浏览器爬虫怎么获取指定元素
python浏览器爬虫怎么获取指定元素的内容,有哪些好用的库可以使用呢?
可以试试xpath,使用起来非常方便,直接可以根据指定的表达式获取到元素xpath
- requests库,先获取response,然后通过beautifulSoup进行解析,然后获取到指定元素的内容
- selenium库,模拟用户操作,到达指定页面,然后获取指定元素内容。
- Scrapy库,专门的爬虫库
等等
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7763982
- 你也可以参考下这篇文章:项目记录一:用Python识别图片中指定颜色标记块并绘制其最小矩形框以及坐标点
- 你还可以看下python参考手册中的 python- 预定义的清理操作
- 除此之外, 这篇博客: 【全网首发】言简意赅的Python全套语法,内附详细知识点和思维导图!【强烈建议收藏!】中的 知识点思维导图 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
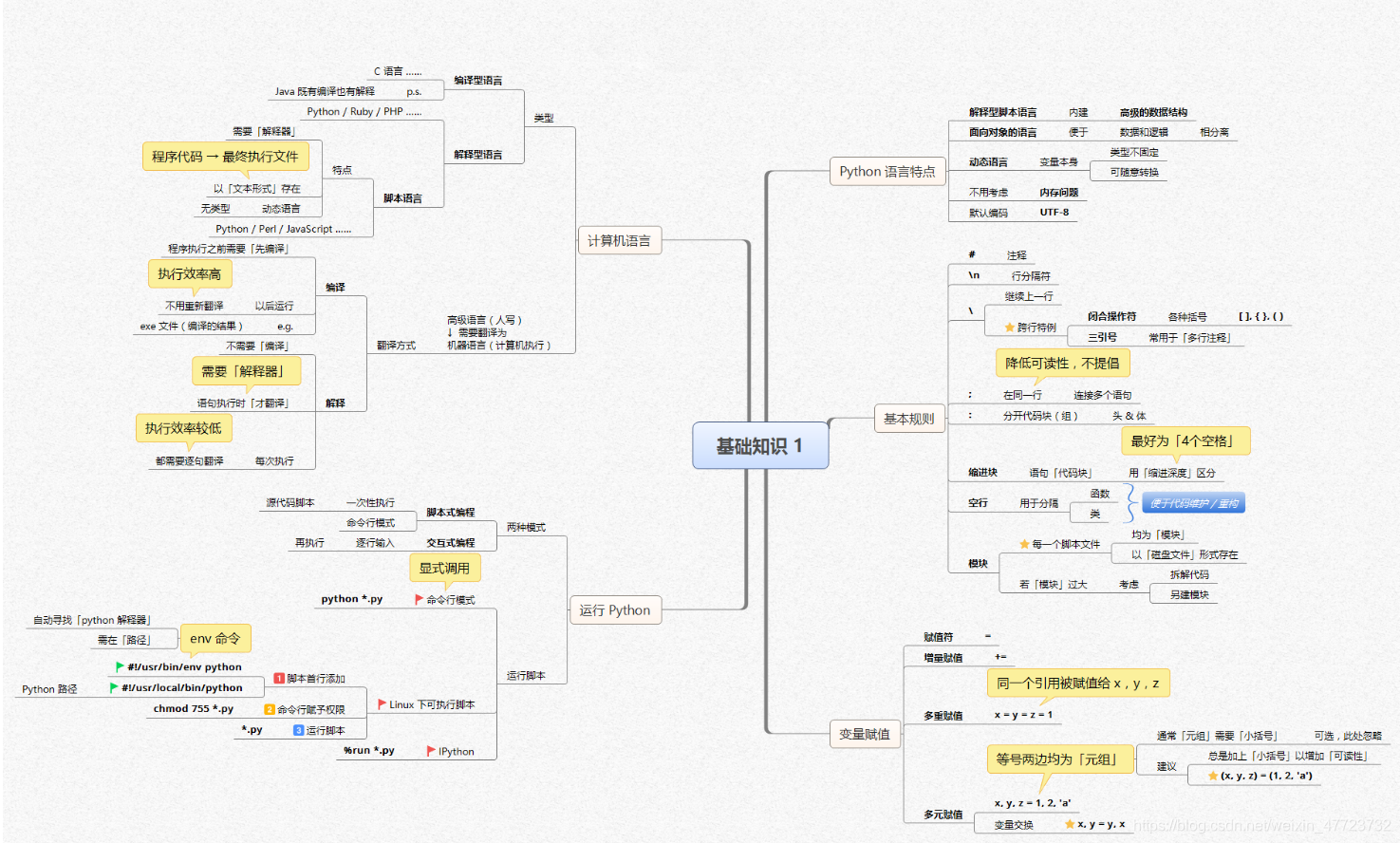
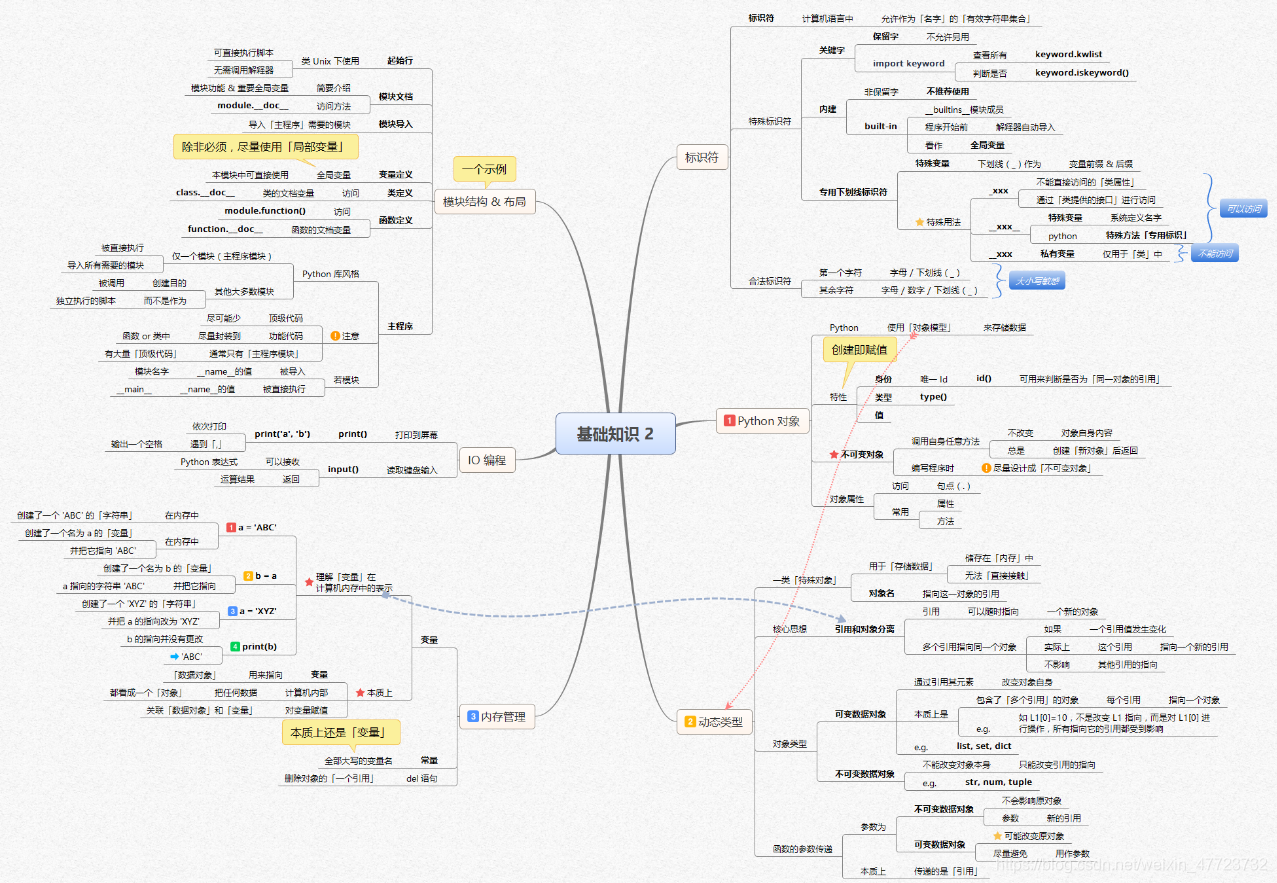
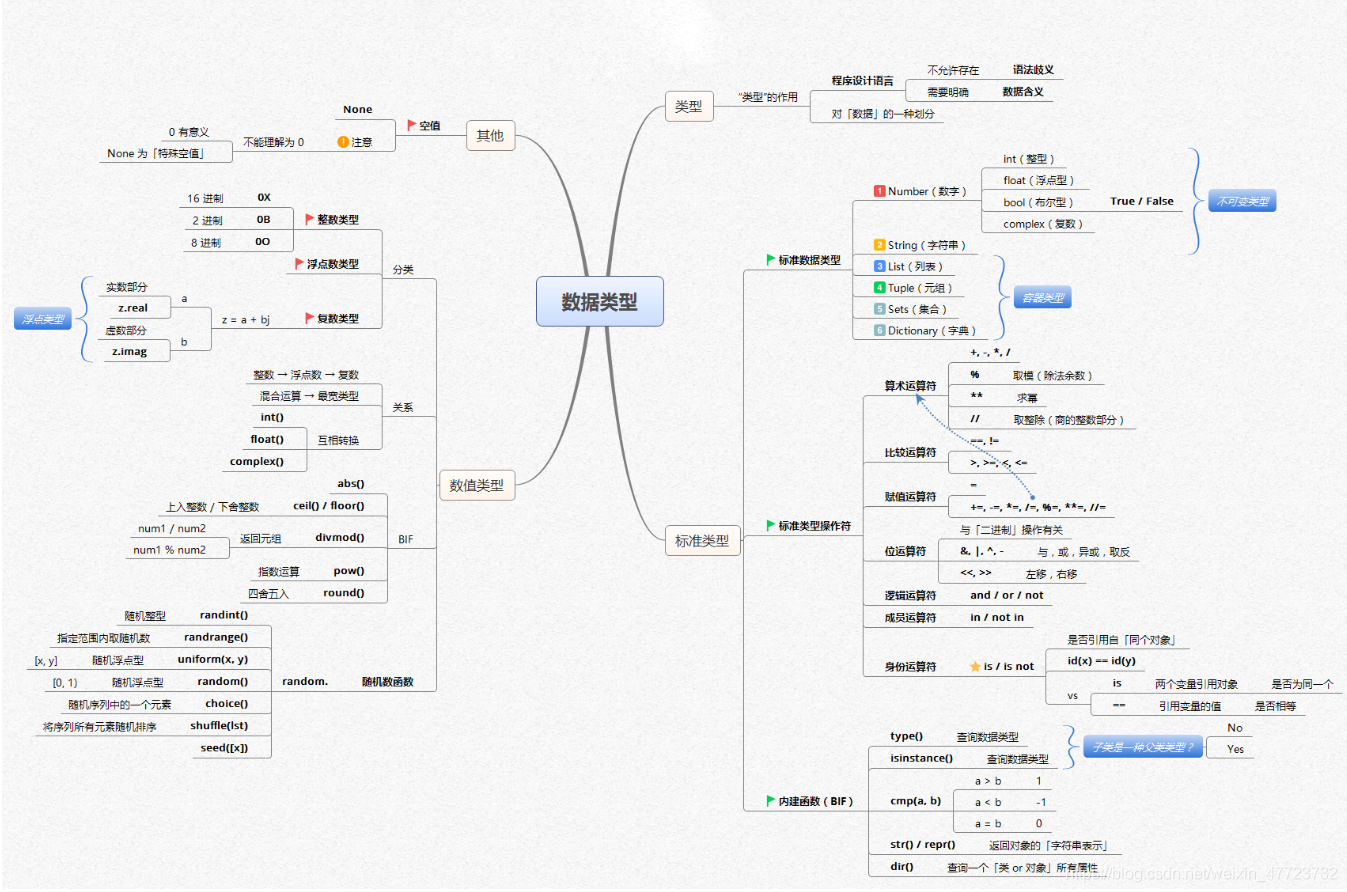
- 您还可以看一下 jeevan老师的Python量化交易,大操手量化投资系列课程之内功修炼篇课程中的 编程语言之Python环境安装小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
回答:
要使用Python编写浏览器爬虫获取特定元素的内容,可以使用一些Python开发的爬虫框架,如Scrapy和BeautifulSoup等,也可以使用Python的selenium库来模拟浏览器操作。
下面以使用selenium库为例,介绍具体的步骤:
安装selenium库:可以使用
pip install selenium命令进行安装。下载适合自己操作系统和浏览器版本的driver驱动程序,例如Chrome浏览器需要下载ChromeDriver。
导入selenium库:
from selenium import webdriver- 创建一个webdriver对象,并指定浏览器驱动路径:
driver = webdriver.Chrome('/path/to/chromedriver')- 使用webdriver对象打开一个网页:
driver.get('http://example.com')- 使用selenium库提供的方法来找到网页中需要获取的特定元素:
例如,通过标签名查找:
element = driver.find_element_by_tag_name('h1')或者通过链接文本查找:
element = driver.find_element_by_link_text('Example Page')还可以使用其他的selenium库提供的查找方法,如以下查找方法:
- find_element_by_css_selector(css_selector):通过CSS选择器查找元素。
- find_elements_by_name(name):通过元素的name属性查找元素。
- find_elements_by_xpath(xpath):通过XPath查找元素。
- find_elements_by_class_name(class_name):通过class name查找元素。
find_elements_by_id(id):通过元素的ID属性查找元素。
获取元素的内容:
使用
get_attribute()方法可以获取元素的属性值,使用text属性可以获取元素的文本内容。例如,获取元素的文本内容:
content = element.text- 关闭浏览器:
driver.quit()使用上面的步骤,就可以使用Python浏览器爬虫获取特定元素的内容了。
另外,Python的爬虫框架Scrapy也提供了类似的功能,可以通过Scrapy的Selector对象来选择网页中的特定元素,并且可以支持XPath、CSS选择器等语法。
示例代码:
import scrapy class ExampleSpider(scrapy.Spider): name = 'example' start_urls = ['http://example.com'] def parse(self, response): h1 = response.css('h1::text').get() yield {'title': h1}上面的示例代码使用Scrapy爬虫框架获取网页中的h1标签,代码中使用了CSS选择器语法来选择元素,然后使用
yield返回获取到的内容。需要注意的是,爬虫需要遵守网站的robots.txt规则。在爬虫过程中,应该避免对网站造成不必要的负荷。