Java语言读取数据文件,数据文件分为2列
Java语言读取数据文件,数据文件分为2列,其中一列是字符串,存在重复,怎么加载到字典里来
不知道你这个问题是否已经解决, 如果还没有解决的话:- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/1058590
- 这篇博客也不错, 你可以看下如何用Java语言将某个文件夹里面的所有文件、子文件夹复制到另一个文件夹内?
- 你还可以看下java参考手册中的 java-学习Java语言 - 描述Java编程语言的基本概念和特点的课程。-类和对象》描述了如何编写创建对象的类,以及如何创建和使用对象。-课堂
- 除此之外, 这篇博客: 亲测有效,怎么样忽略其他Java文件的报错,只运行我想运行的某个Java文件的某个函数中的 来到这个页面,看到有三个选项被勾选是正确的: 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
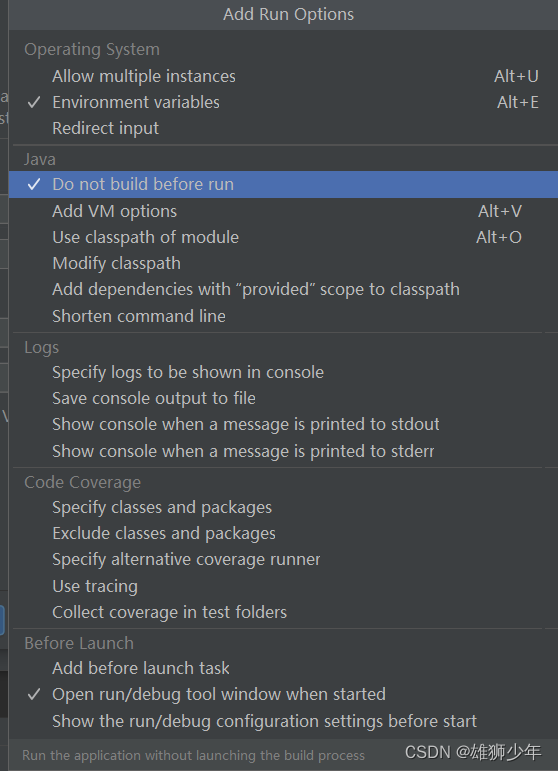
- 您还可以看一下 徐无忌老师的Java进阶高手课-深入浅出Java网络编程课程中的 案例实战:浏览器打开一个网址,整个过程是怎么样的?小节, 巩固相关知识点
- 以下回答来自chatgpt:
答案:
可以使用Java自带的BufferedReader和FileReader来读取数据文件,将读取的内容存储到HashMap中。对于第二列可能存在重复数据的情况,可以将数据读入到HashMap时,将第二列数据作为key值,第一列数据作为value值存储到HashMap中,这样就可以方便地根据第二列数据进行查找和处理。代码如下:
import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.util.HashMap; public class LoadData { public static void main(String[] args) throws IOException { // 读取数据文件 File file = new File("data.txt"); BufferedReader reader = new BufferedReader(new FileReader(file)); String line = null; HashMap<String, Integer> map = new HashMap<>(); // 解析并存储内容到map中 while((line = reader.readLine()) != null) { String[] arr = line.split(","); if(arr.length == 2) { // 确认数据格式正确,防止出现异常 String key = arr[1]; // 第二列数据作为key值 int value = Integer.parseInt(arr[0]); // 第一列数据作为value值 if(!map.containsKey(key)) { // 如果key值不存在,则直接存入 map.put(key, value); } else { // 如果key值已经存在,则需要判断是否需要更新value值 int oldValue = map.get(key); if(value > oldValue) { // 取最大值 map.put(key, value); } } } } reader.close(); // 输出结果 for(String key : map.keySet()) { System.out.println(key + ": " + map.get(key)); } } }对于数据文件格式不正确的情况,代码中做了一定的判断,确认数据格式正确后再进行存储。对于第二列数据重复的情况,代码中使用了HashMap来去除重复值。对于重复的key值,使用了一个简单的逻辑来判断是否需要更新value值,取第一列数据的最大值作为存储结果。最后输出字典中的结果。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
给你个思路,每一行用split拆分两列数据,然后你可以看看第一列的字符串是否已经存在于字典,检查就用之前提过的containsKey来检查,存在就覆盖原有的值,不存在就作为键插入字典。
可以使用Java中的HashMap来加载数据文件中的数据,并将其中一列作为键(key),另一列作为值(value)。HashMap允许存储键值对,并且在插入时会自动去除重复的键。
下面是一个示例代码,演示了如何读取数据文件并将数据加载到HashMap中:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
public class DataFileLoader {
public static void main(String[] args) {
// 创建一个HashMap用于存储数据
HashMap<String, String> dataMap = new HashMap<>();
try {
// 读取数据文件
BufferedReader reader = new BufferedReader(new FileReader("data.txt"));
String line;
while ((line = reader.readLine()) != null) {
// 将每行数据按照分隔符进行拆分
String[] columns = line.split("\t");
if (columns.length >= 2) {
String key = columns[0];
String value = columns[1];
// 将数据存储到HashMap中
dataMap.put(key, value);
}
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
// 打印HashMap中的数据
for (String key : dataMap.keySet()) {
String value = dataMap.get(key);
System.out.println("Key: " + key + ", Value: " + value);
}
}
}
在上面的代码中,我们假设数据文件的每行由制表符分隔为两列,并且数据文件名为"data.txt"。您可以根据实际情况进行调整。代码将逐行读取数据文件,并使用split方法将每行数据拆分为键和值。然后,将键值对存储到HashMap中。最后,通过遍历HashMap来打印存储的数据。