csdn博客转存失败
csdn写文章,记了一堆笔记,每次都有保存草稿,今天早上起来发现一半的图片说转存失败,全部没了。如何解决,很重要的资料
那就是没了. 资源没有上传上去, 你就关了 , 如有帮助给个采纳谢谢
找客服 把文章链接发一下
大概率是没了
保存到本地或者印象笔记上都不可能出现这种情况
就是平台出现bug了。我之前出现过类似的问题,也没解决。。。。。。
有历史草稿的话应该可以,如果不可以的话就说明做的太low了,可以跟他们提建议。
给个建议,写文章或者博客的话,先在本地写。然后检查没问题了,在复制到博客的编辑区里,最后进行微调。
浏览器有缓存功能,如果没有清理过浏览器,试试通过历史记录找回当时的内容.
不要太相信web浏览器的草稿存储,本地程序word有时都会不稳定崩溃导致文档丢,养成好的习惯,编辑好保存本地才是王道。
如果是腾讯文档的话可能会出现转存失败的情况,建议先保存到别的在线笔记上,比如石墨文档,然后再进行使用
这就很离谱了,让客服找技术支持一波,看看能否找回,
我一般都是用笔记来存储,不用草稿箱,这玩意不确定性大
csdn 的 bug ,有时候 csdn 自动保存就会提示保存失败情况。
如果网络存在问题就可能会造成这个效果
大概率是没有了,
不过也有很小的一部分几率是由于官方更新了系统导致的信息丢失,如果是这种情况的话,是能找回的,就看他们愿不愿意给你找了
CSDN Markdown编写博客 内容丢失、被覆盖 后找回方法
可以看看,
你这个问题,基本是找不回来了。转存失败的意思就是存储失败了。实在不行,可以找一些客服看下能否解决。不然就没有了。
这种问题大概率没了
后端数据没存上去,找不回来了。
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7531574
- 这篇博客你也可以参考下:统计csdn博客的访问量+评论数
- 除此之外, 这篇博客: CSDN 转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(已有图床)中的 对单个文档批量化替换 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
但是一篇博客可能上百张图片,一个一个链接的改,还不如
将图片保存下来直接上传,于是乎我找到了另一篇博客,博主写了一段python脚本,可以批量化处理一篇博文的所有图片,将格式换位HTML链接:
CSDN 转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传_会下雪的晴天的博客-CSDN博客
# -*- coding: utf-8 -*- # @Author: yq1ng # @Date: 2021-05-20 17:22:08 # @Last Modified by: yq1ng # @Last Modified time: 2021-05-20 18:19:47 import re old_path = "d:/code/python/md/old_file.md" new_path = "d:/code/python/md/new_file.md" old_file = open(old_path, 'r', encoding='utf-8') new_file = open(new_path, 'w', encoding='utf-8') old_line = old_file.readline() count = 0 while old_line: if "![" in old_line: url = re.findall('https://.*png|https://.*jpeg|https://.*jpg', old_line) img = '<img src="' + url[0] + '"/>' new_line = re.sub('!\[.*\)', img, old_line) new_file.write(new_line) print(old_line + ' ===> ' + new_line) count += 1 else: new_file.write(old_line) old_line = old_file.readline() old_file.close() new_file.close() print('\n已成功替换' + str(count) + '处外链问题')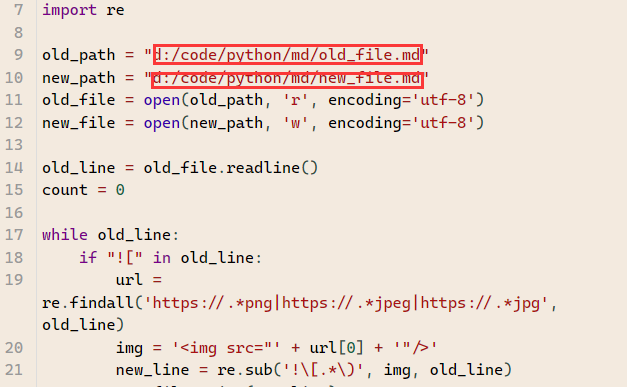
只需把红框里的路径分别改为
- 要被批量化图片链接处理的文档路径,
- 处理后的文件名和路径
如果就在当前目录,可以用下面这样的相对路径
old_path = “./old_file.md”
new_path = “./new_file.md”把脚本存到一个
.py的文件中通过
python3解析器运行这个文件即可完成转化(如果没有,可以配置一下)- 您还可以看一下 CSDN讲师老师的CSDN互联网大数据应用主题月视频课程中的 互联网非结构化数据在美国互联网运营分析中的应用-2小节, 巩固相关知识点
大概率找不回来了。
