Python爬虫求各位解答~
我是刚学Python的新人士,想通过bs4爬出如图二的专栏,该怎么办
求指点~


使用requests库,获取html 解析a链接即可
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7761368
- 这篇博客也不错, 你可以看下Python 爬虫 bs4 数据解析基本使用
- 除此之外, 这篇博客: python爬虫篇,零基础学爬虫之精华版中的 bs4模块 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
request模块可以发送请求,获取HTML文档内容。而
bs4模块可以解析出HTML与XML文档的内容,如快速查找标签等等。pip3 install bs4
bs4模块只能在Python中使用
bs4依赖解析器,虽然有自带的解析器,但是目前使用最多的还是lxml:pip3 install lxml
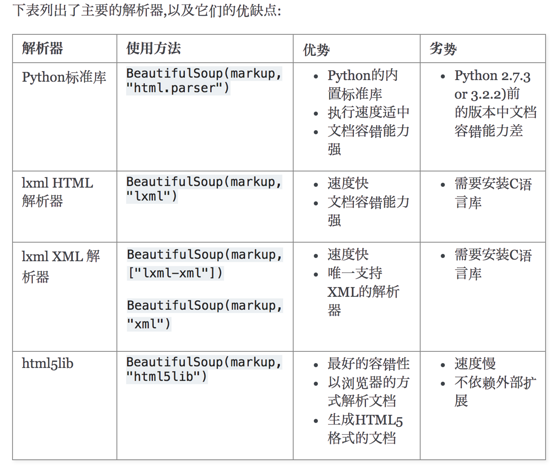
将
request模块请求回来的HTML文档内容转换为bs4对象,使用其下的方法进行查找:如下示例,解析出虾米音乐中的歌曲,歌手,歌曲时长:
import requests from bs4 import BeautifulSoup from prettytable import PrettyTable # 实例化表格 table = PrettyTable(['编号', '歌曲名称', '歌手', '歌曲时长']) url = r"https://www.xiami.com/list?page=1&query=%7B%22genreType%22%3A1%2C%22genreId%22%3A%2220%22%7D&scene=genre&type=song" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36", } response = requests.get(url=url, headers=headers) # step01: 将文本内容实例化出bs对象 soup_obj = BeautifulSoup(response.text, "lxml") # step02: 查找标签 main = soup_obj.find("div", attrs={"class": "table idle song-table list-song"}) # step03: 查找存放歌曲信息的tbody标签 tbody = main.select(".table-container>table>tbody")[0] # step04: tbody标签中的每个tr都是一首歌曲 tr = tbody.find_all("tr") # step04: 每个tr里都存放有歌曲信息,所以直接循环即可 for music in tr: name = music.select(".song-name>a")[0].text singer = music.select(".COMPACT>a")[0].text time_len = music.select(".duration")[0].text table.add_row([tr.index(music) + 1, name, singer, time_len]) # step05: 打印信息 print(table)结果如下:
+------+--------------------------------------------------+--------------------+----------+ | 编号 | 歌曲名称 | 歌手 | 歌曲时长 | +------+--------------------------------------------------+--------------------+----------+ | 1 | Love Story (Live from BBC 1's Radio Live Lounge) | Taylor Swift | 04:25 | | 2 | Five Hundred Miles | Jove | 03:27 | | 3 | I'm Gonna Getcha Good! (Red Album Version) | Shania Twain | 04:30 | | 4 | Your Man | Josh Turner | 03:45 | | 5 | Am I That Easy To Forget | Jim Reeves | 02:22 | | 6 | Set for Life | Trent Dabbs | 04:23 | | 7 | Blue Jeans | Justin Rutledge | 04:25 | | 8 | Blind Tom | Grant-Lee Phillips | 02:59 | | 9 | Dreams | Slaid Cleaves | 04:14 | | 10 | Remember When | Alan Jackson | 04:31 | | 11 | Crying in the Rain | Don Williams | 03:04 | | 12 | Only Worse | Randy Travis | 02:53 | | 13 | Vincent | The Sunny Cowgirls | 04:22 | | 14 | When Your Lips Are so Close | Gord Bamford | 03:02 | | 15 | Let It Be You | Ricky Skaggs | 02:42 | | 16 | Steal a Heart | Tenille Arts | 03:09 | | 17 | Rylynn | Andy McKee | 05:13 | | 18 | Rockin' Around The Christmas Tree | Brenda Lee | 02:06 | | 19 | Love You Like a Love Song | Megan & Liz | 03:17 | | 20 | Tonight I Wanna Cry | Keith Urban | 04:18 | | 21 | If a Song Could Be President | Over the Rhine | 03:09 | | 22 | Shut'er Down | Doug Supernaw | 04:12 | | 23 | Falling | Jamestown Story | 03:08 | | 24 | Jim Cain | Bill Callahan | 04:40 | | 25 | Parallel Line | Keith Urban | 04:14 | | 26 | Jingle Bell Rock | Bobby Helms | 04:06 | | 27 | Unsettled | Justin Rutledge | 04:01 | | 28 | Bummin' Cigarettes | Maren Morris | 03:07 | | 29 | Cheatin' on Her Heart | Jeff Carson | 03:18 | | 30 | If My Heart Had a Heart | Cassadee Pope | 03:21 | +------+--------------------------------------------------+--------------------+----------+ Process finished with exit code 0
准备一个
HTML文档,对他进行解析:<!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <form action="#" method="post" enctype="multipart/form-data"> <fieldset> <legend><h1>欢迎注册</h1></legend> <p>头像: <input type="file" name="avatar"/></p> <p>用户名: <input type="text" name="username" placeholder="请输入用户名"/></p> <p>密码: <input type="text" name="pwd" placeholder="请输入密码"/></p> <p>性别: 男<input type="radio" name="gender" value="male"/>女<input type="radio" name="gender" value="female"/></p> <p>爱好: 篮球<input type="checkbox" name="hobby" value="basketball" checked/>足球<input type="checkbox" name="hobby" value="football"/></p> 居住地 <select name="addr"> <optgroup label="中国"> <option value="bejing" selected>北京</option> <option value="shanghai">上海</option> <option value="guangzhou">广州</option> <option value="shenzhen">深圳</option> <option value="other">其他</option> </optgroup> <optgroup label="海外"> <option value="America">美国</option> <option value="Japanese">日本</option> <option value="England">英国</option> <option value="Germany">德国</option> <option value="Canada">加拿大</option> </optgroup> </select> </fieldset> <fieldset> <legend>请填写注册理由</legend> <p><textarea name="register_reason" cols="30" rows="10" placeholder="请填写充分理由"></textarea></p> </fieldset> <p><input type="reset" value="重新填写信息"/> <input type="submit" value="提交注册信息"> <input type="butoon" value="联系客服" disabled> </p> </form> </body> </html>基本选择器如下 :
选择器方法 描述 TagName 唯一选择器,根据标签名来选择 find() 唯一选择器,可根据标签名、属性来做选择 select_one() 唯一选择器,可根据CSS选择器语法做选择 find_all() 集合选择器,可根据标签名、属性来做选择 select() 集合选择器,可根据CSS选择器语法做选择 .TagName选择器只会拿出第一个匹配的内容,必须根据标签名选择:input = soup.input print(input) # <input name="avatar" type="file"/>
.find()选择器只会拿出第一个匹配的内容,可根据标签名、属性来做选择input= soup.find("input",attrs={"name":"username","type":"text"}) # attrs指定属性 print(input) # <input name="username" placeholder="请输入用户名" type="text"/>.select_one()根据css选择器来查找标签,只获取第一个:input = soup.select_one("input[type=text]") print(input) # <input name="username" placeholder="请输入用户名" type="text"/>.find_all()可获取所有匹配的标签,返回一个list,可根据标签名、属性来做选择input_list = soup.find_all("input",attrs={"type":"text"}) print(input_list) # [<input name="username" placeholder="请输入用户名" type="text"/>, <input name="pwd" placeholder="请输入密码" type="text"/>].select()根据css选择器获取所有匹配的标签,返回一个listinput_list = soup.select("input[type=text]") print(input_list) # [<input name="username" placeholder="请输入用户名" type="text"/>, <input name="pwd" placeholder="请输入密码" type="text"/>]使用较少,选读:
属性/方法 描述 children 获取所有的后代标签,返回迭代器 descendants 获取所有的后代标签,返回生成器 index() 检查某个标签在当前标签中的索引值 clear() 删除后代标签,保留本标签,相当于清空 decompose() 删除标签本身(包括所有后代标签) extract() 同.decomponse()效果相同,但会返回被删除的标签 decode() 将当前标签与后代标签转换字符串 decode_contents() 将当前标签的后代标签转换为字符串 encode() 将当前标签与后代标签转换字节串 encode_contents() 将当前标签的后代标签转换为字节串 append() 在当前标签内部追加一个标签(无示例) insert() 在当前标签内部指定位置插入一个标签(无示例) insert_before() 在当前标签前面插入一个标签(无示例) insert_after() 在当前标签后面插入一个标签(无示例) replace_with() 将当前标签替换为指定标签(无示例) .children获取所有的后代标签,返回迭代器form = soup.find("form") print(form.children) # <list_iterator object at 0x0000025665D5BDD8>.descendants获取所有的后代标签,返回生成器form = soup.find("form") print(form.descendants) # <generator object descendants at 0x00000271C8F0ACA8>.index()检查某个标签在当前标签中的索引值body = soup.find("body") form = soup.find("form") print(body.index(form)) # 3.clear()删除后代标签,保留本标签,相当于清空form = soup.find("form") form.clear() print(form) # None print(soup) # 清空了form.decompose()删除标签本身(包括所有后代标签)form = soup.find("form") form..decompose() print(form) # None print(soup) # 删除了form.extract()同.decomponse()效果相同,但会返回被删除的标签form = soup.find("form") form..extract() print(form) # 被删除的内容 print(soup) # 被删除了form.decode()将当前标签与后代标签转换字符串,.decode_contents()将当前标签的后代标签转换为字符串form = soup.find("form") print(form.decode()) # 包含form print(form.decode_contents()) # 不包含form.encode()将当前标签与后代标签转换字节串,.encode_contents()将当前标签的后代标签转换为字节串form = soup.find("form") print(form.encode()) # 包含form print(form.encode_contents()) # 不包含form以下方法都比较常用:
属性/方法 描述 name 获取标签名称 attrs 获取标签属性 text 获取该标签下的所有文本内容(包括后代) string 获取该标签下的直系文本内容 is_empty_element 判断是否是空标签或者自闭合标签 get_text() 获取该标签下的所有文本内容(包括后代) has_attr() 检查标签是否具有该属性 .name获取标签名称form = soup.find("form") print(form.name) # form.attrs获取标签属性form = soup.find("form") print(form.attrs) # {'action': '#', 'method': 'post', 'enctype': 'multipart/form-data'}.is_empty_element判断是否是空标签或者自闭合标签input = soup.find("input") print(input.is_empty_element) # True.get_text()与text获取该标签下的所有文本内容(包括后代)form = soup.find("form") print(form.get_text()) print(form.text)string获取该标签下的直系文本内容form = soup.find("form") print(form.get_text()) print(form.string).has_attr()检查标签是否具有该属性form = soup.find("form") print(form.has_attr("action")) # TruexPath模块的作用与bs4相同,都是查找标签。但是
xPath模块的通用性更强,它的语法规则并不限于仅在Python中使用。作为一门小型的专业化查找语言,
xPath在Python中被集成在了lxml模块中,所以直接下载安装就可以开始使用了。pip3 install lxml
加载文档:
from lxml import etree # 解析网络爬取的html源代码 root = etree.HTML(response.text,,etree.HTMLParser()) # 加载整个HTML文档,并且返回根节点<html> # 解析本地的html文件 root = etree.parse(fileName,etree.HTMLParser())
基本选取符:
符号 描述 / 从根节点开始选取 // 不考虑层级关系的选取节点 . 选取当前节点 .. 选取当前节点的父节点 @ 属性检测 [num] 选取第n个标签元素,从1开始 /@attrName 选取当前元素的某一属性 * 通配符 /text() 选取当前节点下的直系文本内容 //text() 选取当前文本下的所有文本内容 | 返回符号两侧所匹配的全部标签 以下是示例:
注意:xPath选择完成后,返回的始终是一个list,与jQuery类似,可以通过Index取出Element对象
from lxml import etree root = etree.parse("./testDataDocument.html",etree.HTMLParser()) # 从根节点开始找 / form_list = root.xpath("/html/body/form") print(form_list) # [<Element form at 0x203bd29c188>] # 不考虑层级关系的选择节点 // input_list = root.xpath("//input") print(input_list) # 从当前的节点开始选择 即第一个form表单 ./ select_list = form_list[0].xpath("./fieldset/select") print(select_list) # 选择当前节点的父节点 .. form_parent_list = form_list[0].xpath("..") print(form_parent_list) # [<Element body at 0x1c946e4c548>] # 属性检测 @ 选取具有name属性的input框 input_username_list = root.xpath("//input[@name='username']") print(input_username_list) # 属性选取 @ 获取元素的属性 attrs_list = root.xpath("//p/@title") print(attrs_list) # 选取第n个元素,从1开始 p_text_list = root.xpath("//p[2]/text()") print(p_text_list) # 通配符 * 选取所有带有属性的标签 have_attrs_ele_list = root.xpath("//*[@*]") print(have_attrs_ele_list) # 获取文本内容-直系 print(root.xpath("//form/text()")) # 结果:一堆\r\n # 获取文本内容-非直系 print(root.xpath("//form//text()")) # 结果:本身和后代的text # 返回所有input与p标签 ele_list = root.xpath("//input|//p") print(ele_list)你可以指定逻辑运算符,大于小于等。
from lxml import etree root = etree.parse("./testDataDocument.html",etree.HTMLParser()) # 返回属性值price大于或等于20的标签 price_ele_list = root.xpath("//*[@price>=20]") print(price_ele_list)xPath中拥有轴这一概念,不过相对来说使用较少,它就是做关系用的。了解即可:轴 示例 说明 ancestor xpath(‘./ancestor::*’) 选取当前节点的所有先辈节点(父、祖父) ancestor-or-self xpath(‘./ancestor-or-self::*’) 选取当前节点的所有先辈节点以及节点本身 attribute xpath(‘./attribute::*’) 选取当前节点的所有属性 child xpath(‘./child::*’) 返回当前节点的所有子节点 descendant xpath(‘./descendant::*’) 返回当前节点的所有后代节点(子节点、孙节点) following xpath(‘./following::*’) 选取文档中当前节点结束标签后的所有节点 following-sibing xpath(‘./following-sibing::*’) 选取当前节点之后的兄弟节点 parent xpath(‘./parent::*’) 选取当前节点的父节点 preceding xpath(‘./preceding::*’) 选取文档中当前节点开始标签前的所有节点 preceding-sibling xpath(‘./preceding-sibling::*’) 选取当前节点之前的兄弟节点 self xpath(‘./self::*’) 选取当前节点 功能函数更多的是做模糊搜索,这里举几个常见的例子,一般使用也不多:
函数 示例 描述 starts-with xpath(‘//div[starts-with(@id,”ma”)]‘) 选取id值以ma开头的div节点 contains xpath(‘//div[contains(@id,”ma”)]‘) 选取id值包含ma的div节点 and xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘) 选取id值包含ma和in的div节点 text() xpath(‘//div[contains(text(),”ma”)]‘) 选取节点文本包含ma的div节点 上面说过,使用
xPath进行筛选后得到的结果都是一个list,其中的成员就是element标签对象。以下方法都是操纵
element标签对象的,比较常用。首先是针对自身标签的操作:
属性 描述 tag 返回元素的标签类型 text 返回元素的直系文本 tail 返回元素的尾行 attrib 返回元素的属性(字典形式) 演示如下:
from lxml import etree root = etree.parse("./testDataDocument.html",etree.HTMLParser()) list(map(lambda ele:print(ele.tag),root.xpath("//option"))) list(map(lambda ele:print(ele.text),root.xpath("//option"))) # 常用 list(map(lambda ele:print(ele.tail),root.xpath("//option"))) list(map(lambda ele:print(ele.attrib),root.xpath("//option"))) # 常用针对当前
element对象属性的操作,用的不多:方法 描述 clear() 清空元素的后代、属性、text和tail也设置为None get() 获取key对应的属性值,如该属性不存在则返回default值 items() 根据属性字典返回一个列表,列表元素为(key, value) keys() 返回包含所有元素属性键的列表 set() 设置新的属性键与值 针对当前
element对象后代的操作,用的更少:方法 描述 append() 添加直系子元素 extend() 增加一串元素对象作为子元素 find() 寻找第一个匹配子元素,匹配对象可以为tag或path findall() 寻找所有匹配子元素,匹配对象可以为tag或path findtext() 寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path insert() 在指定位置插入子元素 iter() 生成遍历当前元素所有后代或者给定tag的后代的迭代器 iterfind() 根据tag或path查找所有的后代 itertext() 遍历所有后代并返回text值 remove() 删除子元素 Flask作为后端服务器:from flask import Flask import time app = Flask(__name__,template_folder="./") @app.route('/index',methods=["GET","POST"]) def index(): time.sleep(2) return "index...ok!!!" @app.route('/news') def news(): time.sleep(2) return "news...ok!!!" @app.route('/hot') def hot(): time.sleep(2) return "hot...ok!!!" if __name__ == '__main__': app.run()如果使用同步爬虫对上述服务器的三个
url进行爬取,花费的结果是六秒:import time from requests import Session headers = { "user-agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" } urls = [ "http://127.0.0.1:5000/index", "http://127.0.0.1:5000/news", "http://127.0.0.1:5000/hot", ] start = time.time() def func(url): session = Session() response = session.get(url) return response.text # 回调函数,处理后续任务 def callback(result): # 获取结果 print(result) for url in urls: res = func(url) callback(res) end = time.time() print("总用时:%s秒" % (end - start))使用多线程则基本两秒左右即可完成:
import time from concurrent.futures import ThreadPoolExecutor from requests import Session headers = { "user-agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" } urls = [ "http://127.0.0.1:5000/index", "http://127.0.0.1:5000/news", "http://127.0.0.1:5000/hot", ] start = time.time() def func(url): session = Session() response = session.get(url) return response.text # 回调函数 def callback(obj): # 期程对象 print(obj.result()) pool = ThreadPoolExecutor(max_workers=4) for url in urls: res = pool.submit(func, url) # 为期程对象绑定回调 res.add_done_callback(callback) pool.shutdown(wait=True) end = time.time() print("总用时:%s秒" % (end - start))线程的切换开销较大,可使用切换代价更小的协程进行实现。
由于协程中不允许同步方法的出现,
requests模块下的请求方法都是同步请求方法,所以需要使用aiohttp模块下的异步请求方法完成网络请求。现今的所谓异步,其实都是用
I/O多路复用技术来完成,即在一个线程下进行where循环,监听描述符,即eventLoop。import asyncio import time import aiohttp headers = { "user-agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" } urls = [ "http://127.0.0.1:5000/index", "http://127.0.0.1:5000/news", "http://127.0.0.1:5000/hot", ] start = time.time() async def func(url): # 在async协程中,所有的阻塞方法都需要通过await手动挂起 # 并且,如果存在同步方法,则还是同步执行,必须是异步方法,所以这里使用aiohttp模块发送请求 async with aiohttp.ClientSession() as session: async with await session.get(url) as response: # text():返回字符串形式的响应数据 # read(): 返回二进制格式响应数据 # json(): json格式反序列化 result = await response.text() # aiohttp中是一个方法 return result # 回调函数 def callback(obj): # 期程对象 print(obj.result()) # 创建协程任务列表 tasks = [] for url in urls: g = func(url) # 创建协程任务g task = asyncio.ensure_future(g) # 注册协程任务 task.add_done_callback(callback) # 绑定回调,传入期程对象 tasks.append(task) # 添加协程任务到任务列表 # 创建事件循环 loop = asyncio.get_event_loop() # 执行任务,并且主线程会等待协程任务列表中的所有任务处理完毕后再执行 loop.run_until_complete(asyncio.wait(tasks)) end = time.time() print("总用时:%s秒" % (end - start))selenium是Python实现浏览器自动化操作的一款模块。通过它我们可以让代码控制浏览器,从而进行数据爬取,尤其在以下两个地方该模块的作用更加强大:
- 获取整张页面的数据,对有的页面来说前后端分离的API接口太难找了,使用requests模块根本找不到发送加载数据的接口
- 进行自动登录
下载安装:
pip3 install selenium
由于要操纵浏览器,所以要下载对应的驱动文件,需要注意的是驱动版本需要与浏览器版本一一对应:
下载驱动
如果是
MAC平台,解压到如下路径,win平台解压到任意位置皆可:/usr/local/bin
由于我们使用的是
chorme浏览器,所以只需要实例化出其操纵对象即可:from selenium import webdriver driver = webdriver.Chrome()
以后的操纵都是操纵该实例对象,如果你使用其他版本浏览器,请自行下载驱动,支持的浏览器如下:
driver = webdriver.Firefox() driver = webdriver.Edge() driver = webdriver.PhantomJS() driver = webdriver.Safari()
- 以下回答由chatgpt基于相关博客总结生成:
解决方案: 使用BeautifulSoup进行网页爬虫,可以通过以下步骤实现: 1.导入requests和BeautifulSoup库 2.使用requests库获取待爬取的网页数据 3.使用BeautifulSoup解析网页html结构 4.定位需要的数据节点 5.提取数据,处理后保存到字典或文件中
具体的代码实现可以参考以下示例:
import requests from bs4 import BeautifulSoup # 待爬取网页的URL url = 'https://blog.csdn.net/nav/python' # 发送GET请求获取网页数据 response = requests.get(url) # 解析网页html结构,指定使用lxml解析器 soup = BeautifulSoup(response.text, 'lxml') # 定位目标数据节点 articles = soup.find_all('div', class_='article-list')[0].find_all('div', class_='article-item-box') # 定义结果字典 result = {} # 遍历目标数据节点,提取文章标题和作者信息 for article in articles: title = article.find_all('h4')[0].text.strip() author = article.find_all('a', class_='nickname')[0].text.strip() result[title] = author # 输出结果字典 print(result)运行结果:
{'热点 | 明日之后开发团队:为何选择 Python 做服务器开发': 'CE引领者', 'Python 函数式编程实战 | 你学过这些吗?': 'Nathaniel_Huo', 'Python 入门教程 | 五年 Python 内部培训教材精选': '一方通行666', '谈谈Python的Int类型内存优化': 'cutejane', '实战 | Python 命令行奇技淫巧': 'wordlittle', 'Python请求discord API的教程': '不爱钱的小鸟', 'Python 常用第三方库总结': 'Python之禅', 'Python 发送邮件的几种方式': 'AlexWang-_-', 'Python入门系列(六):函数(二)': 'weixin_45085392', '浅谈 python 中的 异常 ': 'ATrueWINTER', 'Python 在生物信息学中的应用': 'Monkey_kingfromsky', 'python处理大数据文件错误 --->类显存不足': '许多年以后又看到你', 'Python 高级编程之装饰器': '闫述光SteveYan', 'python 读写文件实例(循环写入、逐行读取、随机读取)': 'Zoay1'}以上代码示例可以爬取CSDN的Python专栏文章信息,提取出文章标题和作者姓名,并存储到字典中。可以根据具体爬取网页的结构定位数据节点和编写数据处理代码。