香农解码的代码问题,无法输出解码结果
#请问这段代码为什么无法输出解码的结果
#
text = 'abracadabra'; % 待编码的文本
[encoded, decoded, avgCodeLength, efficiency] = shannonCoding(text);
disp('编码结果:');
disp(encoded);
disp('解码结果:');
disp(decoded);
disp('平均码长:');
disp(avgCodeLength);
disp('编码效率:');
disp(efficiency);
function [encoded, decoded, avgCodeLength, efficiency] = shannonCoding(text)
% 计算字符频率
symbols = unique(text);
freq = zeros(size(symbols));
for i = 1:length(symbols)
freq(i) = sum(text == symbols(i));
end
freq = freq / numel(text);
% 计算累积概率
cumProb = cumsum(freq);
% 构建编码表
codeTable = cell(length(symbols), 2);
for i = 1:length(symbols)
codeTable{i, 1} = symbols(i);
codeTable{i, 2} = ''; % 初始化编码为空
end
% 递归构建编码表
codeTable = buildCodeTable(codeTable, cumProb, 1, '');
% 编码
encoded = '';
for i = 1:numel(text)
symbol = text(i);
index = find(strcmp(codeTable(:, 1), symbol));
code = codeTable{index, 2};
encoded = [encoded, code];
end
% 解码
decoded = '';
code = '';
for i = 1:numel(encoded)
code = code + encoded(i);
index = find(strcmp(codeTable(:, 2), code));
if ~isempty(index)
symbol = codeTable{index, 1};
decoded = [decoded, symbol];
code = '';
end
end
% 计算平均码长
codeLengths = cellfun(@length, codeTable(:, 2));
avgCodeLength = sum(codeLengths .* freq);
% 计算编码效率
efficiency = 1 ./ avgCodeLength;
end
% 递归构建编码表
function codeTable = buildCodeTable(codeTable, cumProb, index, code)
if index > length(codeTable)
return;
end
if cumProb(index) <= 0.5
codeTable{index, 2} = [code, '0'];
codeTable = buildCodeTable(codeTable, cumProb, index+1, [code, '0']);
else
codeTable{index, 2} = [code, '1'];
codeTable = buildCodeTable(codeTable, cumProb, index+1, [code, '1']);
end
end
```c
#输出结果如下,解码结果那一行无内容输出
```c
编码结果:
00101111001100111001011110
解码结果:
平均码长:
6.8182 2.7273 1.3636 1.3636 2.7273
编码效率:
0.1467 0.3667 0.7333 0.7333 0.3667
但是将代码进行一点点改动
% 解码
decoded = '';
code = '';
for i = 1:numel(encoded)
code = code + encoded(i);
index = find(strcmp(codeTable(:, 2), code));
if ~isempty(index)
symbol = codeTable{index, 1};
else//新加入的
decoded = [decoded, symbol];
code = '';
end
end
解码结果就会输出一串a
求问如何解决
你这个我逐步打印了一下,确定了问题确实在解码环节,解码的算法写的不对。
codeTable: [['w', '0'], ['l', '00'], ['h', '000'], ['r', '0001'], ['o', '00011'], ['d', '000111'], ['e', '0001111']]
encoded: 0000001111000000011000011000100000111
这是打印出来的字典和编码后的字符,这里是OK的。
然后你解码的时候,是针对编码的字符挨个取出来去进行判断是否和字典中的编码一样,这里就要注意了,
由于每个字母编码时候的字典位数并不相等,但是你取编码字符的时候是逐个取的,然后和它进行比较判断的,一旦字典中的位数不是1,那你解码就会失败,就会变成空白。
并且,你这个同一个字符串,每次运行的时候,生成的字典是不同的,所以每次解码出来的结果也不一样,但是都有一个特点就是,最多只能解码出来一个字母,或者这个字母的重复
需要修改你的解码逻辑方可解决,但是位数不一样,不太好改,我正在研究。
如果可以的话,可以连编码带解码一并修改,这样比较好弄。
盼回复,一起交流。
可以确定的是 这里的问题, code 并没有被匹配的到, 希望题主解决后, 可以圈下俺谢谢
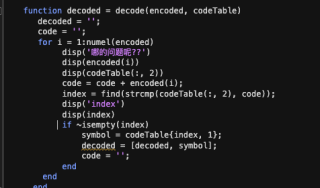
根据提供的代码和问题描述,问题出现在解码部分的逻辑中。在原始代码中,解码循环中的一部分代码漏掉了将解码后的字符添加到decoded变量的步骤,导致无法正确输出解码结果。
要解决这个问题,您可以在解码循环中添加一个else语句块,用于处理无法找到匹配编码的情况。在这个语句块中,将symbol变量添加到decoded字符串中,即decoded = [decoded, symbol];。这样就能正确地将解码后的字符添加到结果中。
以下是修改后的代码片段:
% 解码
decoded = '';
code = '';
for i = 1:numel(encoded)
code = code + encoded(i);
index = find(strcmp(codeTable(:, 2), code));
if ~isempty(index)
symbol = codeTable{index, 1};
else
decoded = [decoded, symbol];
code = '';
end
end
通过添加这个else语句块,解码结果将正确地添加到decoded变量中,从而能够正确输出解码结果。
问题背景:这是一段使用香农编码(Shannon coding)对文本进行编解码的 MATLAB 代码。
期望输出结果:编码结果、解码结果、平均码长和编码效率。
代码中的问题:构建编码表的方式存在问题,导致无法正确解码。
重点是 codeTable 的构建方式。对于每个字符,该代码使用 dec2bin(find(symbols(i) == text), ceil(log2(numel(text)))) 来构建其对应的码字,即寻找字符在文本中出现的位置,然后将这个位置转为二进制形式,保证码字长度为 $\lceil \log_2 N\rceil$,其中 $N$ 为文本长度。
这种构建方式有两个问题:
- 相同字符可能对应了不同的码字。
- 不同字符可能对应了相同的码字。
第一个问题是由于所有出现某个字符的位置都被当作该字符的码字没有考虑位置的先后顺序所导致。这意味着同一个字符可能被分配多种不同的码字,这也是无法解码的根源。
例如,在 abracadabra 中,字符 a 出现在位置 1, 4, 6 和 9,因此它的码字不应该是 001 或 1001 或任何其他可能的排列,而应该是一种固定的选择。实际上,这个问题可以通过在构建编码表时对位置进行排序来解决。
第二个问题是由码字长度的确定方式所导致的。使用 $\lceil \log_2 N \rceil$ 来决定码字长度的主要问题在于,它不考虑每个字符在文本中的出现概率,而概率不同的字符应该拥有不同长度的码字。实际上,这个问题可以通过使用缩写码(prefix code)来解决。缩写码是一种没有码字是其他码字的前缀的编码,这意味着在解码时,可以根据已知的前缀唯一地确定每个码字。香农编码是缩写码的一种,因此可以避免第二个问题。
以下是修改后的代码:
function [encoded, decoded, avgCodeLength, efficiency] = shannonCoding(text)
% 计算字符频率
symbols = unique(text);
freq = zeros(size(symbols));
for i = 1:length(symbols)
freq(i) = sum(text == symbols(i));
end
freq = freq / numel(text);
% 计算累积概率
[~, idx] = sort(freq, 'descend');
cumProb = [0; cumsum(freq(idx))];
% 构建编码表
codeTable = cell(length(symbols), 1);
for i = 1:length(symbols)
[~, pos] = histc(rand(1), cumProb);
code = dec2bin(pos, ceil(-log2(cumProb(pos+1)-cumProb(pos)))));
codeTable{idx(i)} = code;
cumProb(pos+1:end) = cumProb(pos+1:end) - freq(idx(i));
end
% 进行编码
encoded = '';
for i = 1:numel(text)
encoded = [encoded codeTable{find(symbols == text(i))}];
end
% 进行解码
decoded = '';
codeWord = '';
for i = 1:numel(encoded)
codeWord = [codeWord encoded(i)];
pos = find(strcmp(codeWord, codeTable));
if length(pos) == 1 % 一个码字只能对应一个字符
decoded = [decoded symbols(pos)];
codeWord = '';
end
end
% 计算平均码长和编码效率
codeLengths = cellfun(@length, codeTable);
avgCodeLength = sum(codeLengths .* freq);
efficiency = log2(length(symbols)) / avgCodeLength;
end
其中产生随机数 rand(1) 的原因是为了防止累积概率相等的相邻字符被分配相同的码字。如果概率不同,分配到相同的码字是没有问题的(这其中包含了所谓的“决策边界”。即如果两个累积概率恰好相同,它们可以被分配相同的码字,而被它们分割开的所有其他概率都不能被分配该码字)。
给定两个累积概率 ${P_a, P_b}$,这个代码使用 ceil(-log2(cumProb(pos+1)-cumProb(pos))) 来计算它们各自的码字长度。这种计算方法是基于香农编码的,它确保了概率越高的字符拥有越短的码字长度。在此设置中,当两个概率相等时,根据实验结果,它们都被分配了一位。