关于#python#的问题,请各位专家解答!
哪里有问题呀,看了半天没发现问题啊?很,请各位看看 谢谢大家了,不知道哪里出错了

你自己定义了一个 max 方法,该方法接收了参数 k
问题是,你的 map 中,使用了 nums 作为参数传递,而传递到 max 的时候,是 nums 的迭代子项,也就是数字,没有 len 方法了
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7532355
- 你也可以参考下这篇文章:开发猜数字小游戏,计算机随机生成100以内的数字,玩家去猜,如果猜的数字过大或过小都会给出提示,直到猜中该数,显示“恭喜!你猜对了”,同时要统计玩家猜的次数。
- 你还可以看下python参考手册中的 python- 定义扩展类型:已分类主题- 对象展示
- 除此之外, 这篇博客: python爬虫基础篇一,理解思路一看就会中的 相信有许多人都向往代码给人带来的魅力,今天带大家入门爬虫,感受一下,代码的快乐 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
大家应该都听过爬虫,但是什么是爬虫呢?
其实可以了解为:通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程
爬虫可以做什么呢?
1、收集数据 2、调研 3、刷流量和秒杀 当然更多是为了就业,赚取很多的玛尼了。爬虫究竟是合法还是违法的?
爬虫在法律中是不被禁止的
但是具有违法风险,就比如你有一把水果刀,你用来削水果当然不违法哈,但是你用来捅人,那事情就大了,你肯定就要进局子了。
这就分为了善意爬虫 和恶意爬虫 看你怎么利用自己所学到的知识了那我们该如何避免进局子呢?
咱们就应该时常的优化自己的程序,避免干扰被访问网站的正常运行
在使用,传播爬取到数据时,审查抓取到的内容,如果发现设计用户隐私或者商业机密等敏感内容要及时停止和传播爬虫在使用场景中的分类
通用爬虫:
抓取系统重要组成部分。抓取的是一整张页面数据。
聚焦爬虫:
是建立在通用爬虫的基础之上,抓取的是页面中特定的局部内容。
增量式爬虫:
监测网站中更新的情况,只会抓取网站中最新更新出来的数据反爬机制
门户网站,可以通过制定相应的策略或者阻止手段,防止爬虫程序进行数据的爬取。反反爬策略
爬虫程序也可以制定相关的策略,破解门户网站中具备的反爬机制,从而获取门户网站中相关的数据Robots.txt 协议
君子协议。规定了网站哪些数据可爬,哪些不可爬http协议
概念:就是服务器和客户端进行数据交互的一种形式。常用请求头信息
User_Agent:表示请求载体的身份标识
Connection:表示请求完毕后,是断开连接还是保持连接
常用相应头信息
Content-Type:服务器 响应回客户端的数据类型Https协议:
概念:安全的超文本传输协议(涉及到数据加密)好啦,大家了解到了爬虫的基本概念,那就开始进入正题,开始进行爬虫练习!
首先我们要知道怎么进行爬取页面
我给大家列取一下爬虫五步曲,记住基本的思路,然后慢慢用代码实现就好了(我这里使用的requests模块,也是比较不错的模块,简洁好上手)
#先导入包,requests #指定url #发起请求 #获取响应数据 #持续化存储把思路记住,代码交给我来实现。你们只管看,然后再动手操作。
今天就爬取个百度页面入门吧,我会持续更新。
首先打开百度,复制百度的链接,地址用url表示
#1.先导入包,requests import requests #要实现的需求,爬取百度页面 #2.指定url url = "https://www.baidu.com/" #3.发起请求 get方法会返回一个响应对象 response = requests.get(url= url) #对获取的到内容,设置编码:防止中文乱码 response.encoding = 'utf-8' #4.获取响应数据 page_text = response.text print(page_text)#输出获取到的数据 #5.持续化存储 with open("./baidu.html",'w',encoding='GBK')as fp: #保存获取到的数据到本地,存为html文件 fp.write(page_text) print("爬取数据结束")
短短几行代码按照思路一步步写入并补充,就能得到百度的页面了,这里我们还要补充一个知识点
我们还需要写入一个伪装头,代表是浏览器正常访问,不然会被检测到,如果人家知道你是来爬虫的,可能会拒绝你的访问伪装头可以在百度页面的基础上按F12或者右键检查,都可以进入调试页面。
根据图示,找到伪装头 User-Agent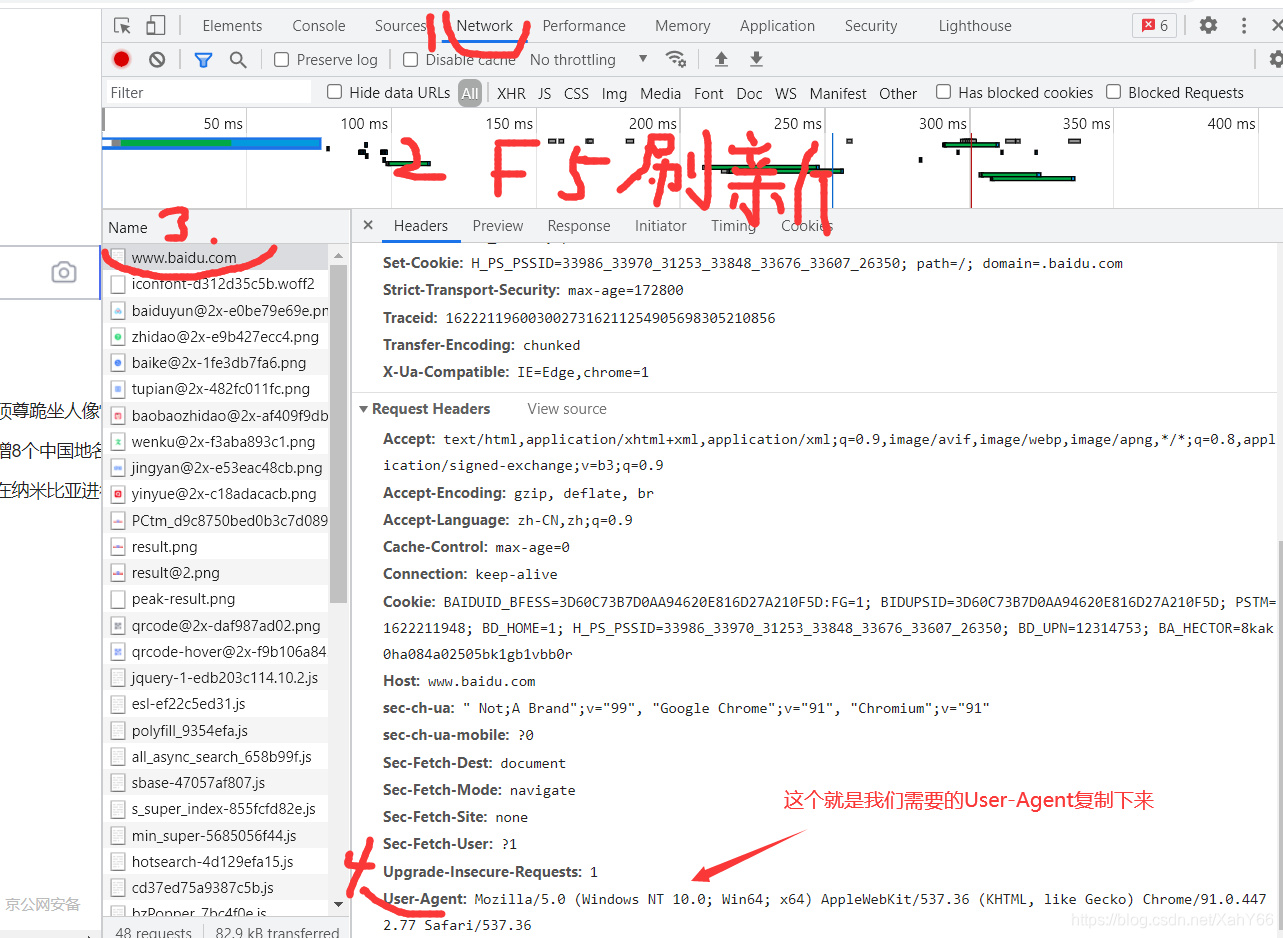
#1.先导入包,requests import requests #要实现的需求,爬取百度页面 #把伪装头复制进来,整个代码就完成了 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36", 'Connection': 'keep-alive' } #2.指定url url = "https://www.baidu.com/" #3.发起请求 get方法会返回一个响应对象 response = requests.get(url= url,headers=headers) #使用伪装头,发送请求 #对获取的到内容,设置编码:防止中文乱码 response.encoding = 'utf-8' #4.获取响应数据 page_text = response.text print(page_text)#输出获取到的数据 #5.持续化存储 with open("./baidu.html",'w',encoding='utf-8')as fp: #保存获取到的数据到本地,存为html文件 fp.write(page_text) print("爬取数据结束")现在就实现了此次需求,大家多多精进,练习巩固
快去试试康康吧
- 您还可以看一下 jeevan老师的Python量化交易,大操手量化投资系列课程之内功修炼篇课程中的 讲师简介,量化交易介绍及自动化交易演示小节, 巩固相关知识点
- 以下回答来自chatgpt:
请提供您的具体代码或描述您的具体问题,以便我们专家能够更好地理解您的问题并提供解决方案。同时,请确保您已经安装了 OpenAI API 客户端库,并已经获取了 API 密钥。如果您遇到任何错误,请提供出现的错误消息以帮助我们更好地解决您的问题。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^