位置1处的索引超出数组边界。索引不能超过14。
位置1处的索引超出数组边界,索引不能超过14,请问怎么改正啊?
清空环境
clc
clear
初始位置分布
%城市坐标
X = [102.13 31.55
104.63 28.76
102.22 31.89
101.96 30.05
105.82 32.43
102.25 27.88
105.06 29.58
104.74 31.46
104.06 30.65
103.76 29.55
105.44 28.88
104.39 31.12
103.00 29.98
103.83 30.04];
DQ=[12 81 29 47 11 18 11 24 5 11 15 2 18 1];
figure(1)
plot(X(:,1),X(:,2),'o','LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor','g',...
'MarkerSize',10)
title('初始受灾点分布图','fontsize',12)
xlabel('经度','fontsize',12)
ylabel('纬度','fontsize',12)
算法基本参数
sizepop=50; % 种群规模
overbest=10; % 记忆库容量
MAXGEN=100; % 迭代次数
pcross=0.5; % 交叉概率
pmutation=0.4; % 变异概率
ps=0.95; % 多样性评价参数
length=3; % 配送中心数
M=sizepop+overbest;
step1 识别抗原,将种群信息定义为一个结构体
individuals = struct('fitness',zeros(1,M), 'concentration',zeros(1,M),'excellence',zeros(1,M),'chrom',[]);
step2 产生初始抗体群
individuals.chrom = popinit(M,length);
trace=[]; %记录每代最个体优适应度和平均适应度
迭代寻优
for iii=1:MAXGEN
step3 抗体群多样性评价
for i=1:M
individuals.fitness(i) = fitness(individuals.chrom(i,:)); % 抗体与抗原亲和度(适应度值)计算
individuals.concentration(i) = concentration(i,M,individuals); % 抗体浓度计算
end
% 综合亲和度和浓度评价抗体优秀程度,得出繁殖概率
individuals.excellence = excellence(individuals,M,ps);
% 记录当代最佳个体和种群平均适应度
[best,index] = min(individuals.fitness); % 找出最优适应度
bestchrom = individuals.chrom(index,:); % 找出最优个体
average = mean(individuals.fitness); % 计算平均适应度
trace = [trace;best,average]; % 记录
step4 根据excellence,形成父代群,更新记忆库(加入精英保留策略,可由s控制)
bestindividuals = bestselect(individuals,M,overbest); % 更新记忆库
individuals = bestselect(individuals,M,sizepop); % 形成父代群
step5 选择,交叉,变异操作,再加入记忆库中抗体,产生新种群
individuals = Select(individuals,sizepop); % 选择
individuals.chrom = Cross(pcross,individuals.chrom,sizepop,length); % 交叉
individuals.chrom = Mutation(pmutation,individuals.chrom,sizepop,length); % 变异
individuals = incorporate(individuals,sizepop,bestindividuals,overbest); % 加入记忆库中抗体
end
画出免疫算法收敛曲线
figure(2)
plot(trace(:,1));
hold on
plot(trace(:,2),'--');
legend('最优适应度值','平均适应度值')
title('免疫算法收敛曲线','fontsize',12)
xlabel('迭代次数','fontsize',12)
ylabel('适应度值','fontsize',12)
画出配送中心选址图
% 计算 X 的行数
n = size(X, 1);
% 找出最近配送点
for i = 1:n
distance(i, :) = dist(X(i, :), X(bestchrom, :)');
end
[a,b]=min(distance');
index = cell(1, n);
for i = 1:n
% 计算各个派送点的地址
index{i} = find(b == i);
end
figure(3)
title('最优规划派送路线')
cargox=X(bestchrom,1);
cargoy=X(bestchrom,2);
plot(cargox,cargoy,'rs','LineWidth',2,...
'MarkerEdgeColor','r',...
'MarkerFaceColor','b',...
'MarkerSize',20)
hold on
plot(X(:,1),X(:,2),'o','LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor','g',...
'MarkerSize',10)
for i=1:n
x=[X(i,1),X(bestchrom(b(i)),1)];
y=[X(i,2),X(bestchrom(b(i)),2)];
plot(x,y,'c');hold on
end
你给的代码里还有子函数没有给出来哇,比如popinit.m、fitness.m、concentration.m
根据您提供的代码和错误提示,我猜测您可能是在执行以下代码时出现了问题:
bestchrom = individuals. chrom(index,:); % 找出最优个体
其中,index 变量可能超过了数组边界。具体来说,由于您没有在程序中为 index 赋初值,因此它可能是一个空数组或者未定义的变量,从而导致上述代码无法正确执行。
为了解决这个问题,您可以在程序开头添加以下代码,为 index 变量赋初值:
index = 1;
这样就可以避免 index 超过数组边界的问题了。另外,建议您在程序编写过程中注意变量的命名和赋初值,以避免类似的问题发生。
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7519011
- 你也可以参考下这篇文章:使用指针插入元素,在升序的数组中插入一个数,使插入后的数组仍然有序。
- 除此之外, 这篇博客: 【二分查找】二分查找怎么写,边界如何确定,我应该是要左边还是要右边,我为何如此的蠢???中的 5 关于二分查找的边界问题 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
这是二分查找的两种形式,对比一下这两者的代码,它们只有三处不一样,解释在下方
int binarySearch(int[] nums, int target) { if (nums == null || nums.length == 0) return -1; int l = 0, r = nums.length - 1; while (l <= r) { int mid = l + (r - l) / 2; if (nums[mid] == target) { return mid; } else if (nums[mid] < target) { l = mid + 1; } else { r = mid - 1; } } return -1; }int binarySearch2(int[] nums, int target) { if (nums == null || nums.length == 0) return -1; int l = 0, r = nums.length; while (l < r) { int mid = l + (r - l) / 2; if (nums[mid] == target) { return mid; } else if (nums[mid] < target) { l = mid + 1; } else { r = mid; } } return -1; }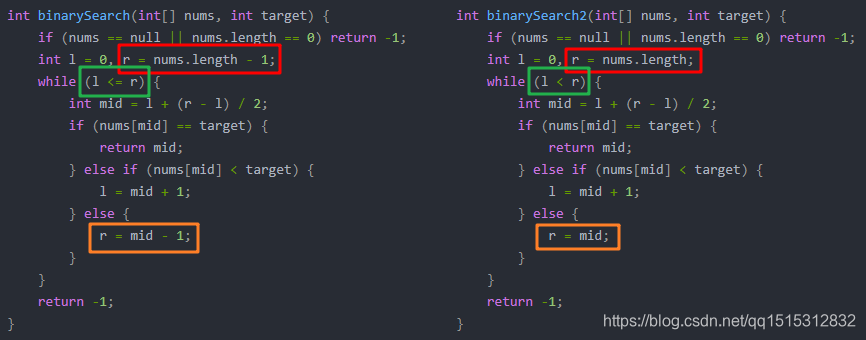
对于r的取值,取nums.length - 1还是nums.length似乎是个很难抉择的问题,但是事实上来说,这两个值都是可以的,只不过这和跳出循环与r 的移动有着密切的关系,也常常是在这种地方陷入疯狂挠头的处境,也就是这种情况,感觉一定不是自己的问题,头发也日渐减少…如果取值是
l = 0, r = nums.length - 11、 取值范围是什么?
我们的取值区间的两个端点都是闭区间,也就是
[ l, r ],左闭右闭,l和r的值都可以取得到2、
l能不能等于r?这个时候如果出现
l = r的情况是没有任何问题的,因为[ r, r ]是有意义的3、 什么时候退出循环?
闭区间
[ l, r ],如果l = r,这个时候是一个临界值,当l > r时,我们应该退出循环4、 关于
r = mid - 1第一次的查询范围是[ l, r],判断mid之后,应该变为[ l, mid -1 ]或者[ mid + 1, r ],r总会指向需要进行判断的元素。我们当前判断的是mid,mid判断完成下一步要找的就是下一个要判断的区间。
如果取值是
l = 0, r = nums.length1、 取值范围是什么?
这和前面得那种情况不一样,r得取值是
nums.length,这个值我们是取不到的,所以这个时候区间是左闭右开得,也就是[ l, r )2、
l能不能等于r?这个时候如果出现
l = r的情况,[ r, r ),既包含r,又不包含r,这个时候是没有意义的,所以l不能等于r3、 什么时候退出循环?
左闭右开区间
[ l, r ),如果l = r,这个时候是没有意义的,这个时候的临界值是l = r - 1,所以,当l = r时,我们应该退出循环4、 关于
r = mid第一次的查询范围是
[ l, r),判断mid之后,应该变为[ l, mid )或者[ mid + 1, r ),关于为什么是[ l, mid ),我们这个时候的mid位置的元素是不会访问的,r指向的是最后一个元素的后一个位置,其实[ l, mid )就相当于[ l, mid - 1 ] - 您还可以看一下 王剑老师的站长必修课:网站是怎样做出来的?课程中的 运营:才刚开始,站长更重要的工作…小节, 巩固相关知识点
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
还请发一下完整代码
问题解决了吗?这图片看不清楚,有源码吗?帮你看下