Redis获取HASH的数量
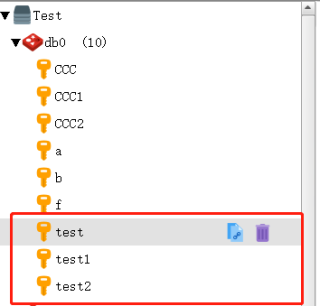
如图,如何判断Redis的表中,哈希名包含“test"的哈希数量?项目中需要用到,要拿取到HASH的数量,然后读取每一个HASH中指定Key的值,查了半天好像没有这种操作,难道是我想错了吗?用的是CSRedisCore库
要判断Redis表中哈希名包含“test”的哈希数量,可以使用Redis的SCAN命令来实现。SCAN命令可以迭代Redis数据库中的所有key,返回符合指定模式的key列表。
具体来说,可以使用SCAN命令迭代Redis数据库中所有的key,并过滤出哈希名包含“test”的key。然后,遍历这些key,并使用HLEN命令获取每个哈希表中的键值对数量。最后,将这些数量累加起来即可得到所有哈希表中键值对数量之和。
以下是使用Redis的Python客户端redis-py实现这个功能的示例代码:
import redis
r = redis.Redis(host='localhost', port=6379)
count = 0
cursor = 0
pattern = '*test*'
while True:
cursor, keys = r.scan(cursor, pattern)
for k in keys:
count += r.hlen(k)
if cursor == 0:
break
print("包含'test'的哈希数量:", len(keys))
print("所有哈希表中键值对数量之和:", count)
在上面的代码中,使用了Redis的SCAN命令来迭代Redis数据库中所有的key,并过滤出哈希名包含“test”的key。然后,使用hlen命令获取每个哈希表中的键值对数量,并将其累加到count变量中。最后,输出包含“test”的哈希数量和所有哈希表中键值对数量之和。
回答整理自chatgpt,如果有帮助麻烦采纳一下,谢谢啦
- 这篇博客: 2019Java高频面试题中的 redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
redis cluster 介绍自动将数据进行分片,每个 master 上放一部分数据提供内置的高可用支持,部分 master 不可用时,还是可以继续工作的在 redis cluster 架构下,每个 redis 要放开两个端口号,比如一个是 6379,另外一个就是 加1w 的端口号,比如 16379。16379 端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用了另外一种二进制的协议,gossip 协议,用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间。节点间的内部通信机制基本通信原理集群元数据的维护有两种方式:集中式、Gossip 协议。redis cluster 节点间采用 gossip 协议进行通信。集中式是将集群元数据(节点信息、故障等等)几种存储在某个节点上。集中式元数据集中存储的一个典型代表,就是大数据领域的 storm。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper(分布式协调的中间件)对所有元数据进行存储维护。zookeeper-centralized-storageredis 维护集群元数据采用另一个方式, gossip 协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。redis-gossip集中式的好处在于,元数据的读取和更新,时效性非常好,一旦元数据出现了变更,就立即更新到集中式的存储中,其它节点读取的时候就可以感知到;不好在于,所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储有压力。gossip 好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续打到所有节点上去更新,降低了压力;不好在于,元数据的更新有延时,可能导致集群中的一些操作会有一些滞后。10000 端口:每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如 7001,那么用于节点间通信的就是 17001 端口。每个节点每隔一段时间都会往另外几个节点发送 ping 消息,同时其它几个节点接收到 ping 之后返回 pong。交换的信息:信息包括故障信息,节点的增加和删除,hash slot 信息等等。gossip 协议gossip 协议包含多种消息,包含 ping,pong,meet,fail 等等。meet:某个节点发送 meet 给新加入的节点,让新节点加入集群中,然后新节点就会开始与其它节点进行通信。redis-trib.rb add-node其实内部就是发送了一个 gossip meet 消息给新加入的节点,通知那个节点去加入我们的集群。ping:每个节点都会频繁给其它节点发送 ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping 交换元数据。pong:返回 ping 和 meeet,包含自己的状态和其它信息,也用于信息广播和更新。fail:某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说,某个节点宕机啦。ping 消息深入ping 时要携带一些元数据,如果很频繁,可能会加重网络负担。每个节点每秒会执行 10 次 ping,每次会选择 5 个最久没有通信的其它节点。当然如果发现某个节点通信延时达到了 cluster_node_timeout / 2,那么立即发送 ping,避免数据交换延时过长,落后的时间太长了。比如说,两个节点之间都 10 分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题。所以 cluster_node_timeout 可以调节,如果调得比较大,那么会降低 ping 的频率。每次 ping,会带上自己节点的信息,还有就是带上 1/10 其它节点的信息,发送出去,进行交换。至少包含 3 个其它节点的信息,最多包含 总节点数减 2 个其它节点的信息。分布式寻址算法hash 算法(大量缓存重建)一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)redis cluster 的 hash slot 算法hash 算法来了一个 key,首先计算 hash 值,然后对节点数取模。然后打在不同的 master 节点上。一旦某一个 master 节点宕机,所有请求过来,都会基于最新的剩余 master 节点数去取模,尝试去取数据。这会导致大部分的请求过来,全部无法拿到有效的缓存,导致大量的流量涌入数据库。hash一致性 hash 算法一致性 hash 算法将整个 hash 值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,下一步将各个 master 节点(使用服务器的 ip 或主机名)进行 hash。这样就能确定每个节点在其哈希环上的位置。来了一个 key,首先计算 hash 值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,遇到的第一个 master 节点就是 key 所在位置。在一致性哈希算法中,如果一个节点挂了,受影响的数据仅仅是此节点到环空间前一个节点(沿着逆时针方向行走遇到的第一个节点)之间的数据,其它不受影响。增加一个节点也同理。燃鹅,一致性哈希算法在节点太少时,容易因为节点分布不均匀而造成缓存热点的问题。为了解决这种热点问题,一致性 hash 算法引入了虚拟节点机制,即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。consistent-hashing-algorithmredis cluster 的 hash slot 算法redis cluster 有固定的 16384 个 hash slot,对每个 key 计算 CRC16 值,然后对 16384 取模,可以获取 key 对应的 hash slot。redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot。hash slot 让 node 的增加和移除很简单,增加一个 master,就将其他 master 的 hash slot 移动部分过去,减少一个 master,就将它的 hash slot 移动到其他 master 上去。移动 hash slot 的成本是非常低的。客户端的 api,可以对指定的数据,让他们走同一个 hash slot,通过 hash tag 来实现。任何一台机器宕机,另外两个节点,不影响的。因为 key 找的是 hash slot,不是机器。hash-slotredis cluster 的高可用与主备切换原理redis cluster 的高可用的原理,几乎跟哨兵是类似的。判断节点宕机如果一个节点认为另外一个节点宕机,那么就是 pfail,主观宕机。如果多个节点都认为另外一个节点宕机了,那么就是 fail,客观宕机,跟哨兵的原理几乎一样,sdown,odown。在 cluster-node-timeout 内,某个节点一直没有返回 pong,那么就被认为 pfail。如果一个节点认为某个节点 pfail 了,那么会在 gossip ping 消息中,ping 给其他节点,如果超过半数的节点都认为 pfail 了,那么就会变成 fail。从节点过滤对宕机的 master node,从其所有的 slave node 中,选择一个切换成 master node。检查每个 slave node 与 master node 断开连接的时间,如果超过了 cluster-node-timeout * cluster-slave-validity-factor,那么就没有资格切换成 master。从节点选举每个从节点,都根据自己对 master 复制数据的 offset,来设置一个选举时间,offset 越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举。所有的 master node 开始 slave 选举投票,给要进行选举的 slave 进行投票,如果大部分 master node(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成 master。从节点执行主备切换,从节点切换为主节点。与哨兵比较整个流程跟哨兵相比,非常类似,所以说,redis cluster 功能强大,直接集成了 replication 和 sentinel 的功能。
- 以下回答由chatgpt基于相关博客总结生成:
我会解决该问题。
要获取Redis中哈希表中包含特定字符串"test"的数量,需要使用Redis的SCAN命令配合特定的参数。具体步骤如下:
- 首先,在Redis客户端中使用scan命令来获取哈希表中的所有键值对(key-value pairs),并且加入MATCH参数来过滤包含特定字符串"test"的键值对。命令如下:
SCAN cursor [MATCH pattern] [COUNT count]其中,cursor代表遍历游标,是一个整数,初始值可为0;MATCH代表匹配模式,可以指定需要的键值对的模式;COUNT指定每次遍历需要返回的键值对数量。
例如:
SCAN 0 MATCH '*test*' COUNT 100这个命令将会返回第一批匹配指定字符串的键值对,如果返回值中有第二个元素,说明还有更多键值对需要遍历,那么可以使用上一个命令返回的cursor继续遍历。
- 对于每个匹配到的哈希表,使用HGETALL命令获取该哈希表中的所有键值对,并且判断该哈希表中是否包含特定的键。如果包含,累加到特定字符串包含的哈希表数量中。
命令如下:
HGETALL key这个命令将会返回键值对的列表,每两个相邻的元素是一对键值对。需要遍历这个列表,然后判断是否存在特定的键。
- 最终,获取到特定字符串包含的哈希表数量后,可以读取每个哈希表中特定键的值。需要使用HGET命令获取指定键的值。
命令如下:
HGET key field其中,key是哈希表的名称,field是需要获取的键的名称。这个命令将会返回指定键的值。
例如,要获取名为"person:1"的哈希表中"age"键的值,可以使用以下命令:
HGET person:1 age这个命令将会返回"18"这个字符串,表示"age"键的值为18岁。
总结起来,可以使用以下伪代码来实现获取特定字符串包含的哈希表数量以及读取每个哈希表中特定键的值的操作:
def get_hash_count_and_values(redis_client, match_str, key_to_get): # 初始化计数器及结果列表 count = 0 values = [] # 执行scan命令,遍历所有包含特定字符串的键值对 cursor = 0 while True: cursor, keys = redis_client.scan(cursor=cursor, match='*{}*'.format(match_str)) for key in keys: # 对于每个符合条件的键值对,执行HGETALL命令获取哈希表的所有键值对 hash_dict = redis_client.hgetall(key) # 判断该哈希表中是否包含需要的键 if key_to_get in hash_dict: count += 1 # 对于包含需要的键的哈希表,执行HGET命令获取指定键的值 value = redis_client.hget(key, key_to_get) values.append(value) if cursor == 0: # 遍历完所有键值对,退出循环 break # 返回特定字符串包含的哈希表数量以及读取到的哈希表中特定键的值的列表 return count, values需要注意的是,以上代码仅为伪代码,可能存在语法错误或者细节问题,需要具体实现时根据实际情况进行调整。
要判断Redis中哈希名包含特定字符串的哈希数量,可以使用Redis的SCAN命令结合Python的redis-py库来实现。下面是一个示例代码:
import redis
# 连接到Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# 定义匹配的哈希名
pattern = '*test*'
# 初始化游标
cursor = 0
count = 0
# 使用SCAN命令遍历哈希表
while True:
# 执行SCAN命令
cursor, keys = r.scan(cursor, match=pattern)
# 统计匹配的哈希数量
count += len(keys)
# 如果游标为0,表示遍历完成
if cursor == 0:
break
# 输出匹配的哈希数量
print(f"The number of hashes with '{pattern}' in their names is: {count}")
在上面的代码中,首先使用redis.Redis()函数连接到Redis数据库。然后,定义了一个匹配的哈希名的模式,即pattern变量。接下来,使用scan()方法结合循环来遍历哈希表,每次遍历都会返回一个游标和匹配的哈希名列表。通过统计匹配的哈希名列表的长度,可以得到匹配的哈希数量。当游标为0时,表示遍历完成,退出循环。最后,使用print()函数输出匹配的哈希数量。
需要注意的是,需要先安装redis-py库,可以使用pip install redis命令进行安装。另外,需要根据实际情况修改连接Redis的参数,如host和port等。