碰撞后,碰撞物体A变成碰撞物体B的子物体代码怎么写

上图这段代码是放在应该变成子物体的物体A上的,如果发生碰撞,物体A就变成物体B的子物体,具体一点的代码该怎么写
大括号里面的就是那个方法,只是你要先获取到物体B,直接Public Transform B;拖拽就行
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/158456
- 除此之外, 这篇博客: 初识人工智能原理中的 那么要怎么对 a 和 b 进行更新呢? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
是不是像我们求公式一样求出来,并不是那样,咱们的计算机计算核心只能进行数值的计算,而不能进行推理,按照咱们公式推理的形式并不能应用在计算机上。计算机只能进行数值的尝试,尝试带入不同的 a 和 b。如果真的这么莽撞的尝试,人工智能也就不能被称为“第四次工业革命”了。现在剩下的问题就是,如何对 a 和 b 进行更新。在更新的过程中要确定两件事,第一件事就是往什么方向进行更新,第二件事就是要更新多少。
下面为大家简单的复习下高等数学中的导数。这里不讲如何计算导数,需要大家理解导数的含义。函数中某一点的导数代表改点在图像中的切线斜率。切线所指的方向就是最快上升/下降的方向,导数是切线的斜率,就可以用导数的正/负来给指引更新的方向。

图中红色直线是 𝑥=5 处二次函数的切线,而该点的导数 𝑓′(𝑥=5) = 20 表示的方向是图中红色箭头方向,为了得到极小值点,需要沿着导数的反向更新。
而导数(切线斜率)的大小表明变化的速率,意思是当导数(切线斜率)比较大的情况下,变量变化所引起的结果变化也就更大。把这个概念引入到求 loss 的极小值的问题上,就是当 a 的偏导数比 b 大时,说明在当前情况下参数 a 更加重要(或者说参数 a 偏差的更大),需要对 a 进行更大的更新幅度。划重点,以变量偏导数乘以一个系数作为变量更新的数值,这个系数我们叫它学习率(learning rate),这个系数能帮助我们一定程度上控制算法模型的自我更新。
回到前面咱们拟合数据的例子中,首先先求一下 loss 函数对分别对参数 a 和参数 b 的偏导数。先把 loss 函数展开。
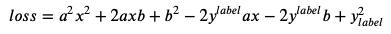
根据偏导数公式,求参数a的偏导数表达式 𝑙𝑜𝑠𝑠′𝑎 与参数 b 的偏导数表达式 𝑙𝑜𝑠𝑠′𝑏
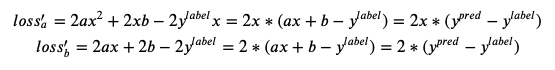
𝑙𝑜𝑠𝑠′𝑎 与𝑙𝑜𝑠𝑠′𝑏 是参数 a 和 b 的偏导数表达式,有了表达式,就可以在代码中定义求参数 a 和参数 b 的导数的方法了。接着刚才的代码,下面我们看看怎么定义 a 和 b的偏导方法。

有了更新的方案,模型算法就可以按照这样进行自我更新、自我学习了。模型的学习需要一个过程,要进多次学习(step),而每次学习都是通过导数提供学习方向及更新的数值大小。现在再看看函数拟合数据的效果吧。

最后总结一下,本次分享需要理解的有两点,第一个是理解数据数值的几何含义。第二个是基于机器学习和深度学习的人工智能技术的原理,利用函数拟合的方式用函数来表示数据,从而达到解决数据所代表的问题。