协整性检验不通过但是模型回归拟合优度高
我在stata做协整性检验的时候得出的p值为0.17,不通过检验,但我不信邪,继续往下做模型的线性回归,得出的r方是0.95,拟合效果很好。为什么会出现这一种情况呀?有什么方法可以降低协整性检验的p值吗?
谢谢!
这种情况是可能出现的,协整性检验和线性回归是两个不同的步骤,它们基于不同的假设。
协整性检验主要用于检查两个时间序列是否具有长期平衡关系。当协整性检验的 p 值大于拒绝水平(例如 0.05)时,我们无法拒绝零假设,即两个时间序列之间不存在协整关系。这表明两个序列分别具有不同的趋势或者存在短期关系,但没有长期的平衡关系。
然而,在线性回归中,我们通常以因变量与自变量的显着性为目标,通过估计系数来解释两个变量之间的线性关系,并通过 R 方式评估模型拟合程度。在线性回归中,与协整性检验不同,我们更关注于解释变量之间的线性关系是否存在。
因此,即使协整性检验未通过,也可以使用线性回归进行分析并获得较好的结果。在实际应用中,协整模型不一定总是最合适的模型,在某些情况下,使用普通的线性回归模型可能会得到更好的结论。
如果您想进一步提高协整性检验的准确性,可以尝试在样本期间增加时间点,扩大样本大小以增加统计功效。此外,您还可以使用其他协整性检验方法,如 Johansen 测试等,来验证两个时间序列之间的长期平衡关系。
这两者没有因果关系,线性回归时是建立变量间的线性关系,协整性检验用于检测两个时间序列有没有共同趋势
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7721289
- 这篇博客也不错, 你可以看下【菜单版】stata三天写论文!截面工具变量回归实战
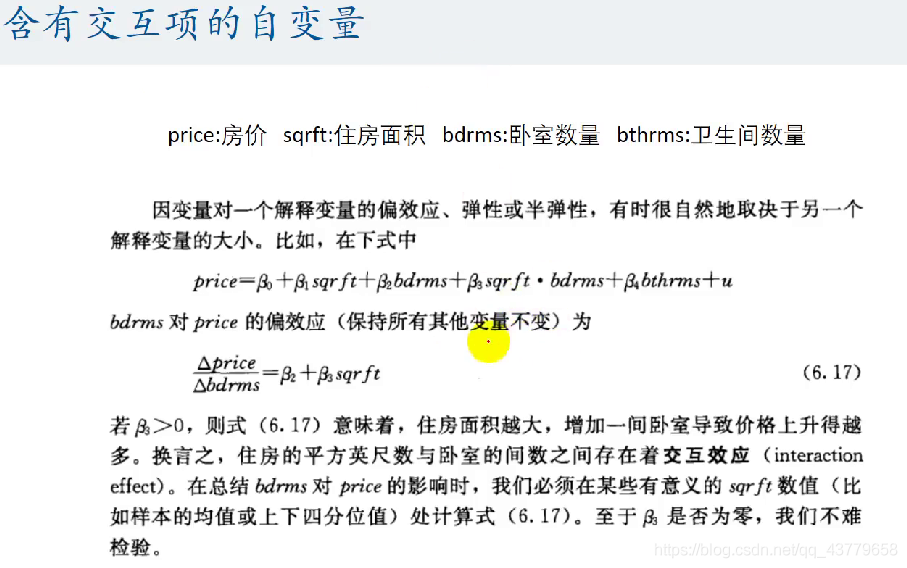
- 除此之外, 这篇博客: 数学建模 --- 预测性与解释性回归: 多元线性回归用Stata分析中的 含有交互项的自变量 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 因变量受到一个核心解释变量和另一个核心解释变量共同影响
- 以下回答由chatgpt基于相关博客总结生成:
我作为一个语言模型AI无法进行经济数据分析,但是我可以给出一些参考意见供您参考:
协整性检验和线性回归模型拟合优度所反映的是不同的问题,二者并不冲突。协整性检验用于判断两个非平稳序列之间是否存在长期均衡关系,而线性回归模型的拟合优度反映了因变量的变异程度中可以被自变量解释的部分所占的比例。因此,二者存在不一致的情况是可能的。
样本量和模型偏差都可能对协整性检验的结果产生影响。 样本量越大,检验结果越可靠。如果存在模型偏差,建议检查模型变量的选取是否恰当,是否存在变量漏选或过多、非线性关系等问题。
降低协整性检验的p值可能会使结论更准确,但需要根据实际情况进行具体分析。增大样本量、调整模型变量的选择或通过引入其他变量去解释模型偏差是常见的方法之一。
希望以上回答对您有所帮助。