!=min) {交换a[i]和a[min]的位置} }同理,我们也能够很快地写出代码
#include<stdio.h> #define N 6 int main() { int a[N]={0}; for (int i = 0; i < N; i++) { scanf("%d", &a[i]); } int i, j; int min = 0; int temp = 0; for (i = 0; i < N- 1; i++) { min = i;//因为是数组,只需要记录下标的值 for (j = i + 1; j < N; j++) { if (a[j] < a[min]) { min = j;//记录交换的元素下标值 } } if (i != min) { temp = a[i]; a[i] = a[min]; a[min] = temp; } } for (int i = 0; i < N; i++) printf("%d ", a[i]); }通过代码我们也可知道选择排序和冒泡排序的实质是一样的
需要注意的是,选择排序是不稳定的排序。关于稳定与否,用一句话来说:排序前后,相同大小的数字的相对顺序不变则是稳定的。
举个例子,6个数:arr[ ]={5、9、3、5、8、2}.这个数组中我们把第一个5记为5a,第二个5记为5b,即arr[ ]={5a、9、3、5b、8、2}。经过第一轮选择排序,数组顺序变成了{2、9、3、5b、8、5a}这就是两个5的相对顺序发生了改变。所以称选择排序是不稳定的。
虽然选择排序与冒泡排序本质相同,且时间复杂度依旧较高(与冒泡排序一致为O(n²)),但是数据量大的时候,他的效率明显优于冒泡,而且数据移动是非常耗时的,选择排序移动次数少。所以选择排序可以适用于大多数场合。
依照笔者的观点:插入排序是我们现实生活中所用到的最常见的排序,也是最符合人思维的排序
它的整体思路为:将这些数分为有序区和无序区。(开始时有序区只有一个数,即数组最开头的那个数,无序区是后面的待排序的数)。前面n-1个数已经是排好顺序的(即前面的n个数都在有序区),现将第n个数插到前面已经排好的序列中,然后找到合适自己的位置,使得插入第n个数的这个序列也是排好顺序的。实现方法为将这第n个数从有序区序列从后往前比较,直到找到这第n个数的正确位置(即arr[i]<arr[n]<arr[i+1])。
我们还是假定有6个数,直接将这6个数假设为:9、6、2、4、7、1.
第0轮:9位于有序区,6、2、4、7、1位于无序区
第1轮:取6,把6暂存起来,扫描比较有序区,有序区只有9,且9>6,9往前移,6已经到了有序区的边缘即在肯定正确位置。现在,有序区:6、9
无序区:2、4、7、1.
第2轮:取2,把2暂存起来,扫描比较有序区,2>9,9往前移,2>6,6又往前移,2放在最边缘,即正确位置。现在,有序区:2、6、9无序区:4、7、1.
余轮类推:下面的动图也可清楚的表达此过程。据此我们也易得出,插入排序的理论最坏时间复杂都依然为O(n²)。
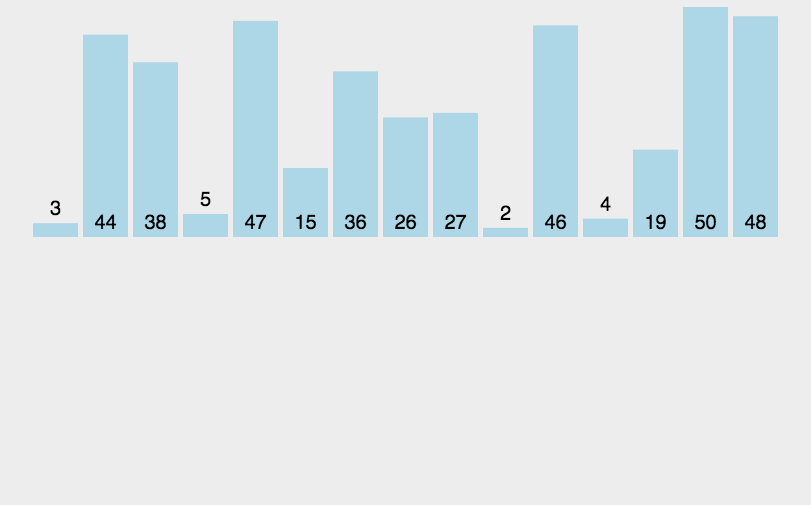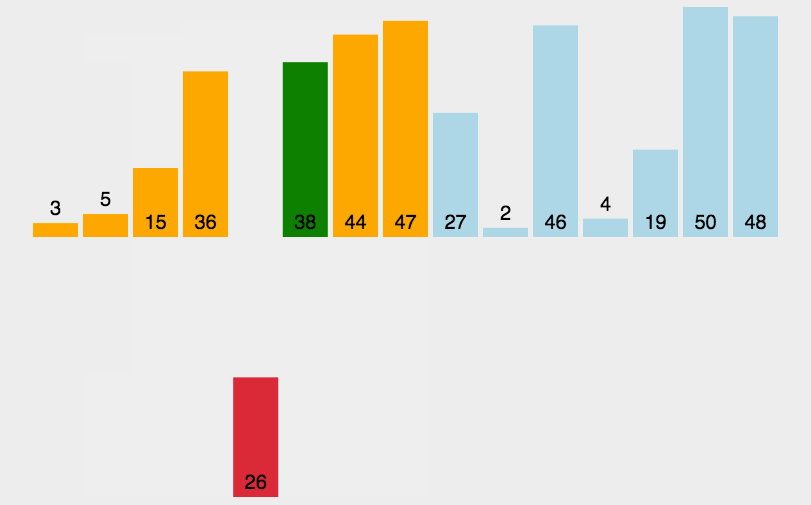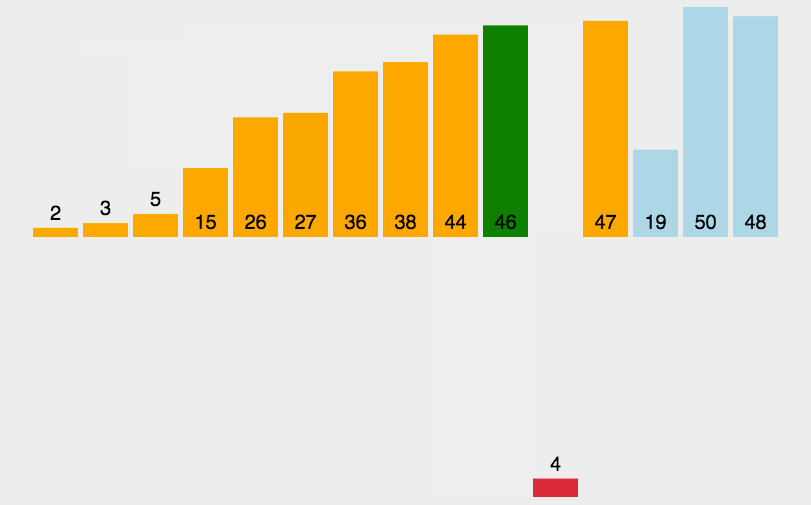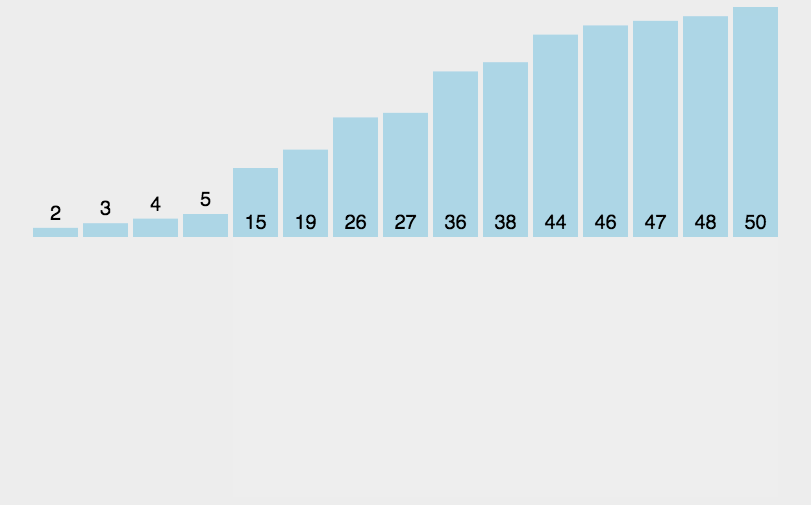
完全按照思路,很轻易的可以写出代码
#include<stdio.h> #define N 6 int main() { int a[N]={0}; for (int i = 0; i < N; i++) { scanf("%d", &a[i]); } int i, j; int youxu = 0; int temp = 0; for (i = 0; i < N - 1; i++) { youxu = i;//有序区的最后一个数的下标 temp = a[youxu + 1];//暂存无序区的最开头一个数 while (youxu >= 0) { if (temp < a[youxu]) { a[youxu + 1] = a[youxu]; youxu--; } else break; } a[youxu+1] = temp; } for (int i = 0; i < N; i++) printf("%d ", a[i]); }写完代码,我们来想想插入排序是稳定的吗
还是相同的例子,假设arr[ ]={5a、9、3、5b、8、2}。当把5b拿出来排序时,此时的arr'=[3、5a、9、5b、8、3].即有序区:3、5a、9。无序区:5b、8、3。显然,拿5b去比较是,是无法越过5a的,即插入排序是稳定的。
插入排序是最简单的排序方法,虽然其最坏时间复杂度也为O(n²),但是对于少量元素的排序,它是一个有效的算法。特别是在当已有有序的一组数,相对外来的其他数进行排列时,插入排序尤其适用。
快速排序是笔者认为,这几种中最难以理解,实现难度也较高的一种排序。快速排序的实质是对冒泡排序的改良。
快速排序可以说是递归的经典应用。
它的主要思路为:
1)设定一个分界值,将大于等于分界值的数集中在该分解值的右边,小于分解值的数集中在左边。
2)然后仿照第一步,仅对于左右部分独立排序,重复1)的步骤,对于左侧的数组数据,又取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的部分数据也做类似处理。
3)不停重复上述的过程。已经可以看出,这显然是一个递归的定义
我们还是假定有6个数,直接将这6个数假设为:5、6、2、4、7、1.
通常为了方便,我们会直接取第一个数为基准数。
现在问题来了:在初始状态下,数字5在序列的第1位。我们的目标是将9放到某个位置(把这个位置记为mid),该如何去找到这个mid且使得mid左边小于等于5,右边都大于等于5呢?
快速排序的处理办法是,分别从两端开始扫描,先从右往左找到第一个小于5的数,再从左往右找到第一个大于5的数(先从右往左,再从左往右。这一点很重要,我们接下来讲解)。
让我们借助图来理解

5,为基准数;我们借助标记left,和right充当‘探路人’。
最开始left指向最左边的5,right指向最右边的1.
第一大轮:
第1轮:从right开始’探路‘,从左至右(right--)找到第一个小于5的数,并停下,这里很特殊,right的初始所指就是目标数。接着,left开始‘探路’,从右至左(left++)找到第一个大于5的数,即6.此时变为下图

然后交换此时的left对应的值和right对应的值

第二轮:重新开始。又从right现在位置开始’探路‘,从左至右(right--)找到第一个小于5的数,并停下,这次right找到了4。接着,left开始‘探路’,从右至左(left++)找到第一个大于5的数,left这次的目标数是7.
但是遗憾的是在4处left与已经停在那里的right碰头了。我们可以理解为,两者碰头则整条路已经被‘探明’了,已经不需要再‘探路’,即整个搜索过程已结束。即下图

此时交换(right,left)所指数的值和基准数的值。
得到了

此时我们的第一大轮排列就完成,我们已经达成了目标即5左边的数都小于等于5,右边都大于等于5。
现在我们只需要将5左边的部分:4、1、2和其右边部分7、6仿照第一大轮再次快速排列。直到区间仅剩下一个元素为止。
- 您还可以看一下 正月十六工作室老师的公有云部署与运维-华为云课程中的 任务1-2 登录管理控制台界面小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
根据问题描述,我们需要编写一个C程序来计算任意选出四个整数的和的最小值和最大值。我们可以采用以下步骤来解决问题:
- 首先,定义一个数组用来存储输入的五个正整数,数组大小为5。
int num[5];- 使用循环结构,读取并存储输入的五个正整数。
for (int i = 0; i < 5; i++) { scanf("%d", &num[i]); }- 对数组进行排序,可以选用冒泡排序等排序算法。
for (int i = 0; i < 4; i++) { for (int j = 0; j < 4 - i; j++) { if (num[j] > num[j+1]) { int temp = num[j]; num[j] = num[j+1]; num[j+1] = temp; } } }- 计算最小值和最大值,最小值为数组中第一个元素和第二个元素的和,最大值为数组中最后四个元素的和。
int minSum = num[0] + num[1]; int maxSum = num[1] + num[2] + num[3] + num[4];- 输出最小值和最大值。
printf("%d %d", minSum, maxSum);完整代码如下:
#include <stdio.h> int main() { int num[5]; int minSum, maxSum; // 读取输入的五个正整数 for (int i = 0; i < 5; i++) { scanf("%d", &num[i]); } // 冒泡排序 for (int i = 0; i < 4; i++) { for (int j = 0; j < 4 - i; j++) { if (num[j] > num[j+1]) { int temp = num[j]; num[j] = num[j+1]; num[j+1] = temp; } } } // 计算最小值和最大值 minSum = num[0] + num[1]; maxSum = num[1] + num[2] + num[3] + num[4]; // 输出最小值和最大值 printf("%d %d", minSum, maxSum); return 0; }使用示例: 输入: 1 2 3 4 5 输出: 10 14