请问pycharm怎么读取Excel表

找了网上其他人的代码,有点搞不懂,是我的路径错了吗?还是Excel表可能有问题需要整理一下

分开成一个一个模块是吗😳
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7779539
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:PyCharm中读取xlsx格式的Excel表失败解决方法之一
- 除此之外, 这篇博客: pycharm读取excel中的数据,文章中含有源码中的 提取excel中特定的行或者列 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
**
#TODO 首先导入xlrd这个库,后面会使用到xlrd中open_workbook和sheet_by_name方法 import xlrd #TODO 定义一个列表A待会储存读取的信息 A=[] xx=xlrd.open_workbook(r"S:\Data\moveT.xlsx") xs=xx.sheet_by_name('Sheet1') # for i in range(2,50): # k=xs.row_values(i) # print(k) # A.append(k) # print(list(A)) print(xs.row_values(1)) G=xs.col_values(2) print(G) #这里我们查看一下G的格式是列表还是元组,或者其他的 print(type(G))#TODO 首先导入xlrd这个库,后面会使用到xlrd中open_workbook和sheet_by_name方法
import xlrd
#TODO 定义一个列表A待会储存读取的信息
A=[]
xx=xlrd.open_workbook(r"S:\Data\moveT.xlsx")
xs=xx.sheet_by_name(‘Sheet1’)print(xs.row_values(1))
G=xs.col_values(2)
print(G)
#这里我们查看一下G的格式是列表还是元组,或者其他的
print(type(G))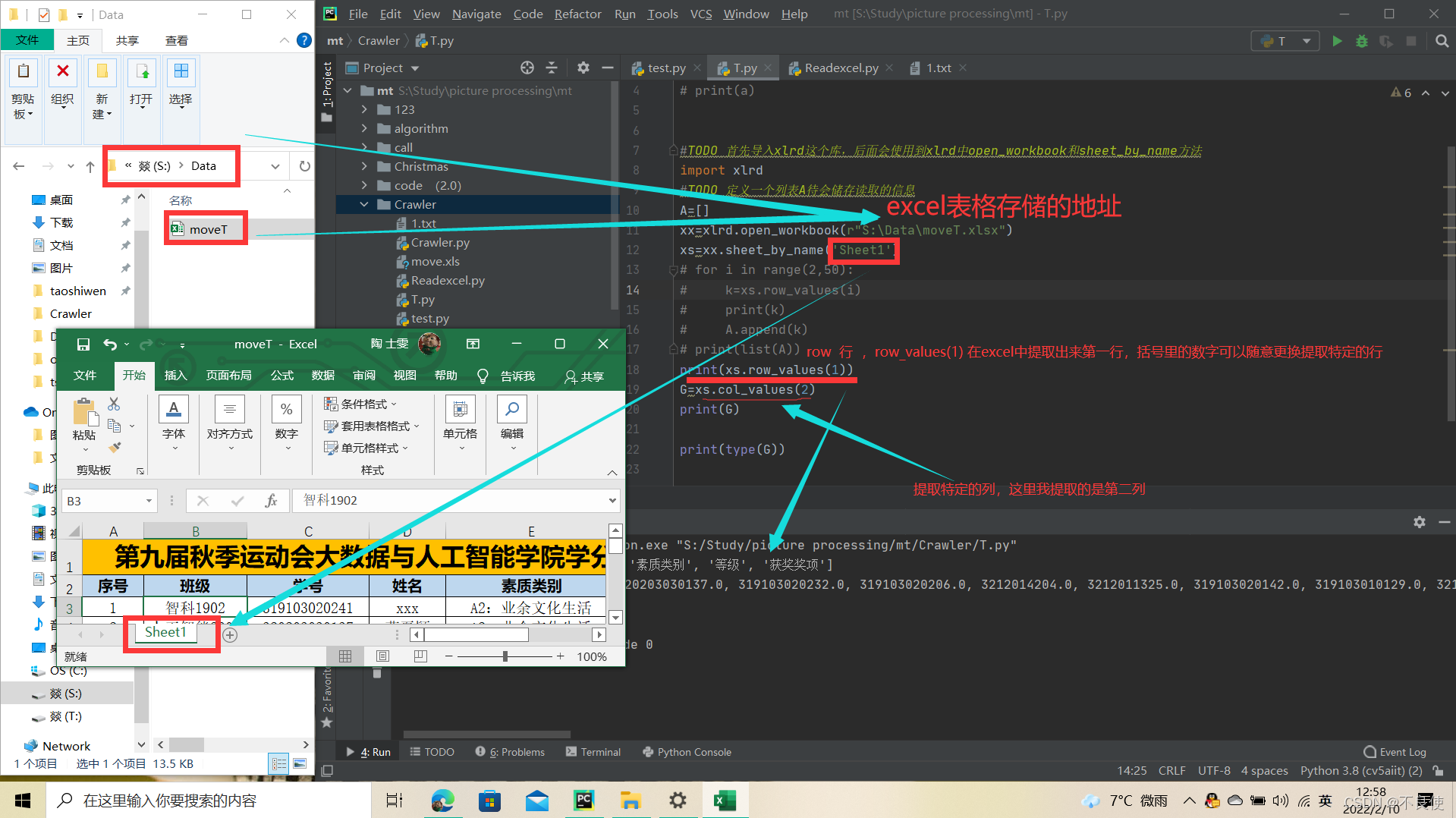
**- 您还可以看一下 曾贤志老师的【曾贤志】用Python处理Excel数据 - 第1季 基础篇课程中的 1.4 安装Python集成开发工具PyCharm小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
回答:
读取Excel表格的一般步骤如下:
1.使用xlrd库导入Excel文件,调用open_workbook方法打开Excel文件,使用sheet_by_name方法或sheet_by_index方法读取指定的sheet页; 2.遍历sheet页上的每一行或者每一列,选中需要读取的数据; 3.如果需要整理数据,可以对数据进行清洗和处理; 4.将所需的数据以列表或其他数据类型的形式存储起来。 具体的注意事项如下: 1.文件路径应该正确无误,否则会提示文件不存在的错误。 2.如果读取的数据需要整理处理,则需要对数据进行清洗和处理,才能得到正确的结果。 3.如果写入的数据是数字,应当不加引号,为了后期操作时能直接进行数值计算;如果写入的数据为字符串,则需要加上引号。 代码示例如下:
导入xlrd库,用于读取Excel文件
import xlrd
打开Excel文件并读取指定sheet页
workbook = xlrd.open_workbook(r"example.xlsx") worksheet = workbook.sheet_by_name("Sheet1")
定义一个列表,待会儿存储读取的信息
data = []
读取每一列的数据,并存入data中,可以根据需要修改从哪一行开始读取,读取到哪一行
for i in range(1, worksheet.nrows): row_data = worksheet.row_values(i) data.append(row_data)
可以对data进行处理和清洗操作
输出data
print(data)
如果要使用pandas库来读取Excel,则代码如下:
import pandas as pd
读取Excel文件
df = pd.read_excel("example.xlsx", sheet_name="Sheet1")
处理和清洗数据
输出dataframe
print(df)
如果需要写入数据,则可以使用xlsxwriter库,示例如下:
import xlsxwriter
新建excel文件并指定文件名
workbook = xlsxwriter.Workbook('example.xlsx')
添加sheet页,并指定sheet名字
worksheet = workbook.add_worksheet('Sheet1')
写入数据,可以使用write方法将单个数据写入指定的单元格,也可以使用write_row方法按行写入多个数据,使用write_column方法按列写入多个数据
worksheet.write('A1', 'Hello') worksheet.write_row('A2', ['name', 'age', 'gender']) worksheet.write_column('B2', ['Tom', 18, 'Male'])
关闭并保存文件
workbook.close()
这两个路径不一致,你用的是左边的这个路径吗,修改一下撒

import pandas as pd
# 读取Excel文件
excel_file = pd.ExcelFile('excelfile.xlsx')
# 读取指定sheet
sheet_name = 'Sheet1'
df = pd.read_excel(excel_file, sheet_name=sheet_name)
# 打印数据框
print(df)