用python实现感知器模型
用python实现感知器模型

探索损失函数在每一步中是如何变化的。确保您可以确定/更改在每个步骤错误分类的数据点,使得可以生成多个超平面。
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7744649
- 这篇博客你也可以参考下:【期末课设】python爬虫基础与可视化,使用python语言以及支持python语言的第三方技术实现爬虫功能,定向爬取网页的图片数据,并且实现批量自动命名分类下载。
- 你还可以看下python参考手册中的 python- 错误输出重定向和程序终止
- 除此之外, 这篇博客: 桌面太单调?一起用Python做个自定义动态壁纸,竟然还可以放视频!中的 2. 视频加载预览 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
接来下我们可以根据自己喜欢的视频,从本地读取视频,并且将视频预览播放显示。这里视频演示,博主还是用之前的那篇紫颜小姐姐的跳舞视频进行演示。
读取视频:
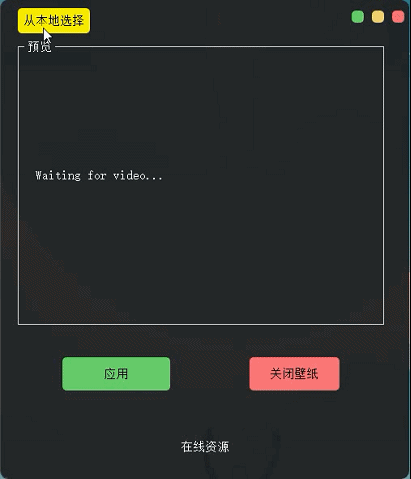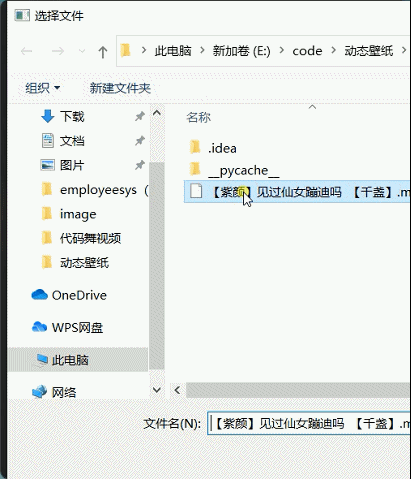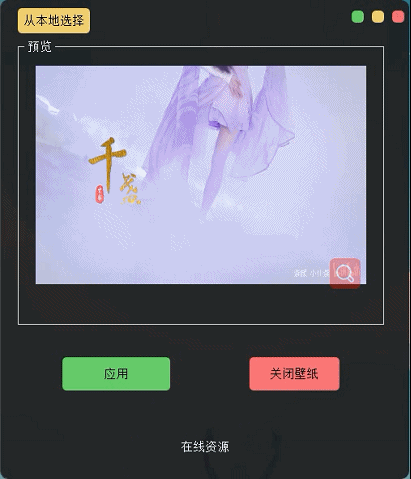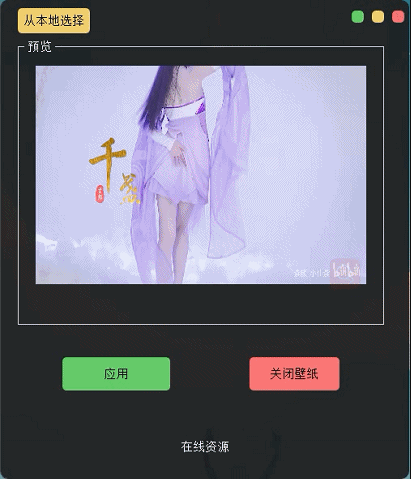
读取视频我们可以通过打开文件对话框,选择视频资源,开启一个子线程用来进行视频开启停止播放。核心代码如下:
# author: CSDN-Dragon少年 def openmp4(self): try: global path path, filetype = QFileDialog.getOpenFileName(None, "选择文件", '.', "视频文件(*.AVI;*.mov;*.rmvb;*.rm;*.FLV;*.mp4;*.3GP)") # ;;All Files (*) if path == "": # 未选择文件 return self.slotStart() t = Thread(target=self.Stop) t.start() # 启动线程,即让线程开始执行 except Exception as e: print (e)视频流读取播放:
接下来,我们需要对视频文件进行按帧读取加载显示,并通过计时器实现动画效果。核心代码如下:
# author:CSDN-Dragon少年 def slotStart(self): videoName = path if videoName != "": # “”为用户取消 self.cap = cv2.VideoCapture(videoName) self.timer_camera.start(50) self.timer_camera.timeout.connect(self.openFrame)# author:CSDN-Dragon少年 def openFrame(self): if (self.cap.isOpened()): ret, self.frame = self.cap.read() if ret: frame = cv2.cvtColor(self.frame, cv2.COLOR_BGR2RGB) if self.detectFlag == True: # 检测代码self.frame self.label_num.setText("There are " + str(5) + " people.") height, width, bytesPerComponent = frame.shape bytesPerLine = bytesPerComponent * width q_image = QImage(frame.data, width, height, bytesPerLine, QImage.Format_RGB888).scaled(self.label.width(), self.label.height()) self.label.setPixmap(QPixmap.fromImage(q_image)) else: self.cap.release() self.timer_camera.stop() # 停止计时器至此,我们已经可以实现视频读取加载,并且进行视频预览了,效果如下:
- 您还可以看一下 jeevan老师的Python量化交易,大操手量化投资系列课程之内功修炼篇课程中的 编程语言之Python环境安装小节, 巩固相关知识点
用python实现感知器模型
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import ListedColormap
#from sklearn.linear_model import Perceptron
import Perceptron as perceptron_class
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
df.tail()
#抽取出前100条样本,这正好是Setosa和Versicolor对应的样本,我们将Versicolor对应的数据作为类别1,Setosa对应的作为-1。
# 对于特征,我们抽取出sepal length和petal length两维度特征,然后用散点图对数据进行可视化
#We extract the first 100 class labels that correspond to 50 Iris-Setosa and 50 Iris-Versicolor flowers.
y = df.iloc[0:100, 4].values
print(y)
y = np.where(y == 'Iris-setosa', -1, 1)#满足条件(condition),输出x,不满足输出y。
print(y)
X = df.iloc[0:100, [0, 2]].values
print(X)
print(X.shape,y.shape)#(100,2) (100,)
plt.scatter(X[:50, 0], X[:50, 1],color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1],color='blue', marker='x', label='versicolor')
plt.xlabel('sepal length')
plt.ylabel('petal length')
plt.legend(loc='upper left')
plt.show()
#这里是对于感知机模型进行训练
ppn = perceptron_class.Perceptron(eta=0.1, n_iter=10)
ppn.fit(X, y) #画出分界线
#To train our perceptron algorithm, plot the misclassification error
plt.plot(range(1,len(ppn.errors_) + 1), ppn.errors_, marker='o')
plt.xlabel('Epochs')
plt.ylabel('Number of misclassifications')
plt.show()
#Visualize the decision boundaries for 2D datasets
def plot_decision_regions(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
print(xx1)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class samples
for idx, cl in enumerate(np.unique(y)):#除其中重复的元素,并按元素由大到小返回一个新的无元素重复的元组或者列表
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],alpha=0.8, c=cmap(idx), marker=markers[idx],label=cl)
plot_decision_regions(X, y, classifier=ppn)
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
plt.show()
#Adaptive linear neurons and the convergence of learning Implementing an Adaptive Linear Neuron in Python
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(8,4))
ada1 = perceptron_class.AdalineGD(n_iter=10, eta=0.01).fit(X,y)
ax[0].plot(range(1, len(ada1.cost_) + 1), np.log10(ada1.cost_), marker='o')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('log(Sum-squared-error)')
ax[0].set_title('Adaline - Learning rate 0.01')
ada2 = perceptron_class.AdalineGD(n_iter=10, eta=0.0001).fit(X,y)
ax[1].plot(range(1, len(ada2.cost_) + 1), ada2.cost_, marker='o')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Sum-squared-error')
ax[1].set_title('Adaline - Learning rate 0.0001')
plt.show()
#standardization
X_std = np.copy(X)
X_std[:,0] = (X_std[:,0] - X_std[:,0].mean()) / X_std[:,0].std()
X_std[:,1] = (X_std[:,1] - X_std[:,1].mean()) / X_std[:,1].std()
ada = perceptron_class.AdalineGD(n_iter=15, eta=0.01)
ada.fit(X_std, y)
plot_decision_regions(X_std, y, classifier=ada)
plt.title('Adaline - Gradient Descent')
plt.xlabel('sepal length [standardized]')
plt.ylabel('petal length [standardized]')
plt.legend(loc='upper left')
# plt.show()
plt.plot(range(1, len(ada.cost_) + 1), ada.cost_, marker='o')
plt.xlabel('Epochs')
plt.ylabel('Sum-squared-error')
plt.show()
#Large scale machine learning and stochastic gradient descent
ada = perceptron_class.AdalineSGD(n_iter=15, eta=0.01, random_state=1)
ada.fit(X_std, y)
plot_decision_regions(X_std, y, classifier=ada)
plt.title('Adaline - Stochastic Gradient Descent')
plt.xlabel('sepal length [standardized]')
plt.ylabel('petal length [standardized]')
plt.legend(loc='upper left')
plt.show()
plt.plot(range(1, len(ada.cost_) + 1), ada.cost_, marker='o')
plt.xlabel('Epochs')
plt.ylabel('Average Cost')
plt.show()
要探索损失函数在每一步中的变化,您可以在训练过程中记录每一步的错误分类数据点数量。例如,在训练方法的内部添加一个列表errors_per_epoch,每个epoch结束时将错误分类的数据点数量添加到该列表中。这样,您就可以在训练完成后通过绘制errors_per_epoch来观察损失函数在每一步中的变化。
另外,为了生成多个超平面,您可以使用不同的随机初始化权重和偏置,或者对输入数据进行随机扰动,从而获得不同的决策边界。这样可以在不同的训练迭代中获得不同的结果。