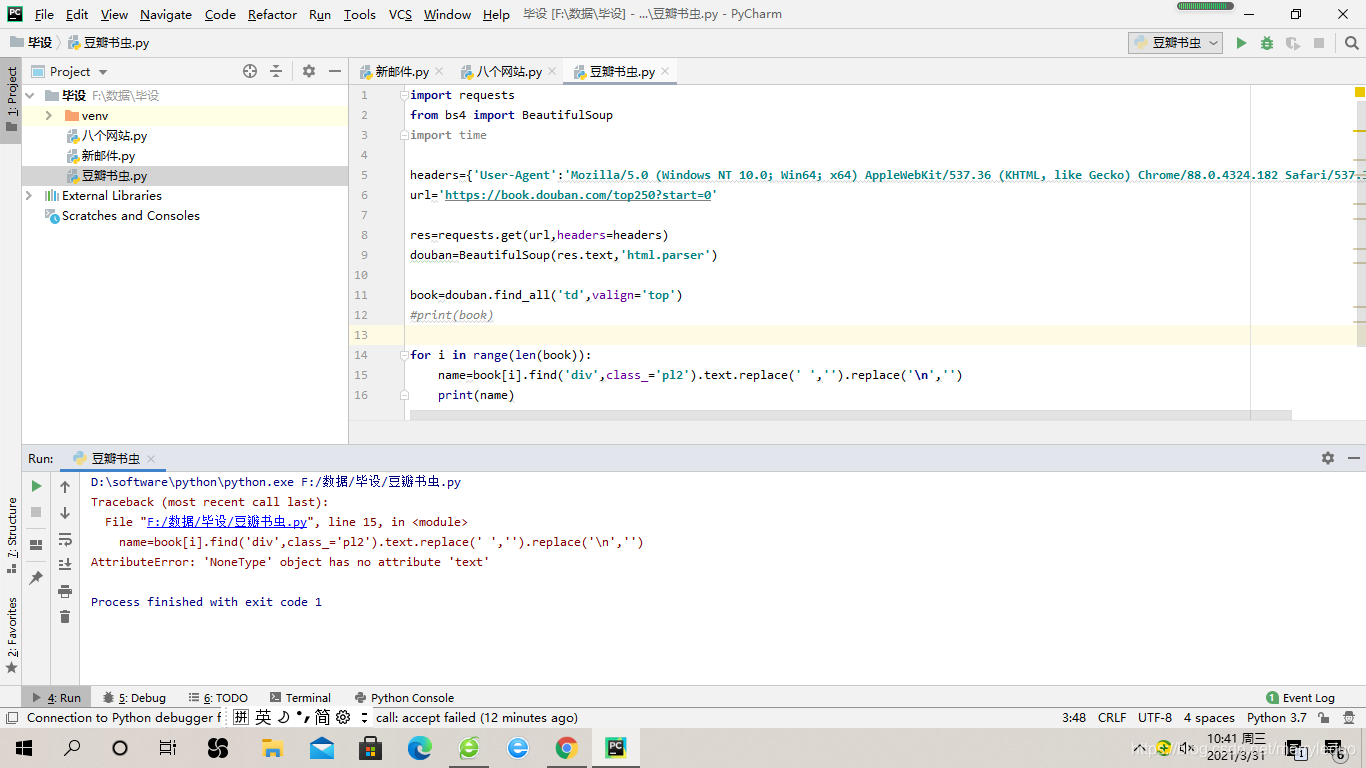
豆瓣电影信息获取问题,
AttributeError: 'NoneType' object has no attribute 'text'
这个结构对的啊


import re
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cookie': 'bid=oHaXaKMVDtY; _pk_id.100001.4cf6=7fcf7b749a8a2302.1687010568.; __utmz=30149280.1687010568.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmz=223695111.1687010568.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.46899879.1687010568.1687010568.1689418642.2; __utmb=30149280.0.10.1689418642; __utmc=30149280; __utma=223695111.1949229722.1687010568.1687010568.1689418642.2; __utmb=223695111.0.10.1689418642; __utmc=223695111; __yadk_uid=J6ZZOHkGKtng89taYk0m1tllt1OLZNM3; ll="108297"; __gads=ID=1934c56911590f64-220796395ee200a7:T=1689418831:RT=1689418831:S=ALNI_MaVHNkw8Vb74xHmHrw8BKbgu3-48w; __gpi=UID=00000cc28acfb4a6:T=1689418831:RT=1689418831:S=ALNI_MYHRm276jV9_rmxvktjHduLrJdtXA; _vwo_uuid_v2=DD0788C8CBD23E7E324C11971A5ECF412|4057c38db34d5f2733c8ee4dfcd6e8d0',
}
df = pd.DataFrame(columns=['片名',
'上映年份',
'评分',
'评价人数',
'导演',
'编剧',
'主演',
'类型',
'国家 / 地区',
'语言',
'时长'])
for i in range(0, 2):
print(f"正在爬取第{i}页")
url = 'https://movie.douban.com/top250?start={}&filter='.format(i * 25)
print(f"第{i}页爬取完成")
response = requests.get(url=url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
lists = soup.find_all(attrs={'class': "hd"})
for list in lists:
href = list.a['href']
print(href)
soup = BeautifulSoup(response.text, "html.parser")
# 片名
name = soup.find(attrs={'property': "v:itemreviewed"}).text.split(' ')[0]
# 上映年份
year = soup.find(attrs={'class': "year"}).text.replace('() ')
# 评分
score = soup.find(attrs={'property': "v:average"}).text
# 评价人数
votes = soup.find(attrs={'property': "v:votes"}).text
infos = soup.find(attrs={'id': "info"}).text.split('n')[1:11]
# 导演
director = infos[0].split(': ')[1]
# 编剧
screenwriter = infos[1].split(': ')[1]
# 主演
actor = infos[2].split(': ')[1]
# 类型
filmtype = infos[3].split(': ')[1]
# 国家/地区
area = infos[4].split(': ')[1]
if '.' in area:
area = infos[5].split(': ')[1].split('/')[0]
# 语言
language = infos[6].split(': ')[1].split('/')[0]
else:
area = infos[4].split(': ')[1].split('/')[0]
language = infos[5].split(': ')[1].split('/')[0]
if '大陆' in area or '香港' in area or '台湾' in area:
area = '中国'
if '戛纳' in area:
area = '法国'
# 时长
timeS0 = soup.find(attrs={'property': "v:runtime"}).text
times = re.findall('\d+', timeS0)[0]
data = {
'片名': name,
'上映年份': year,
'评分': score,
'评价人数': votes,
'导演': director,
'编剧': screenwriter,
'主演': actor,
'类型': filmtype,
'国家 / 地区': area,
'语言': language,
'时长': times
}
print(f'{data["片名"]}采集成功')
df = df.append([data])
直接找标签,别找属性,这样精准一些
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这篇文章讲的很详细,请看:模型训练报错AttributeError: ‘NoneType‘ object has no attribute ‘text‘
- 除此之外, 这篇博客: python错误:AttributeError: ‘NoneType‘ object has no attribute ‘text‘——“ nonetype”中的 问题描述: 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
AttributeError: ‘NoneType’ object has no attribute ‘text’——“ nonetype”对象没有属性“ text”“ nonetype”对象没有属性“ text”
- 以下回答来自chatgpt:
该错误提示意味着某个变量的类型是NoneType,并且该变量没有text属性。这通常是因为没有找到相应的元素或属性导致的。
根据参考资料的段落5分析,可能是定位元素时定位不准确导致。需要确认是否正确定位到了需要的元素。
下面给出一个可能的解决方案:
# 导入相关模块 import requests from bs4 import BeautifulSoup # 构造请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36' } # 发送请求获取页面内容 url = 'https://movie.douban.com/top250' response = requests.get(url, headers=headers) html = response.text # 使用BeautifulSoup解析页面内容 soup = BeautifulSoup(html, 'html.parser') # 查找电影信息的标签 movies = soup.find_all('div', class_='info') # 输出电影名字 for movie in movies: name = movie.find('a').find('span', class_='title').text print(name)这个解决方案使用了BeautifulSoup库来解析网页内容,并使用find和find_all方法定位到电影信息的标签。具体步骤如下:
- 导入requests和BeautifulSoup模块。
- 构造一个请求头,使得请求看起来像是由一个真实的浏览器发送的。
- 使用requests模块发送get请求,并获取返回的页面内容。
- 使用BeautifulSoup模块解析页面内容,构造一个BeautifulSoup对象。
- 使用find_all方法找到class为'info'的div标签,这些标签包含了电影的信息。
- 遍历电影的标签,使用find方法找到电影名字对应的标签,并提取出文本内容。
- 输出电影的名字。
希望这个解决方案能够帮助你解决问题。如果还有其他问题,请随时提问。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^