YOLOv5如何识别标签外其他所有物体
有没有方法就是在图片中我标注的那个东西是一个类别,照片里的其他东西全是另一种类别,然后识别出来。
数据集:您需要一个包含您要识别的物体的数据集。该数据集应包含图像和每个物体的标注边界框。
训练代码:您需要使用适当的深度学习框架(如PyTorch或TensorFlow)编写训练代码。您需要将数据集加载到代码中,定义模型架构,定义损失函数并运行反向传播算法来优化模型参数。
测试图像:您需要一个测试图像,其中包含您要识别的物体以及其他物体。您可以使用预处理脚本将测试图像中的边界框替换为 ground truth 边界框。
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7759768
- 这篇博客也不错, 你可以看下YOLOv5超详细的入门级教程(思考篇)(一)——关于遮挡问题与小目标检测问题
- 除此之外, 这篇博客: yolov5推理出大的错误框--一种简单粗暴但局限的规避方法中的 二。问题描述 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
在
yolov5源码解析(10)--损失计算与anchor_扫地僧1234的博客-CSDN博客的末尾抛出了一个问题,具体可以去看一下那一期的内容(强烈建议去看一下!),简单的说,就是标注的物体a、b有重叠,在训练的时候有可能同一个格子即负责预测物体a,也负责预测物体b。你可能会说这不是很正常吗。
但是如果物体a、b的尺度相差比较大,比如物体a大,物体b小,而物体a、b的中心点比较接近,此时也会发生这种情况,比如下图:

耳塞基本在平板的中间,这样它们的中心点就能归到同一个格子上,那么这个格子就有可能会既负责预测平板,也负责预测耳塞。
注意:
(1)这里说的是有可能,因为除了中心点与格子的关系之外,物体的宽高与anchor的宽高比例不能超过4(超参anchor_t)
(2)也不一定中心点非得落在这个格子, 比如中心点落在格子c里,位置偏左上,那么格子c的左侧格子,上侧格子都会负责预测该物体。
如下图,详见yolov5源码解析(10)--损失计算与anchor_扫地僧1234的博客-CSDN博客
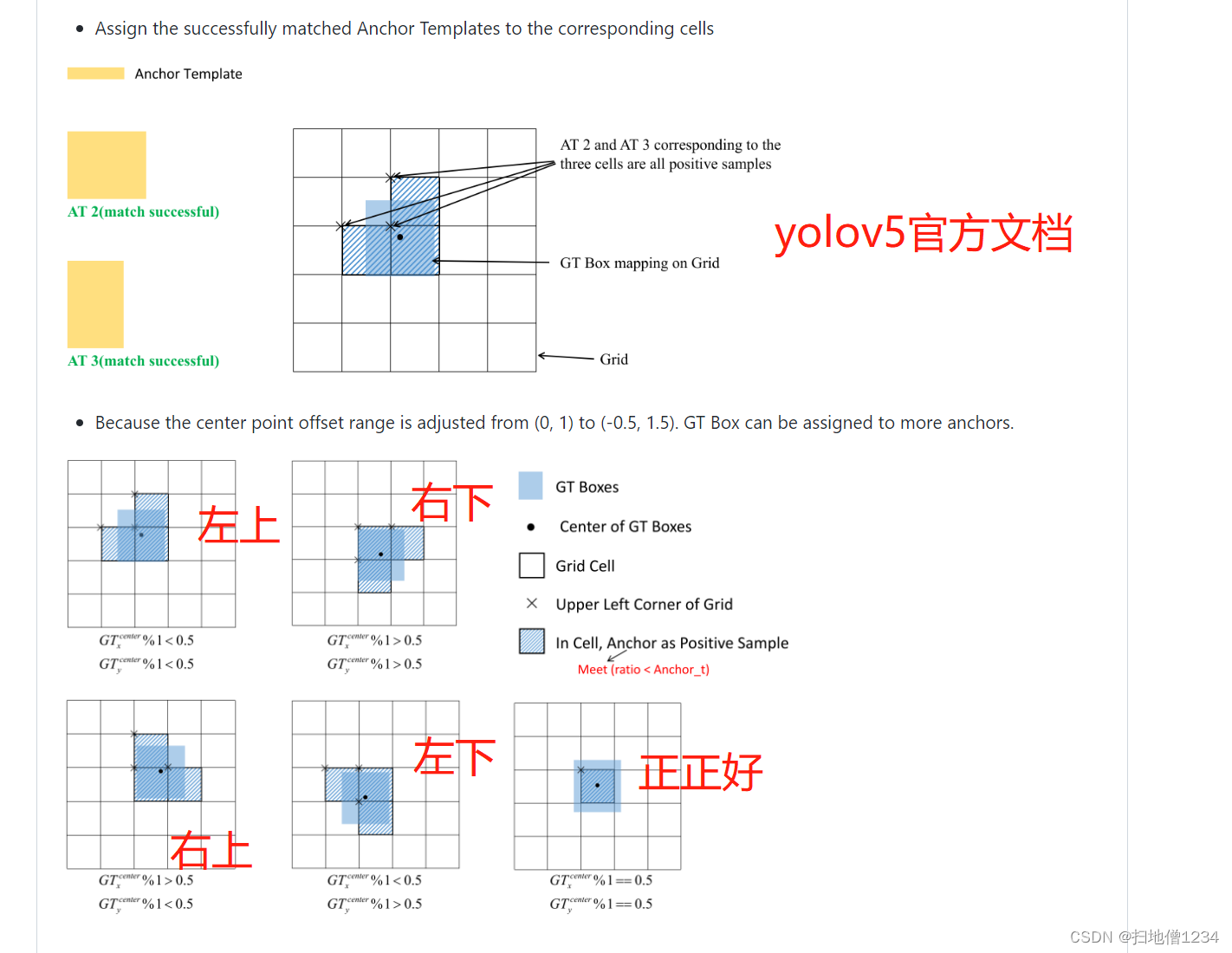
那么如果一个格子既要预测平板,又要预测耳塞会有什么问题呢:
(1)显然在非多标签分类的情况下,这个格子不管是预测平板还是预测耳塞的分类得分都会被抑制,所以两个得分都会比较低,sigmoid之后会接近0.5。这好像问题不是太大,0.5咱就不要它呗,咱要得分高的。
(2)这个格子还得预测物体的宽高啊,平板和耳塞的尺寸差距比较大,一会儿用平板的宽高真值给他计算损失,一会儿用耳塞的宽高直值给他计算损失,那最终得出的宽高可能不靠谱。
(3)问题(1)里面说0.5的就不要,但是如果我们训练出来的东西里面,有些东西的效果不太好,置信度比较低,跟0.5很接近,而我们又想要预测出这些东西,那置信度就有点难设了。
- 您还可以看一下 白勇老师的YOLOv5实战口罩佩戴检测课程中的 测试训练出的网络模型及性能统计小节, 巩固相关知识点
- 以下回答来自chatgpt:
如果要在YOLOv5中只标记指定类别并排除其他类别,可以采用以下步骤:
1.首先,需要在数据集中为指定类别打上标签。可以使用标签工具(如labelimg)来手动标记,或者使用自动标记工具(如Roboflow)来快速标记。
2.在训练过程中,可以使用--single-cls选项来确保YOLOv5只标记指定类别。具体来说,在train.py中将--single-cls选项设置为True,然后将类别ID设置为0。这将导致YOLOv5仅监测指定类别(类别ID为0),并将其与其他类别区分开来。
python train.py --img 640 --batch 16 --epochs 300 --data yourdata.yaml --weights yolov5s.pt --single-cls --cls 03.此外,可以使用其他数据增强技巧来提高模型的性能。如上文所述,YOLOv5支持mosaic数据增强,这可以提高模型的鲁棒性,并帮助模型更好地适应新的场景。可以通过修改hyp.scratch.yaml文件来控制数据增强超参数的设置。
综上所述,只需在训练过程中设置--single-cls选项,并将类别ID设置为指定类别的ID,可以实现在YOLOv5中只标记指定类别并排除其他类别的要求。同时,通过使用其他数据增强技巧,可以提高模型的性能和鲁棒性。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^