关于#transformer#的问题:transformer预测结果出现了断崖式的偏高怎么办(语言-python)
用transformer训练出来的模型测试图与实际很吻合,但是预测结果出现了断崖式的偏高,想请教一下是什么原因?


断崖式的偏高可能是由于模型过拟合或者训练数据存在异常值等原因导致的。以下是一些可能的解决方案:
检查数据:确保训练数据没有异常值或者噪声。如果存在,需要进行数据清洗。
正则化:如果模型过拟合,可以尝试使用正则化技术,如L1、L2或者dropout。
调整模型结构:可能是因为模型太复杂导致的过拟合,可以尝试简化模型结构。
使用早停法:在训练过程中,如果发现验证集的损失开始增大,可以提前停止训练。
调整学习率:如果学习率过大,可能会导致模型在优化过程中跳过最优解,可以尝试降低学习率。
使用更多数据:如果条件允许,可以尝试增加训练数据,这通常可以提高模型的泛化能力。
使用其他优化算法:有时候,使用不同的优化算法可以得到更好的结果,比如Adam、RMSProp等。
重新初始化模型:有时候,模型的初始参数可能会影响最终的结果,可以尝试重新初始化模型参数。
以上是一些可能的解决方案,具体需要根据问题的具体情况来决定使用哪种方法。
时间序列预测 | Python实现Transformer时间序列数据预测
可以借鉴下
https://blog.csdn.net/m0_57362105/article/details/122380066
测试集和预测集的差异太大,模型过度拟合了,预测数据存在噪声或异常,预测数据分布和训练数据不匹配等都要排查
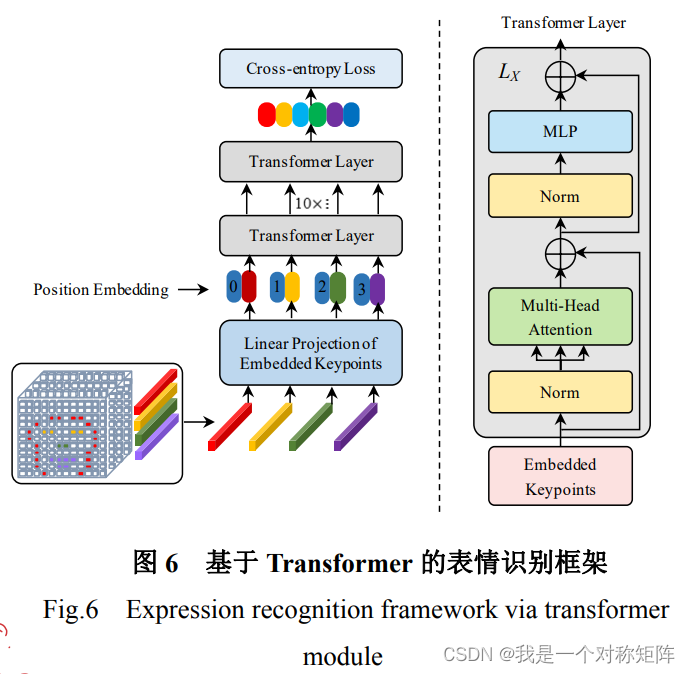
- 这篇博客: 融合关键点属性与注意力表征的人脸表情识别--2021.高红霞中的 1.3.1 Transformer网络框架 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
这一块感觉也没什么好说的,就是标准的ViT架构,只需要关注输入和输出即可。
输出不必说,标准的ViT最后面也是跟一个全连接层,用于分类。
输入就是上面的512维的68个关键点的表征数据。