为什么出不来结果 我想知道问题出在哪里了
Python读取文档
代码在学校的电脑上出结果,但是在自己电脑上出不来
刚刚在打前面内容也出结果了,把后面内容注释掉又不出了,也没有显示哪里出错,我想知道是什么原因

1、在第2行中使用了f.read()来读取文件中的所有内容,导致后面的f.readlines()无法读取任何内容。可以将f.read()注释掉或删除它。
2、在第4行中将t初始化为0,但是在后面的循环中,使用f.readlines()来读取文件的所有行,这将导致t的值始终为0,因此循环条件永远不会成立。可以使用f来迭代文件的每一行,而不是使用f.readlines()。
3、在第10行中,使用了strip()来删除每一行的空格和换行符,但是在循环中,您没有使用strip()来删除每一行的空格和换行符。可以将i.strip()改为i.strip('\n')。
with open('doubanTOP250.txt', "r", encoding='utf-8') as f:
n = 0
for i in f:
t = f.tell()
if (t % (5 * 7 * n) == 0):
n = n + 1
print(i.strip('\n'))
txt文件里的数据啥样的
代码中间加一些print的调试语句,看代码在哪里卡住了

这是文本的部分内容
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7772284
- 这篇博客你也可以参考下:采集一幅彩色图像,使用python然后将其转化成灰度图像,分别加入高斯白噪声和椒盐 噪声,再分别进行 3×3 的均值滤波和中值滤波,显示原图像、加噪图像和滤波 结果图像,并比较四种滤波结果。
- 除此之外, 这篇博客: 我通过Python对自己的微信朋友圈进行了可视化分析得到了意想不到的答案中的 最后了,重磅来袭,输出所有朋友圈的头像合成在一张图片上 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
先看下效果图,当然了,我打马赛克了,不然认识的人看见,发现是我写的,那我就准备new一个自己来了。开玩笑,哈哈。
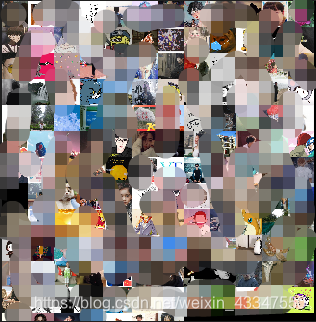
具体实现完整代码如下:import itchat import os import math from PIL import Image # 获取数据 def download_image(): # 扫描二维码登陆微信,即通过网页版微信登陆 itchat.auto_login() # 返回一个包含用户信息字典的列表 friends = itchat.get_friends(update=True) # 在当前位置创建一个用于存储头像的目录wechatImages base_path = 'wechatImages' if not os.path.exists(base_path): os.mkdir(base_path) # 获取所有好友头像 for friend in friends: # 获取头像数据 img_data = itchat.get_head_img(userName = friend['UserName']) #判断备注名是否为空 if friend['RemarkName'] != '': img_name = friend['RemarkName'] else : img_name = friend['NickName'] # 在实际操作中如果文件名中含有*标志,会报错。则直接可以将其替换掉 if img_name is "*": img_name = "" #通过os.path.join()函数来拼接文件名 img_file = os.path.join(base_path, img_name + '.jpg') print(img_file) with open(img_file, 'wb') as file: file.write(img_data) # 拼接头像 def join_image(): base_path = 'wechatImages' files = os.listdir(base_path) #返回指定的文件或文件夹的名字列表 print(len(files)) each_size = int(math.sqrt(float(6400 * 6400) / len(files)))#计算每个粘贴图片的边长 lines = int(6400 / each_size)#计算总共有多少行 print(lines) image = Image.new('RGB', (6400, 6400))# new(mode, size, color=0) 定义一张大小为640*640大小的图片,不给出第三个参数默认为黑色 x = 0 #定义横坐标 y = 0 #定义纵坐标 for file_name in files: img = Image.open(os.path.join(base_path, file_name)) #找到/打开图片 img = img.resize((each_size, each_size), Image.ANTIALIAS)#实现图片同比例缩放,Image.ANTIALIAS添加滤镜效果 image.paste(img, (x * each_size, y * each_size))#将缩放后的照片放到对应的坐标下 x += 1 if x == lines:#如果每行的粘贴内容够了,则换行 x = 0 y += 1 image.save('jointPic.jpg')#最后将全部的照片保存下来 if __name__ == '__main__': # download_image() join_image()写到这本片就完了,我的头发还是那么茂密!

- 您还可以看一下 CSDN就业班老师的Python全栈工程师特训班第十四期-直播回放课程中的 Python全栈工程师特训班第十四期-第十二周-爬虫第三周-01小节, 巩固相关知识点