scrapy拿不到图片网的原码


这是代码和返回结果,我查了一下别人可以顺利拿到页面,而我用了好几种方法返回结果都是这,求帮忙指点指点!
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/648225
- 这篇博客你也可以参考下:Scrapy 爬取数据时遇到网络延迟导致数据抓不全的解决方案。
- 除此之外, 这篇博客: 就这? Scrapy框架被我用了个遍,结果只制作了表情包!中的 分析网站: 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
本次使用scrapy框架爬取一个小网站, 挺担心这个网站的!
first_url: https://www.52doutu.cn/post/1/
从中点开任意一个查看全部,网址规模都是一样的:https://www.52doutu.cn/p/99/
也就是p后面的数值不一样, 这里可以匹配过去。后面代码细讲:之后打开这样的页面:
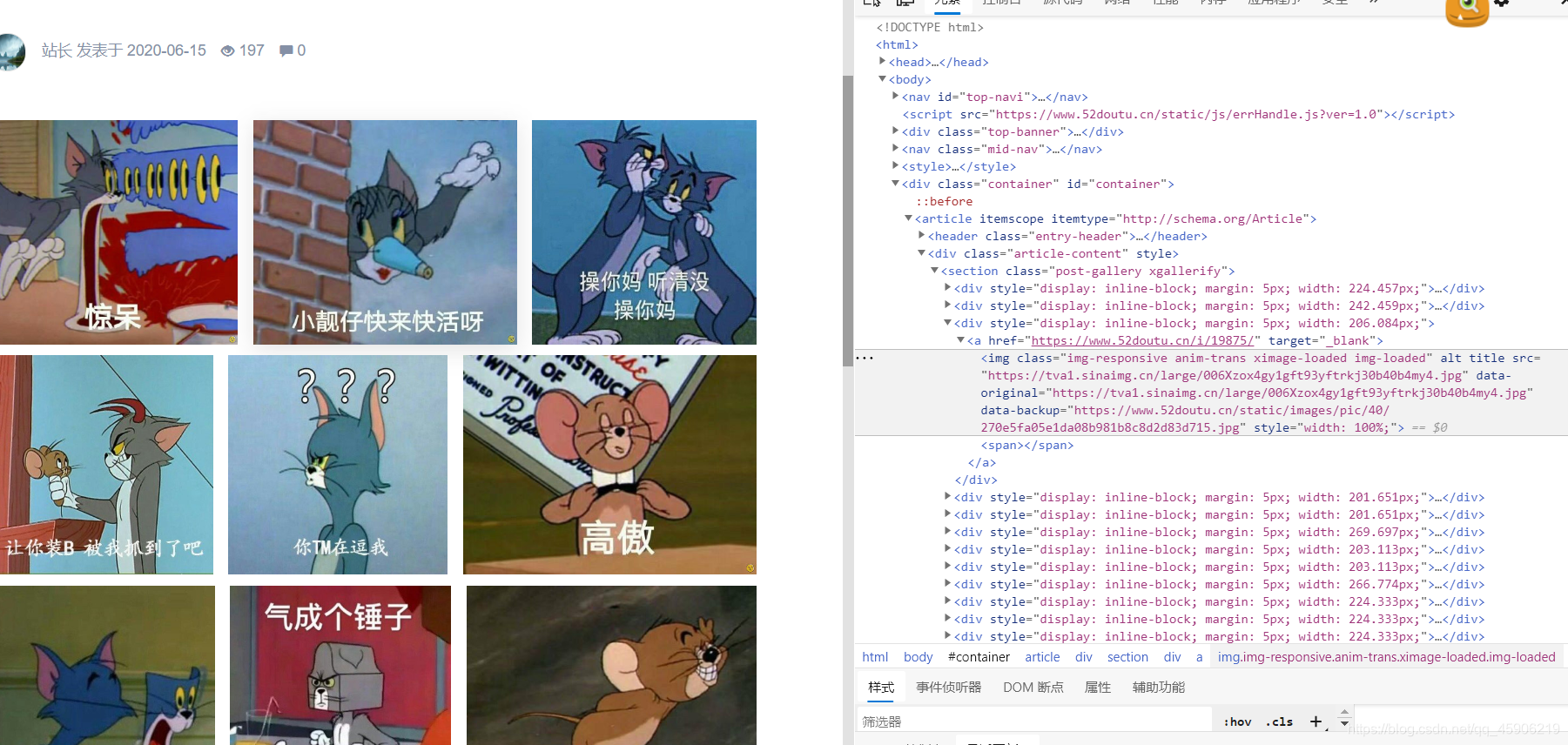
- 别想了, 哪有这么简单直接索取的,这里存在一个js加载,直接获取不了
打开页面源代码,从这里获取,图片url。

具体网站具体分析,不是所有网站都是傻逼网站那么简单爬取。
- 您还可以看一下 李焱兵老师的python分布式爬虫从入门到精通实战课程中的 安装scrapy框架小节, 巩固相关知识点