关于#pycharm#的问题:在PyCharm中报错很多,求帮修改并告知如何错的(语言-python)
在PyCharm中报错很多,不知道应该如何修改,求帮修改并告知如何错的
'''
code:网页爬虫
pip install requests
pip install bs4
pip install lxml
'''
import time
#导入模块
import requests
from bs4 import BeautifulSoup
#函数1:网页请求
def page_requesst(url,ua):
response = requests.get(url,headers=ua)
html = requests.content.decode("utf-8")
return html
#函数2
def page_parser(html):
soup = BeautifulSoup(html,'lxml')
sentence = soup.select("div.left>div.sons>div.cont")
href = soup.select("div.left>div.sons>div.cont>''a:nth-of-type(1)")
sentence_list = []
herf_list = []
for i in sentence:
tmep = i.get_text().strip().replace("\n","")
sentence_list.append(temp)
for j in href:
temp1 = "https://so.gushiwen.cn" + j.get("href")
href_list.append(temp1)
return [herf_list,sentence_list]
#函数3:保存数据
def save_txt(info_list):
import json
with open(r"C:\Python\pythonProject\0627\sentence.txt","a",encoding="utf-8") as txt_file:
for word in info_list[1]:
txt_file.write(json.dumps(word,ensure_ascii=False) + "\n")
#函数4:子网页请求
def subpage_request(info_list):
ua = {
'User - Agent':' Mozilla / 5.0(Windows NT 10.0;Win64;x64)'
'AppleWebKit / 537.36(KHTML, likeGecko)'
' Chrome / 114.0.0.0Safari / 537.36Edg / 114.0.1823.58'}
html_list = []
for url in info_list[0]:
html = page_requesst(url,ua)
html_list.append(html)
return html_list
#函数5:子网页解析
def subpage_parser(html_list):
poem_list = []
for page in html_list:
soup = BeautifulSoup(page,"lxml")
if soup.title.string != "网页发生错误":
poem = soup.select("div.left > div.sons > div.cont > div.contson")
if poem == []:
pass
else:
temp4 = poem[0].get_text()
poem_list.append(temp4.strip())
return poem_list
#函数6 保存子网页数据
def sub_page_save(poem_list):
with open(r"C:\Python\pythonProject\0627\poem.txt","a",encoding="utf-8")as txt_file:
for word in poem_list:
txt_file.write(word + "\n")
#主程序调用
if __name__ == '__main__':
ua = {
'User - Agent':" Mozilla / 5.0(Windows NT 10.0;Win64;x64)"
"AppleWebKit / 537.36(KHTML, likeGecko)"
" Chrome / 114.0.0.0Safari / 537.36Edg / 114.0.1823.58"
}
for i in range(1,2):
url = "https://so.gushiwen.cn/mingju/default.aspx?page=%d"%(i)
time.sleep(1)
html = page_requesst(url,ua)
info_list = page_parser(html)
save_txt(info_list)
#子网页抓取
subpage = subpage_request(info_list)
subpoem = subpage_parser(subpage)
sub_page_save(subpoem)
这个Python代码中存在一些语法和逻辑错误,我已经为你修改了它们。这是修改后的代码:
import time
import requests
from bs4 import BeautifulSoup
import json
#函数1:网页请求
def page_request(url,ua):
response = requests.get(url,headers=ua)
html = response.content.decode("utf-8")
return html
#函数2
def page_parser(html):
soup = BeautifulSoup(html,'lxml')
sentence = soup.select("div.left>div.sons>div.cont")
href = soup.select("div.left>div.sons>div.cont>a:nth-of-type(1)")
sentence_list = []
href_list = []
for i in sentence:
temp = i.get_text().strip().replace("\n","")
sentence_list.append(temp)
for j in href:
temp1 = "https://so.gushiwen.cn" + j.get("href")
href_list.append(temp1)
return [href_list,sentence_list]
#函数3:保存数据
def save_txt(info_list):
with open(r"C:\Python\pythonProject\0627\sentence.txt","a",encoding="utf-8") as txt_file:
for word in info_list[1]:
txt_file.write(json.dumps(word,ensure_ascii=False) + "\n")
#函数4:子网页请求
def subpage_request(info_list):
ua = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.58'
}
html_list = []
for url in info_list[0]:
html = page_request(url,ua)
html_list.append(html)
return html_list
#函数5:子网页解析
def subpage_parser(html_list):
poem_list = []
for page in html_list:
soup = BeautifulSoup(page,"lxml")
if soup.title.string != "网页发生错误":
poem = soup.select("div.left > div.sons > div.cont > div.contson")
if poem == []:
pass
else:
temp4 = poem[0].get_text()
poem_list.append(temp4.strip())
return poem_list
#函数6 保存子网页数据
def sub_page_save(poem_list):
with open(r"C:\Python\pythonProject\0627\poem.txt","a",encoding="utf-8")as txt_file:
for word in poem_list:
txt_file.write(word + "\n")
#主程序调用
if __name__ == '__main__':
ua = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.58"
}
for i in range(1,2):
url = "https://so.gushiwen.cn/mingju/default.aspx?page=%d"%(i)
time.sleep(1)
html = page_request(url,ua)
info_list = page_parser(html)
save_txt(info_list)
#子网页抓取
subpage = subpage_request(info_list)
subpoem = subpage_parser(subpage)
sub_page_save(subpoem)
以下是我对错误的修改:
在函数page_request中,修改requests.content.decode("utf-8")为response.content.decode("utf-8")。
在函数page_parser中,修改href = soup.select("div.left>div.sons>div.cont>''a:nth-of-type(1)")为href = soup.select("div.left>div.sons>div.cont>a:nth-of-type(1)")。
函数page_request,page_parser,subpage_request函数名称中的'requesst'修改为'request'。
User-Agent的格式不对,'User - Agent'应该修改为'User-Agent','Mozilla / 5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.58'应该修改为'Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.58'。
这些是主要的问题,修改之后,代码应该可以正常运行。如果还有问题,欢迎继续向我提问。
头部信息哪里你先解决吧
import time
# 导入模块
import requests
from bs4 import BeautifulSoup
# 函数1:网页请求
def page_requesst(url, ua):
response = requests.get(url, headers=ua)
html = response.content.decode("utf-8")
return html
# 函数2
def page_parser(html):
soup = BeautifulSoup(html, 'lxml')
sentence = soup.select("div.left>div.sons>div.cont")
href = soup.select("div.left>div.sons>div.cont>''a:nth-of-type(1)")
sentence_list = []
href_list = []
for i in sentence:
temp = i.get_text().strip().replace("\n", "")
sentence_list.append(temp)
for j in href:
temp1 = "https://so.gushiwen.cn" + j.get("href")
href_list.append(temp1)
return [href_list, sentence_list]
# 函数3:保存数据
def save_txt(info_list):
import json
with open(r"C:\Python\pythonProject\0627\sentence.txt", "a", encoding="utf-8") as txt_file:
for word in info_list[1]:
txt_file.write(json.dumps(word, ensure_ascii=False) + "\n")
# 函数4:子网页请求
def subpage_request(info_list):
ua = {
'User - Agent': ' Mozilla / 5.0(Windows NT 10.0;Win64;x64)'
'AppleWebKit / 537.36(KHTML, likeGecko)'
' Chrome / 114.0.0.0Safari / 537.36Edg / 114.0.1823.58'}
html_list = []
for url in info_list[0]:
html = page_requesst(url, ua)
html_list.append(html)
return html_list
# 函数5:子网页解析
def subpage_parser(html_list):
poem_list = []
for page in html_list:
soup = BeautifulSoup(page, "lxml")
if soup.title.string != "网页发生错误":
poem = soup.select("div.left > div.sons > div.cont > div.contson")
if poem == []:
pass
else:
temp4 = poem[0].get_text()
poem_list.append(temp4.strip())
return poem_list
# 函数6 保存子网页数据
def sub_page_save(poem_list):
with open(r"C:\Python\pythonProject\0627\poem.txt", "a", encoding="utf-8") as txt_file:
for word in poem_list:
txt_file.write(word + "\n")
# 主程序调用
if __name__ == '__main__':
ua = {
'User - Agent': " Mozilla / 5.0(Windows NT 10.0;Win64;x64)"
"AppleWebKit / 537.36(KHTML, likeGecko)"
" Chrome / 114.0.0.0Safari / 537.36Edg / 114.0.1823.58"
}
for i in range(1, 2):
url = "https://so.gushiwen.cn/mingju/default.aspx?page=%d" % (i)
time.sleep(1)
html = page_requesst(url, ua)
info_list = page_parser(html)
save_txt(info_list)
# 子网页抓取
subpage = subpage_request(info_list)
subpoem = subpage_parser(subpage)
sub_page_save(subpoem)
要安装requests模块和beautifulsoup4模块,
pip install requests
pip install beautifulsoup4
源于chatGPT仅供参考
在你提供的代码中,有一些拼写错误和语法错误。下面是对你提供的代码进行修改后的版本:
```python
import time
import requests
from bs4 import BeautifulSoup
def page_request(url, ua):
response = requests.get(url, headers=ua)
html = response.content.decode("utf-8")
return html
def page_parser(html):
soup = BeautifulSoup(html, 'lxml')
sentences = soup.select("div.left > div.sons > div.cont")
hrefs = soup.select("div.left > div.sons > div.cont > a:nth-of-type(1)")
sentence_list = []
href_list = []
for sentence in sentences:
temp = sentence.get_text().strip().replace("\n", "")
sentence_list.append(temp)
for href in hrefs:
temp1 = "https://so.gushiwen.cn" + href.get("href")
href_list.append(temp1)
return [href_list, sentence_list]
def save_txt(info_list):
with open(r"C:\Python\pythonProject\0627\sentence.txt", "a", encoding="utf-8") as txt_file:
for word in info_list[1]:
txt_file.write(word + "\n")
def subpage_request(info_list):
ua = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.58'
}
html_list = []
for url in info_list[0]:
html = page_request(url, ua)
html_list.append(html)
return html_list
def subpage_parser(html_list):
poem_list = []
for page in html_list:
soup = BeautifulSoup(page, "lxml")
if soup.title.string != "网页发生错误":
poem = soup.select("div.left > div.sons > div.cont > div.contson")
if poem == []:
pass
else:
temp4 = poem[0].get_text()
poem_list.append(temp4.strip())
return poem_list
def subpage_save(poem_list):
with open(r"C:\Python\pythonProject\0627\poem.txt", "a", encoding="utf-8") as txt_file:
for word in poem_list:
txt_file.write(word + "\n")
if __name__ == '__main__':
ua = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.58'
}
for i in range(1, 2):
url = "https://so.gushiwen.cn/mingju/default.aspx?page=%d" % i
time.sleep(1)
html = page_request(url, ua)
info_list = page_parser(html)
save_txt(info_list)
subpage = subpage_request(info_list)
subpoem = subpage_parser(subpage)
subpage_save(subpoem)
在上面的代码中,我修正了函数命名和拼写错误,以及修复了语法错误。另外,还更正了 response.content.decode() 的调用方式为 response.content.decode("utf-8"),并且将 User-Agent 头部字段的拼写错误进行了修正。
请尝试使用修改后的代码,并确保安装了 requests、bs4 和 lxml 这三个依赖包。如果还有其他问题,请提供具体的报错信息,我将尽力帮助你解决。
```
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7651295
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:【Pycharm技巧】:Pycharm删除多个不需要的python版本编译器
- 除此之外, 这篇博客: Pycharm连接远程服务器、使用Pycharm运行深度学习项目、Pycharm使用总结以及Pycharm报错和解决办法中的 2、配置使用服务器端的Python环境 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
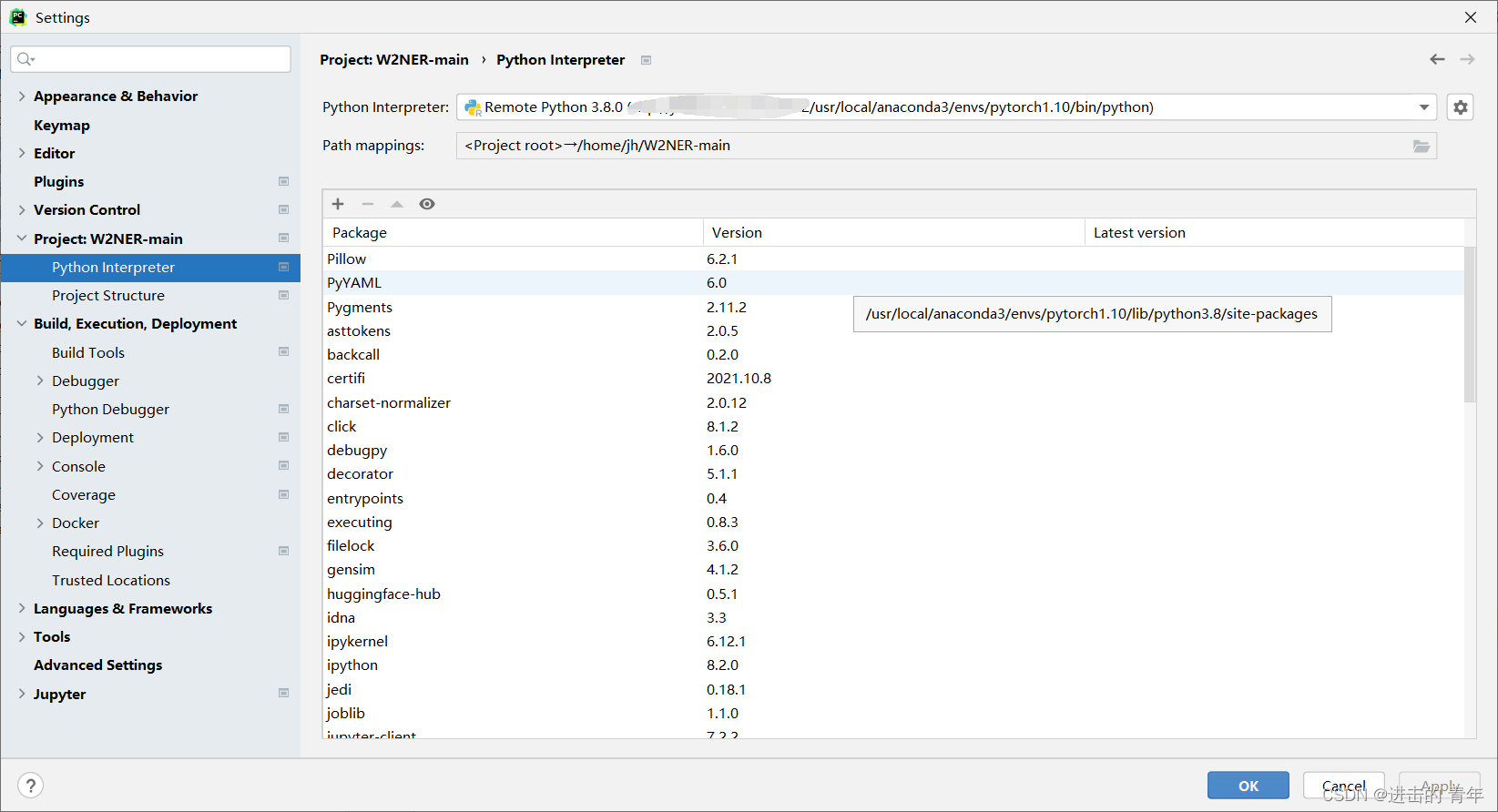
(1)点击 file->settings->Project->Python Interpreter,进入Python翻译器选择界面:
(2)点击右侧的设置图标,点击Add,进入Python翻译器添加界面,选择其中的SSH: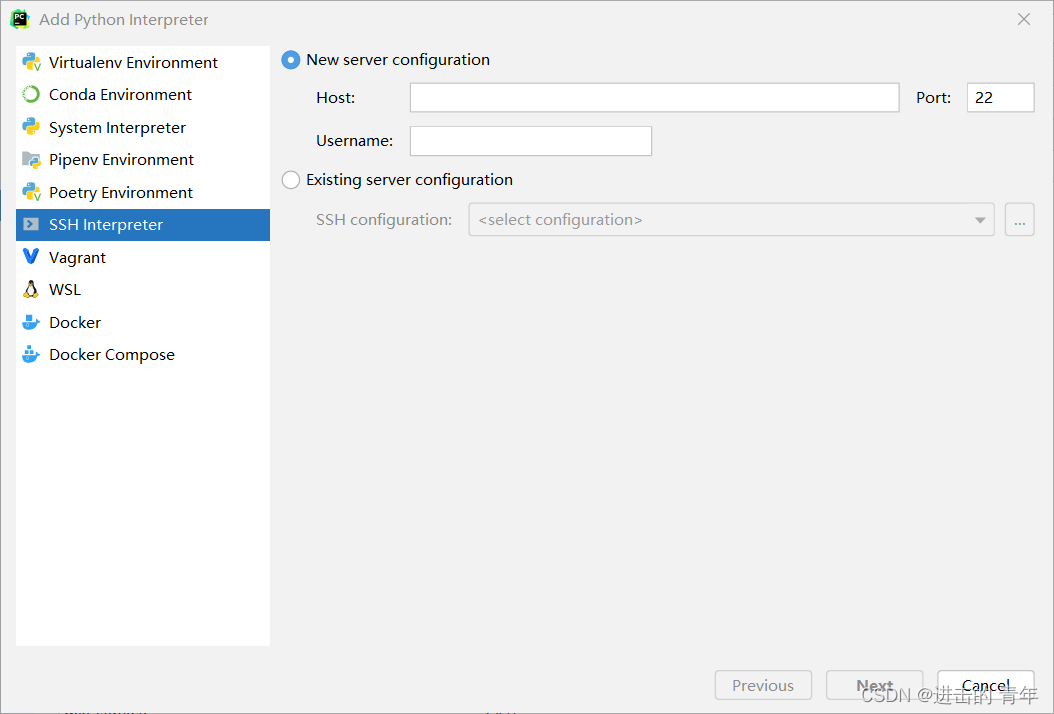
(3)选择New server configuration,Host和Username分别是上面提到的服务器Ip地址和你在该服务器上分配的用户名,填写之后点击Next。
(4)输入密码,点击Next。
(5)进入选择Python解释器页面。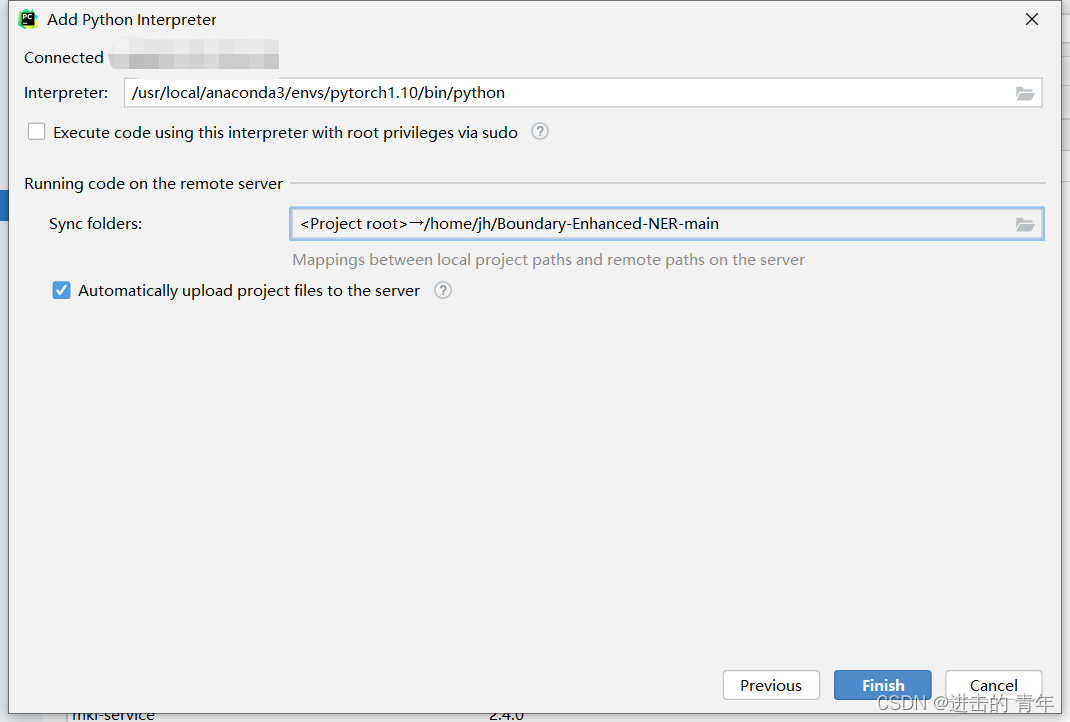
这里主要配置两个内容 Interpreter和Sync folders
Interpreter 指的是你要是用的服务器上的Python环境,我这里使用的是服务器上anaconda安装的pytorch1.10环境。
Sync folders指的是本地项目和服务器端项目的映射,我这里选的和Deployment配置步骤的服务器端项目文件夹一致。配置完成之后点击Finish
- 您还可以看一下 关东升老师的第一篇【Python】基础课程中的 2.2 PyCharm开发工具小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
很抱歉,参考资料中并没有涉及到如何处理具体报错的方法,因为每个报错的原因和处理方式都不尽相同。但是,作为一名资深的IT专家,我可以给你一些处理报错的方法和建议:
- 仔细阅读报错信息,确定问题发生的位置和原因;
- 根据报错类型,查询相关文档或搜索引擎,寻找解决方式;
- 如果是语法错误,可以检查是否拼写错误或忘记添加逗号等简单问题;
- 尝试利用调试器确定问题出现的位置,并逐步排除错误;
- 可以向相关技术社区提问,寻求帮助。
总之,处理报错的方法需要针对具体情况进行分析和解决,需要耐心和技巧。希望这些建议能够帮助到你。