你是一名高级测试工程师,现在一个大版本上线了,你作为测试你要做什么工作
你是一名高级测试工程师,现在一个大版本上线了,你作为测试你要做什么工作
做什么?坐等甩锅,哈哈,开玩笑的。
大版本升级:不仅仅是测试要做什么,是所有参与人员都得做测试工作,包括开发、测试、运维、前端等。
上线后需要在线查看你升级的功能是否正常运行。有没有报错啊,后端数据库字段、表等是不是加上了。运维要保证项目是不是正常访问啊~部署等
喂给GPT,让他回答你
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7666894
- 这篇博客你也可以参考下:网络爬虫——豆瓣电影排行榜数据抓取(高级)
- 除此之外, 这篇博客: 三种常用的朴素贝叶斯实现算法——高斯朴素贝叶斯、伯努利朴素贝叶斯、多项式朴素贝叶斯中的 伯努利朴素贝叶斯 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
设试验E只有两个可能的结果:A与A¯,则称为E为伯努利试验。
伯努利朴素贝叶斯,适用于离散变量,其假设各个特征xi在各个类别y下是服从n重伯努利分布(二项分布)的,因为伯努利试验仅有两个结果,因此,算法会首先对特征值进行二值化处理(假设二值化的结果为1与0)。
计算方式如下: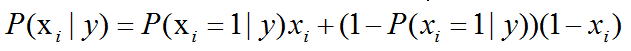
在训练集中,会进行如下的估计: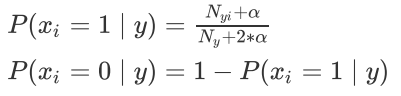

from sklearn.naive_bayes import BernoulliNB np.random.seed(0) x = np.random.randint(-5,5,size=(6,2)) y = np.array([0,0,0,1,1,1]) data = pd.DataFrame(np.concatenate([x,y.reshape(-1,1)], axis=1), columns=['x1','x2','y']) display(data) bnb = BernoulliNB() bnb.fit(x,y) #每个特征在每个类别下发生(出现)的次数。因为伯努利分布只有两个值。 #我们只需要计算出现的概率P(x=1|y),不出现的概率P(x=0|y)使用1减去P(x=1|y)即可。 print('数值1出现次数:', bnb.feature_count_) #每个类别样本所占的比重,即P(y)。注意该值为概率取对数之后的结果, #如果需要查看原有的概率,需要使用指数还原。 print('类别占比p(y):',np.exp(bnb.class_log_prior_)) #每个类别下,每个特征(值为1)所占的比例(概率),即p(x|y) #该值为概率取对数之后的结果,如果需要查看原有的概率,需要使用指数还原 print('特征概率:',np.exp(bnb.feature_log_prob_))
- 您还可以看一下 课工场架构师老师的电商网站高并发秒杀实战课程中的 用户登录优化之统一返回格式(上)小节, 巩固相关知识点