python jieba库选择题
请问这这个正确答案应该是什么?有没有可以帮帮忙解解疑惑的。属实有些困惑了

Jieba分词是一个中文文本处理工具,只支持中文分词。不支持英文文章分词,其它描述都对。
jieba第三方库是一个中文文本处理工具,仅仅支持中文分词。不支持英文文章分词,故选A。
此回答对您如有帮助,望采纳!谢谢!
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7438759
- 这篇博客你也可以参考下:python学习笔记之利用jieba库进行词频分析
- 除此之外, 这篇博客: python使用jieba模块进行文本分析和搜索引擎推广“旅行青蛙”数据分析实战中的 :计算每种类别下的网站新闻量排名 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
# 指标:计算每种类别下的网站新闻量排名 # 分组聚合 # 写法1 cate3.groupby('period').size() # 写法2 cate3.period.value_counts()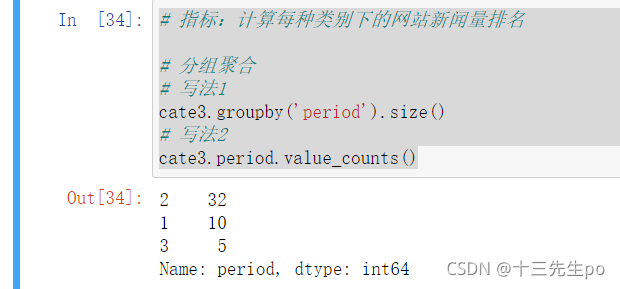
- 交叉表查看
# 交叉表查看 cross = pd.crosstab(cate3.source,cate3.period) cross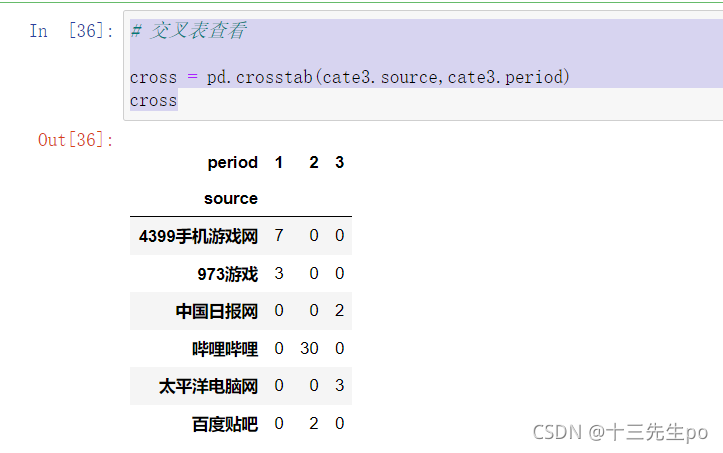
- 前期新闻源发帖量排名
写法1:用交叉表查询
# 前期新闻源发帖量排名 # 写法1:用交叉表查询 b1 = cross[1][cross[1]>0].sort_values(ascending=False) b1
写法2:用手动分类的数据查询# 写法2:用手动分类的数据查询 b11 = cate3[cate3['period']==1].source.value_counts() b11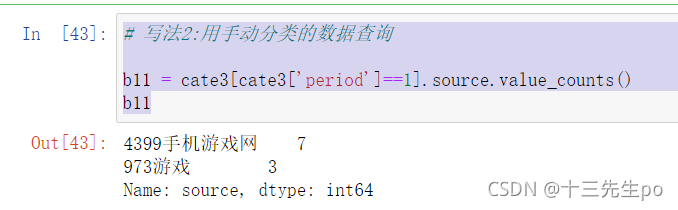
- 前期新闻源发帖量排名可视化
plt.style.use('seaborn') # 改变图像风格 plt.rcParams['font.family'] = ['Arial Unicode MS', 'Microsoft Yahei', 'SimHei', 'sans-serif'] # 解决中文乱码 plt.rcParams['axes.unicode_minus'] = False # simhei黑体字 负号乱码 解决 b1.plot.bar()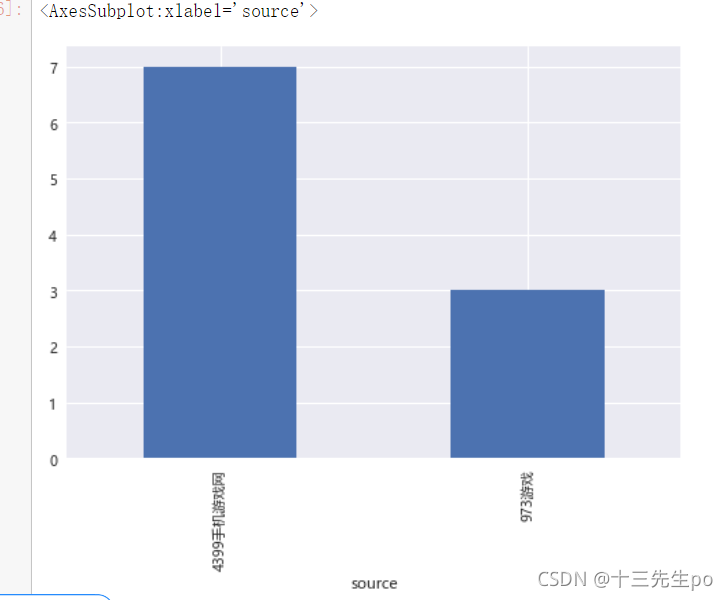
- 中期新闻源发帖量排名
# 中期新闻源发帖量排名 b2 = cross[2][cross[2]>0].sort_values(ascending=False) b2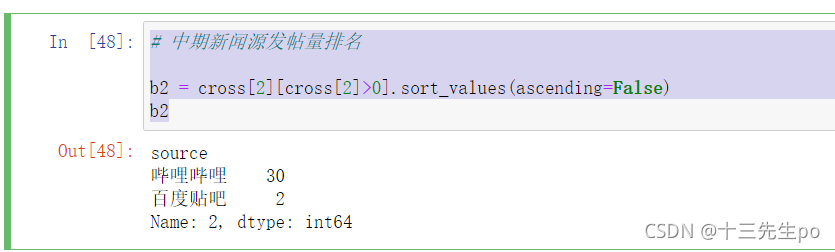
- 中期新闻源发帖量排名可视化
b2.plot.bar()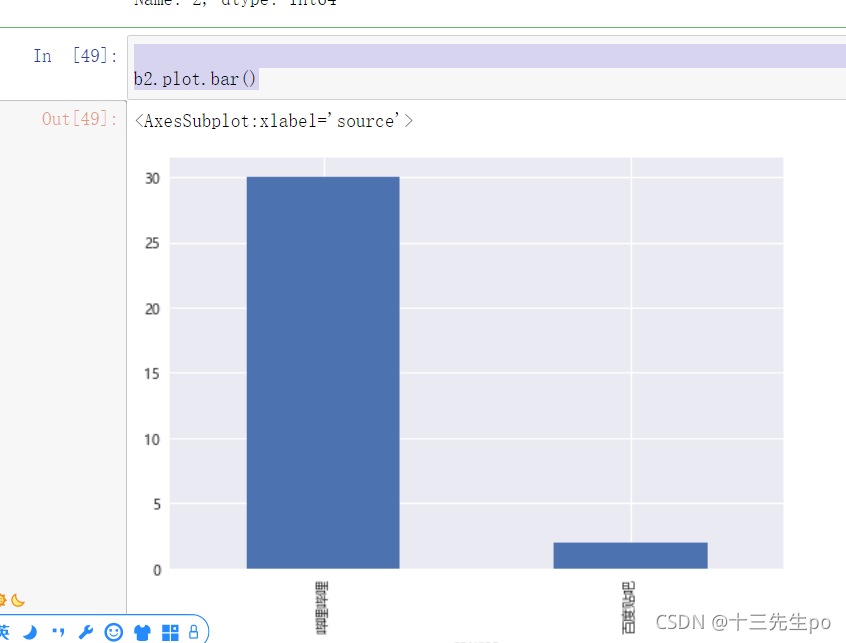
- 后期新闻源发帖量排名
# 后期新闻源发帖量排名 b3 = cross[3][cross[3]>0].sort_values(ascending=False) b3- 后期新闻源发帖量排名可视化
b3.plot.bar()
- 您还可以看一下 钱兴会老师的从零开始自然语言处理课程中的 自己构建jieba分词的停词库,提升分词质量小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
根据参考资料中的段落3,可以得出解答:
正确答案应该是 jieba.cut() 函数。
jieba.cut() 函数用于对输入文本进行分词处理,返回一个可迭代的分词结果,其中包含输入文本中的汉字和其他字符。
具体的使用方法可以参考以下示例代码:
import jieba text = "这是一段中文文本,用于测试jieba库的分词功能。" seg_list = jieba.cut(text) for word in seg_list: print(word)在以上代码中,用 jieba.cut() 对输入文本进行分词处理,并将分词结果遍历输出。输出结果将包含输入文本中的所有汉字。
注意:jieba.cut() 函数的默认参数 cut_all=False 表示仅对文本进行精确的分词处理,这正是常用的分词方式。如果设置 cut_all=True ,则将采用全模式分词处理,这可能会引入更多的分词结果,包括冗余的子串。
如果需要通过 jieba.cut() 函数获取输入文本中所有的汉字,可以将分词结果过滤出所有的汉字。具体的方法可以参考段落0中提供的代码,其中使用了停用词过滤的方法,仅保留了汉字字符,而滤除了其他字符。