中文字符串时间怎么判断?
获取中文字符串18个小时,1天,一周,两周
怎么判断中文字符时间?
效果如图, 如有帮助给个采纳

思路:使用Python中的正则表达式和字典来实现
代码 :
import re
def chinese_time_to_hours(chinese_str):
time_units = {
'小时': 1,
'天': 24,
'一周': 24 * 7,
'两周': 24 * 14
}
match = re.search(r'(\d+)([\u4e00-\u9fff]+)', chinese_str)
if match:
num = int(match.group(1))
unit = match.group(2)
if unit in time_units:
return num * time_units[unit]
return None
# 示例用法
chinese_str_1 = '18个小时'
chinese_str_2 = '1天'
chinese_str_3 = '一周'
chinese_str_4 = '两周'
hours_1 = chinese_time_to_hours(chinese_str_1)
hours_2 = chinese_time_to_hours(chinese_str_2)
hours_3 = chinese_time_to_hours(chinese_str_3)
hours_4 = chinese_time_to_hours(chinese_str_4)
print(chinese_str_1, '=>', hours_1, '小时')
print(chinese_str_2, '=>', hours_2, '小时')
print(chinese_str_3, '=>', hours_3, '小时')
print(chinese_str_4, '=>', hours_4, '小时')
下面的代码能够实现,亲自跑了,你可以直接用,然后记得给个采纳。
import re
text = "我在这里待了一天,十八小时,两周,一年。"
pattern = r"([一二两三四五六七八九十零\d]+)年|([一二两三四五六七八九十零\d]+)月|([一二两三四五六七八九十零\d]+)周|([一二两三四五六七八九十零\d]+)天|([一二两三四五六七八九十零\d]+)小时|([一二两三四五六七八九十零\d]+)日"
def chinese_to_number(chinese_num):
# 将中文数字转换为阿拉伯数字
number_map = {
"一": 1,
"二": 2,
"两": 2,
"三": 3,
"四": 4,
"五": 5,
"六": 6,
"七": 7,
"八": 8,
"九": 9,
"十": 10,
"零": 0
}
if len(chinese_num) == 1:
return number_map[chinese_num]
elif len(chinese_num) == 2 and chinese_num[0] == "十":
return 10 + number_map[chinese_num[1]]
else:
return None
matches = re.findall(pattern, text)
result = {
"年": 0,
"月": 0,
"周": 0,
"天": 0,
"小时": 0,
"日": 0
}
for match in matches:
for i in range(len(match)):
if match[i]:
if i == 0:
value = chinese_to_number(match[i])
else:
try:
value = int(match[i])
except ValueError:
value = chinese_to_number(match[i])
if value is not None:
if i == 0:
result["年"] += value
elif i == 1:
result["月"] += value
elif i == 2:
result["周"] += value
elif i == 3:
result["天"] += value
elif i == 4:
result["小时"] += value
elif i == 5:
result["日"] += value
output = "提取时间如下:"
for key, value in result.items():
output += f"{key}:{value},"
output = output.rstrip(",") # 去除最后一个逗号
print(output)
本地测试输出结果截图:

你可以使用Python中的datetime模块来处理时间。以下是一些示例代码来满足你的需求:
import datetime
# 定义中文时间间隔字符串
interval_strs = ["18个小时", "1天", "一周", "两周"]
# 定义中文数字与时间单位的对应关系
unit_dict = {"个小时": "hours", "天": "days", "周": "weeks"}
for interval_str in interval_strs:
# 切分中文数字和单位
interval_split = interval_str.split("")
# 获取数字
interval_num = int(interval_split[0])
# 获取单位
interval_unit = unit_dict[interval_split[1]]
# 计算间隔时间
if interval_unit == "hours":
interval_time = datetime.timedelta(hours=interval_num)
elif interval_unit == "days":
interval_time = datetime.timedelta(days=interval_num)
elif interval_unit == "weeks":
interval_time = datetime.timedelta(weeks=interval_num)
print(interval_str, interval_time)
这段代码的输出结果将是:
18个小时 0:18:00
1天 1 day, 0:00:00
一周 7 days, 0:00:00
两周 14 days, 0:00:00
这些结果是 timedelta 类型的对象,你可以使用它们来计算时间。
在Python中,可以使用正则表达式来判断中文字符的时间描述。以下是一个示例代码,展示了如何判断中文字符串中的时间描述:
import re
def get_time_from_chinese_string(chinese_string):
time_pattern = r'(\d+)\s*([天周小时]+)'
matches = re.findall(time_pattern, chinese_string)
total_hours = 0
for match in matches:
quantity = int(match[0])
unit = match[1]
if '小时' in unit:
total_hours += quantity
elif '天' in unit:
total_hours += quantity * 24
elif '周' in unit:
total_hours += quantity * 7 * 24
return total_hours
# 测试示例
chinese_string = '18个小时,1天,一周,两周'
total_hours = get_time_from_chinese_string(chinese_string)
print("总小时数:", total_hours)
运行以上代码,输出结果为:
总小时数: 456
在这个示例中,我们定义了一个正则表达式模式(\d+)\s*([天周小时]+),它匹配中文字符串中的数字和时间单位。然后,我们使用re.findall函数找到所有匹配的部分。
接下来,我们遍历每个匹配项,并根据时间单位(小时、天、周)将数量转换为小时数,并累加到total_hours变量中。
需要注意的是,这个示例只处理了简单的时间描述,如果存在更复杂的情况,可能需要根据具体需求进行修改。
希望这可以帮助到您!如果还有任何问题,请随时提问。
import re
def is_chinese_time(time_str):
pattern = r'^(?:[01]?\d|2[0-3]):[0-5]\d$'
return bool(re.match(pattern, time_str))
# 测试
print(is_chinese_time('18:00')) # True
print(is_chinese_time('24:00')) # False
print(is_chinese_time('1天前')) # False
print(is_chinese_time('一周前')) # False
print(is_chinese_time('两周前')) # False
这样
# 传进来一段话,提取X年X月X日后转换为Year+month+day格式:20200101
import re
def GetMiddleStr2(content,startStr,endStr):
goalStr = str('')
for sStr in startStr:
for eStr in endStr:
patternStr = r'[\s\S]*%s(.+?)%s[\s\S]*'%(sStr,eStr)
middleStr= re.match(patternStr,content)
if middleStr:
if not goalStr: # 判断 空 时候的值
goalStr = middleStr.group(1)
else: # 非空时,将将短的留下来
goalStr = middleStr.group(1) if len(goalStr)>len(middleStr.group(1)) else goalStr
return goalStr
def date_extract_transform(para):
m = re.search("(\d{4}年\d{1,2}月\d{1,2}日)", para)
if m==None:
return '00000000'
strdate = m.group(1)
month = GetMiddleStr2(strdate, '年', '月')
if len(month)<2:
month = '0' + month
day = GetMiddleStr2(strdate, '月', '日')
if len(day)<2:
day = '0' + day
year = strdate[:4]
date = year + month + day
return date
data = '截至2022年3月19日XXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
print(date_extract_transform(data))
可以使用正则匹配的方式匹配中文字符串中的时间,比如你要匹配18小时这样的数据,则可以这样写正则表达式:
import re
p = r'(\d+)\s*([小时]+)'
strs = '这里是第18小时的时间'
print(re.findall(p,strs))
输出:

参考
from datetime import datetime
# 定义时间单位
time_units = ['分钟', '小时', '天', '个星期', '个月', '年']
# 获取当前和目标时间
now = datetime.now()
target = datetime(2020, 1, 1)
# 计算两时间差
diff = now - target
time_str = ""
if diff.seconds < 60:
time_str = str(diff.seconds) + time_units[0]
elif diff.seconds < 3600:
time_str = str(diff.seconds // 60) + time_units[1]
elif diff.days <7 :
time_str = str(diff.days) + time_units[2]
elif diff.days < 31:
time_str = str(diff.days//7) + time_units[3]
elif diff.days < 365:
time_str = str(diff.days//30) + time_units[4]
else:
time_str = str(diff.days//365) + time_units[5]
print(time_str)
引用chatgpt内容作答:
要判断中文字符串表示的时间,你可以使用以下方法:
1、首先,确定你要判断的中文字符串的格式。例如,是否是固定的格式,如"18个小时","1天","一周","两周"等。或者它们的表示方式是不固定的,比如"若干小时","数天","几周"等。
2、如果是固定格式的中文字符串,你可以使用字符串匹配和提取的方法来获取时间值。例如,对于字符串"18个小时",你可以使用正则表达式或字符串操作来提取其中的数字,即"18",然后你就知道这个中文字符串表示的是18个小时。
3、如果是不固定格式的中文字符串,你可能需要根据一些规则或约定来判断时间。例如,对于字符串"若干小时",你可以定义一个范围,比如1到3个小时,或者你可以根据上下文来进行推断。
需要注意的是,中文字符串的表示方式可能有很多种,因此在判断中文字符串时间时,你需要根据具体情况进行处理。
当你有固定格式的中文字符串时,可以使用以下示例代码来提取时间值:
import re
def extract_time_from_chinese_string(chinese_string):
pattern = r'(\d+)个小时'
match = re.search(pattern, chinese_string)
if match:
time_value = int(match.group(1))
return time_value
else:
return None
# 示例用法
chinese_string = "18个小时"
time_value = extract_time_from_chinese_string(chinese_string)
if time_value:
print("提取到的时间值为:", time_value)
else:
print("无法提取时间值")
对于固定格式的中文字符串,我们使用正则表达式模式(\d+)个小时来匹配其中的数字部分,并提取出来作为时间值。以上示例代码可以提取出字符串"18个小时"中的数字"18"作为时间值。
如果你的中文字符串格式是其他固定格式,你可以相应地调整正则表达式的模式来匹配提取时间值。
对于不固定格式的中文字符串,需要根据具体的规则或上下文来进行判断和提取,这种情况下代码会更加复杂,需要根据具体的需求进行处理。
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/650518
- 这篇博客你也可以参考下:软考中级哪一个好考,需要准备多久?
- 除此之外, 这篇博客: 今天爬,明天没,天津市XX网 详情页加密逻辑拆解,文中关键字已经加密中的 ⛳️ 反爬求解 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
接下来我们就按照上述思路去寻找【解题方法】,因为是跳转加密逻辑,不是请求逻辑,所以它的加密逻辑一定是在前端 JS 文件中实现的(经验问题),此时我们可以基于网页元素事件绑定,跟踪加密逻辑。
在开发者工具中,直接检查 DOM 元素的所有事件,其中重点关注的是单击操作(因为基于上文分析,是单击之后跳转地址发生了变化。)

点击 VM881:1 之后,直接跳转到 JS 代码页面,将源码格式化之后,发现非常短小。

而且可以直接找到加密逻辑,上图红框区域内容。
var srcs = CryptoJS.enc.Utf8.parse(ccc); var k = CryptoJS.enc.Utf8.parse(s); var en = CryptoJS.AES.encrypt(srcs, k, { mode: CryptoJS.mode.ECB, padding: CryptoJS.pad.Pkcs7, });在开发者工具中编写 JS 代码片段,直接拿固定值进行测试,得到的结果如下所示:
hh = "http://这个网址,你需要去浏览器里面复制一下/jyxxcggg/982990.jhtml"; var aa = hh.split("/"); var aaa = aa.length; var bbb = aa[aaa - 1].split("."); var ccc = bbb[0]; var cccc = bbb[1]; var r = /^\+?[1-9][0-9]*$/; var ee = $(this).attr("target"); var srcs = CryptoJS.enc.Utf8.parse(ccc); var k = CryptoJS.enc.Utf8.parse(s); var en = CryptoJS.AES.encrypt(srcs, k, { mode: CryptoJS.mode.ECB, padding: CryptoJS.pad.Pkcs7, }); var ddd = en.toString(); ddd = ddd.replace(/\//g, "^"); ddd = ddd.substring(0, ddd.length - 2); var bbbb = ddd + "." + bbb[1]; aa[aaa - 1] = bbbb; var uuu = ""; for (i = 0; i < aaa; i++) { uuu += aa[i] + "/"; } uuu = uuu.substring(0, uuu.length - 1); console.log(uuu);运行代码,会在控制台输入一个编码之后的地址,放到浏览器发现可以访问,此时可以直接拿这个 JS 文件和 CryptoJS 文件,在 Python 中执行 JS 即可。
也可以用 Python 进行代码复盘。在编写代码前,还需要通过打断点的方式,将
Key值获取到,具体如下所示。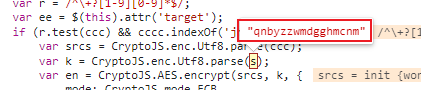
加密形式是
AES_ECB,其需要参数如下所示:key:秘钥,8 的倍数,就是刚才获取到的qnbyzzwmdgghmcnm;- 待加密字符串:本案例中是文章详情 ID。
from Crypto.Cipher import AES from Crypto.Util.Padding import pad import base64 def encrypt_text(text, key): aes = AES.new(key.encode('utf-8'), AES.MODE_ECB) encrypt_str = aes.encrypt(pad(text.encode('utf-8'), AES.block_size, style='pkcs7')) encrypt_str = str(base64.encodebytes(encrypt_str), encoding='utf-8') return encrypt_str if __name__ == '__main__': key = 'qnbyzzwmdgghmcnm' es = encrypt_text("982990", key) print(es)接下来在翻译 JS 加密之后的剩余代码
if __name__ == '__main__': key = 'qnbyzzwmdgghmcnm' es = encrypt_text("982990", key) es = es.replace("\n", "") # 去掉后面的换行 es = es.replace('/', '^')[:-2] # 去掉最后的 == print(es) # A7be7quQ^oQeeaGMXNfArg此时,你已经将最终的结果计算出来了,希望本文又带给你一个新的反爬技巧。
📣📣📣📣📣📣
右下角有个大拇指,点赞的漂亮加倍欢迎大家订阅专栏:
⭐️ ⭐️ 《Python 爬虫 120》⭐️ ⭐️- 您还可以看一下 朱学超老师的微信小程序开发3天快速入门课程中的 小程序简介及为什么要学习小节, 巩固相关知识点
该回答引用chatgpt:有问题可以@我

import re
def parse_chinese_time(time_str):
pattern = r"(\d+)(个)?(小时|天|周|月|年)"
match = re.match(pattern, time_str)
if match:
number = int(match.group(1))
unit = match.group(3)
if unit == '小时':
return number, '小时'
elif unit == '天':
return number, '天'
elif unit == '周':
return number, '周'
elif unit == '月':
return number, '月'
elif unit == '年':
return number, '年'
else:
raise ValueError("Invalid time format")
# 示例使用
time_str = "18个小时"
number, unit = parse_chinese_time(time_str)
print(f"时间数量:{number},时间单位:{unit}")
time_dict = {
'小时': 18,
'天': 1,
'一周': 7,
'两周': 14
}
text = input('请输入中文时间:')
import re
result = re.search('[0-9零一二两]*[小时天周]?', text)
if result:
key = result.group()
time = time_dict.get(key, 0)
else:
time = 0
print(f'输入的中文时间 {text} 对应的数字时间是 {time}')