MySQL单表数据量超大
mysql单表数据量太大,怎么处理,单表数据超过2亿,是需要分表吗,会有什么问题呢,对现有数据有多大影响呢
超过这么大,如果这个表的查询需求不大,也能凑合着运行。不过建议分库分表,提前准备,避免哪天出问题措手不及。
超2亿了还不分吗😂😂
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7677919
- 你也可以参考下这篇文章:MySQL中究竟什么是数据、什么是数据库,数据库的定义又是什么呢?
- 同时,你还可以查看手册:MySQL 字符集、对齐方式、统一编码 列的字符集和排序 中的内容
- 除此之外, 这篇博客: 【MySQL系列2】深入分析MySQL索引的存储结构和优化方案,看完这篇再也不怕面试官问索引了中的 非聚集索引 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
除了主键索引之外的其他索引都是非聚集索引,既然聚集索引的索引键值和数据行存放在一起,而聚集索引又只有一个,那么非聚集索引又是怎么存储数据的呢?接下来要画重点了哈:
非聚集索引的叶子节点存储的是当前索引的键值和主键索引的键值。大致结构如下图所示: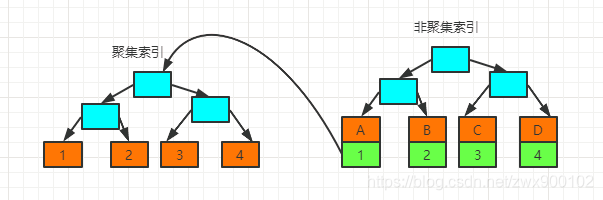
所以非聚集索引查询数据和聚集索引查询数据是不同的,因为非聚集索引的叶子节点只有当前索引的键值和主键的键值,也就是说查询数据的时候获取到非聚集索引的叶子节点只能拿到当前索引值和主键索引值。- 您还可以看一下 吴京忠老师的MySQL 备份与恢复详解(高低版本 迁移;不同字符集 相互转换;表课程中的 02. 逻辑备份:单表还原 和 多表还原小节, 巩固相关知识点
2亿数据不优化还能查得动吗?性能下降是必然的。
推荐:
1.将表拆分为多个区域,每个区域包含一定数量的行,这样可以提高查询性能。可以使用 MySQL 的 PARTITION 关键字来创建分区表。
2. 对表中的关键字进行索引,以提高查询效率。可以考虑使用全文索引、B树索引等高效的索引类型。
3. 对数据进行压缩,以减少数据量。可以使用 MySQL 的 OPTIMIZE TABLE 命令来压缩表。
4.对数据进行缓存,做一个冷热分离,访问频繁的数据放缓存。
5.分析执行计划
6.就这些吧