分子动力学模拟跨膜namd能量最小化
有没有高水帮助一下,想问一下,NAMD跑分子动力学模拟时,分子跨膜,在能量最小化阶段,会出现膜分裂是为什么呢?能量最小化完成后,膜又会合成整体。


膜的初始构象过于紧密或过于松散,可能会导致分裂。
再检查检查力场选择(立场不合适)以及模拟参数(速度过快、步长过大等)设置。
这些原因都有可能,一个个排查一下。
如果有帮助,请点击一下采纳该答案~谢谢
不知道你这个问题是否已经解决, 如果还没有解决的话:- 你可以看下这个问题的回答https://ask.csdn.net/questions/7501903
- 你也可以参考下这篇文章:编程随机生成一个类似下图的湖,其中湖面用一个封闭的多边形表示,数字值大于0,代表水深,岸线数字值为0,湖泊的面积是不规则的,并且湖中各处的水深也不一样。
- 除此之外, 这篇博客: 使用物价水平修正票房数据,长津湖还是票房冠军吗?中的 一、内地电影总票房数据 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
票房数据来源于内地票房总榜--
艺恩娱数打开F12,选择网络,选择XHR格式,最后选择响应,如下图!
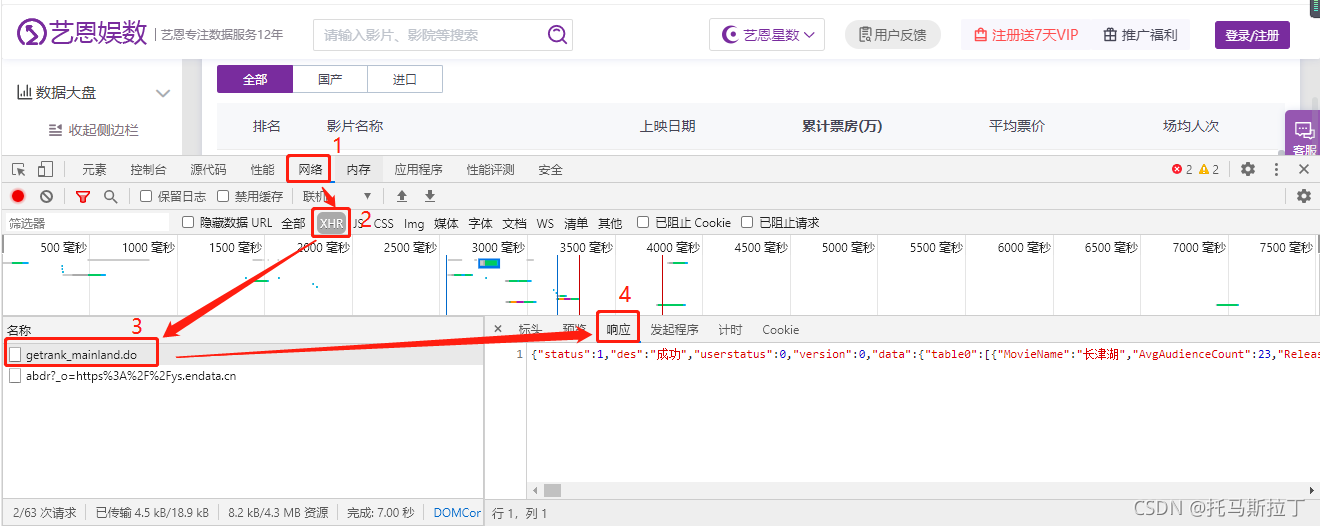
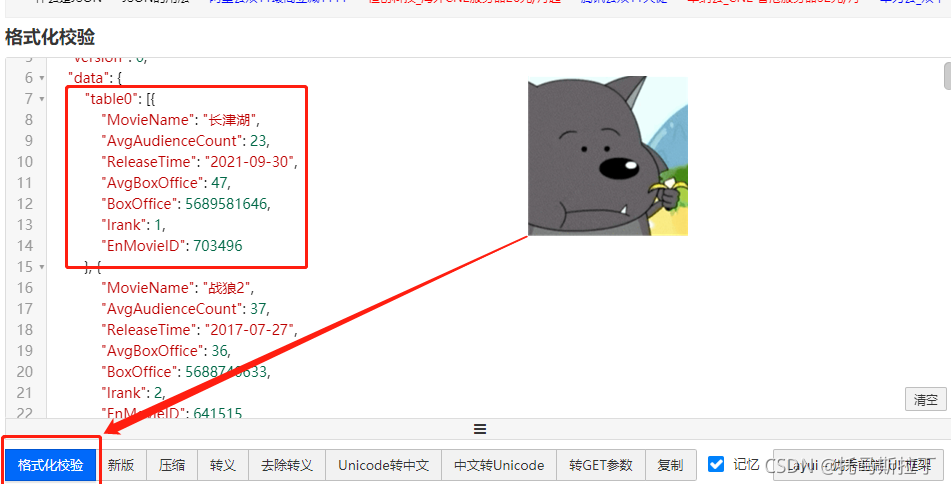
通过查看响应,可以发现该Post请求返回一个JSON,如果更清楚的看清JSON内部的数据,可以使用网站对JSON进行格式化,如在线JSON校验格式化工具(Be JSON)。通过对JSON格式化后,可以清楚看到该数据包括我们最需要的数据,即电影名、上映时间与累计票房。JSON格式化如下图:
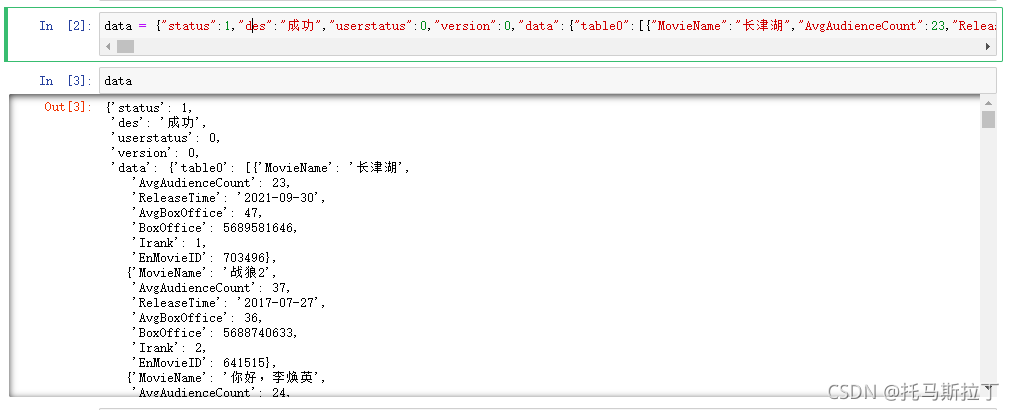
最简单的方式就是将该JSON字符串直接复制到Python代码里,可以发现与网站格式化的效果一模一样。如下图。
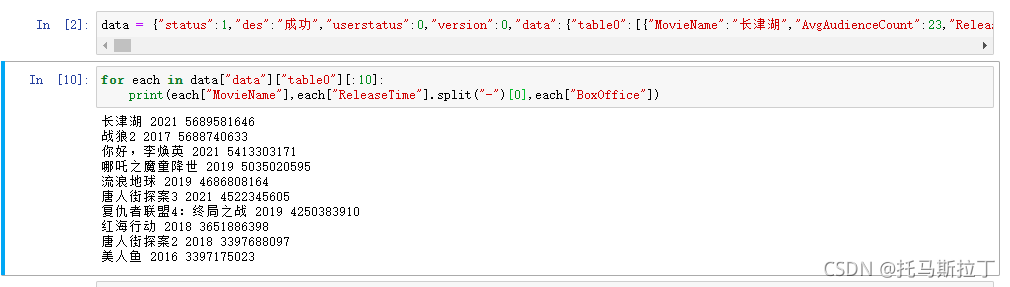
此时可以将data变量当作字典类型使用,并使用split函数对上映时间进行处理,让时间字段只包含上映年份。详情如下图,可以看到分别打印出前10个数据的片名、上映年份与票房。
但此时发现了一件非常尴尬的事情,就是这个网站的前端界面只显示前50名的票房。囧!
不过没关系,我们仔细看看返回这个JSON的post,发现了这个奥秘就在这个“top:50”里,所以该请求只给前端界面返回了前50个排名,同时注意到“type:1”,这个是用来区分全部、国产与进口的!读者可以试试,当选择进口的时候,type就会变成2。
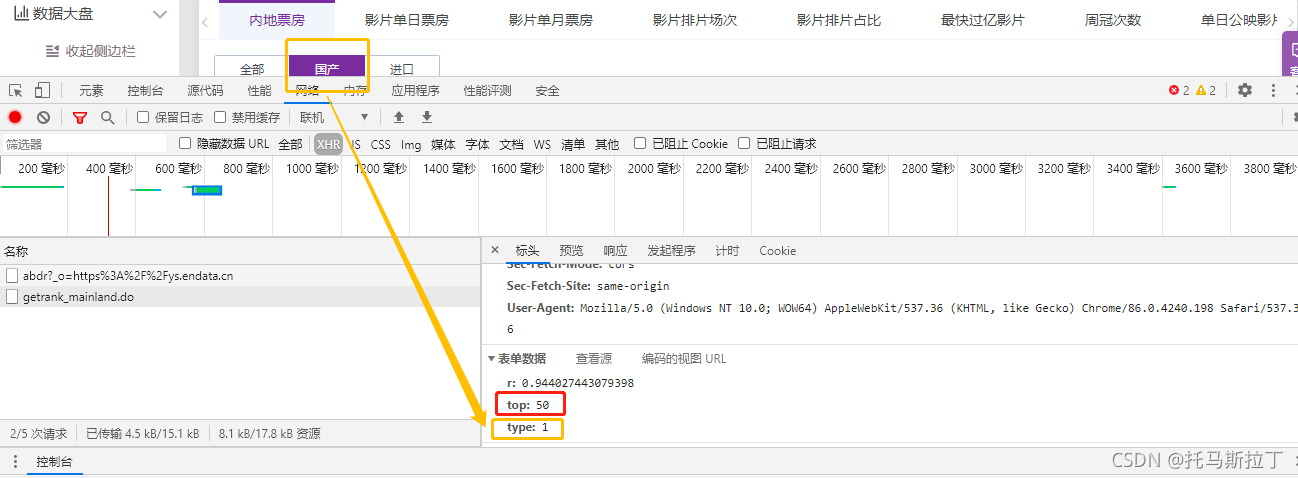
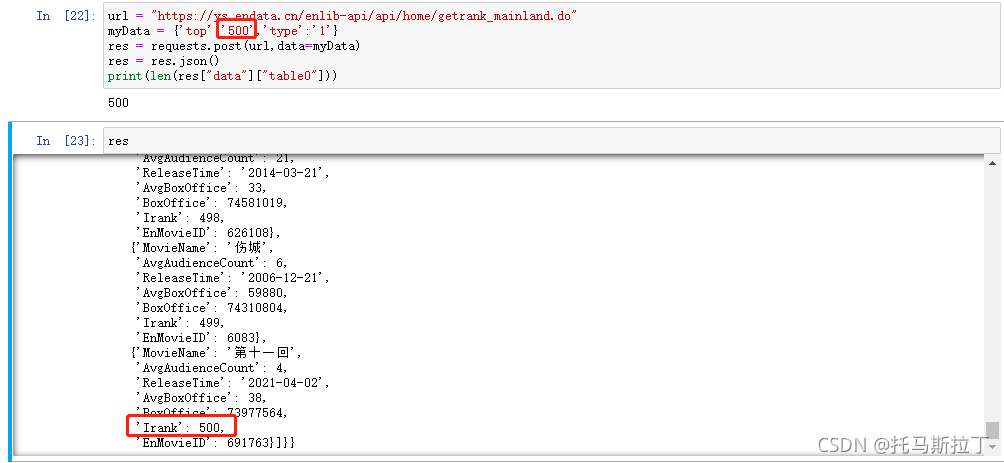
运气还不错,使用最简单的Post就可以直接得到返回。从下图可以看出,我们已经成功得到了前500名的数据,跳出了前端界面的限制。写爬虫的时候经常也可以发现这种情况,服务器发给前端的数据,前端只是选择性的显示,比如人人贷的贷款数据,从界面上是无法看见借款人的借款理由,但通过F12可以发现服务器返回的数据是包含借款理由这个字段,只是前端不显示而已。
然后就将这些数据一起存到pandas的DataFrame里,方便后期处理。详细代码与结果如下:
dataDf = pd.DataFrame() for myIndex,each in enumerate(res["data"]["table0"]): dataDf = dataDf.append(pd.DataFrame({"MovieName":each["MovieName"], "ReleaseTime":each["ReleaseTime"].split("-")[0], "BoxOffice":each["BoxOffice"]},index=[myIndex])) dataDf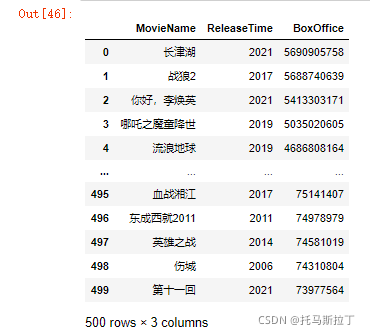
这时候就可以先把未经过通货膨胀修正时的内地总票房排名画出来!!代码与图见下:
pandas.plot()参考资料:【python】详解pandas.DataFrame.plot( )画图函数_brucewong0516的博客-CSDN博客
#kind:barh 横向条状图 #figsize:图片尺寸大小 #legend=False:不显示图例 #color:设置颜色 #fontsize:设置标签文字大小 #list[::-1] -> 倒序 dataDf[:20][::-1].plot("MovieName","BoxOffice",kind='barh',figsize=(16,8),fontsize=15,legend=False, color=["grey","gold","darkviolet","turquoise","r","g","b","c", "k","darkorange","lightgreen","plum", "tan","khaki", "pink", "skyblue","lawngreen","salmon"])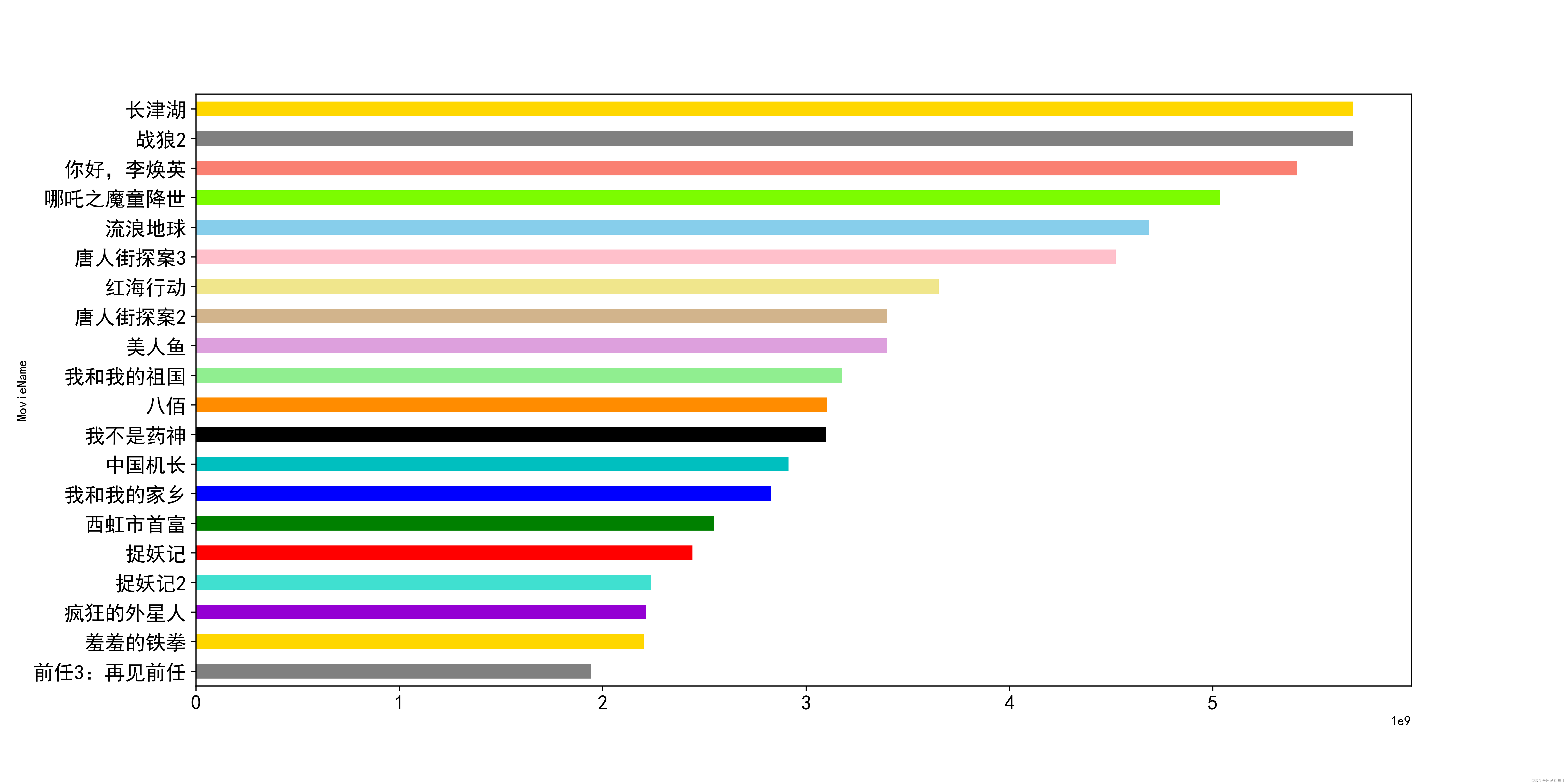
至此,对电影榜的数据的处理暂时到此,接下来需要添加衡量物价水平的指标。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^