用vscode使用pytorch出现的问题
vscode中使用pytorch,终端中显示GPU版torch可用,编译器输出False。


请问这是为什么,怎么解决
- 这篇博客: 动手学深度学习V2.0(Pytorch)——31. 深度学习硬件:CPU 和 GPU中的 w.grad就会消失(梯度参数变为false)。这是为什么呢?在torch.nograd下执行的 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
是一个程序问题,和python新建变量的机制有关。
- 使用
w-=,是一直对w进行本地操作 - 而使用
w=w-lr*w.grad,其实是等式右边进行计算,然后赋值给一个新的w,所以新的那个w就是一个普通的Tensor,而不是parameter,没有.grad属性,所以是False
一直记得好像在哪里看到过这个公式更新,后来找了一下,发现是在:
- 第8节:线性回归,
- 我记录的文章位于:动手学深度学习V2.0(Pytorch)——8.线性回归,点击目录里的基础优化方法-梯度下降

PPT里确实是这个公式,可能是有点误导性质 - 我记录的代码位于github的一个jupyter文件,点击这里
- 如果打不开,可以去看教材文档对应章节,点击这里
验证代码如下(使用的就是线性回归从头实现的代码,进行以下简单改动即可):
# 定义优化算法 def sgd(params,lr,batch_size): with torch.no_grad(): for param in params: print(f"更新前param的id为:{id(param)}") param-=lr*param.grad/batch_size print(f"更新后param的id为:{id(param)}") break # 添加break,只查看一个参数内存地址变化情况 # 训练 lr=2 num_epoches=1 net=linreg loss=squared_loss for epoch in range(num_epoches): for X,y in data_iter(batch_size,features,labels): l=loss(net(X,w,b),y) l.sum().backward() sgd([w,b],lr,batch_size) break # 添加break,只查看更新一次的情况 > 更新前param的id为:140308589009168 更新后param的id为:140308589009168 # 将梯度公式进行修改,改为不使用自增自减的,再运行,结果如下: > 更新前param的id为:140308589009168 更新后param的id为:140308644360432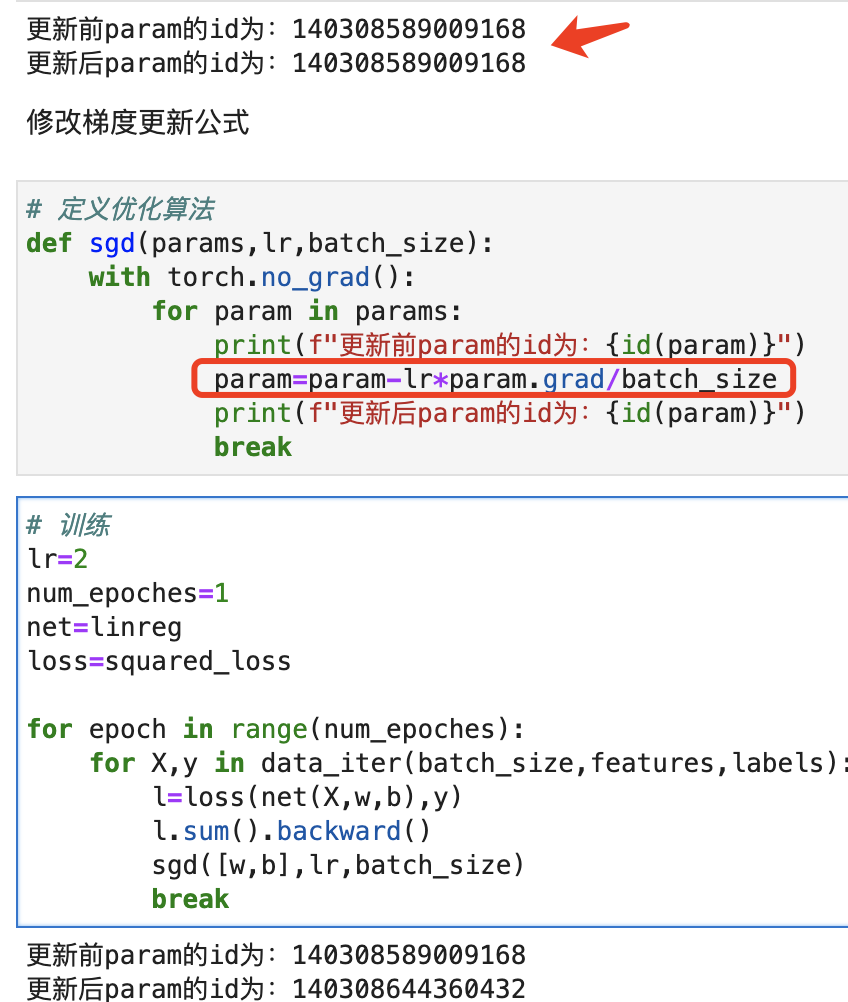
所以,确实可以说明,自增自减运算是本地操作,赋值运算会新建一个Tensor(没有grad的那种)更进一步,如果说
w=w-xxx会创建一个没有grad的tensor(可以打印一下更新前后param的type,新建的确实是Tensor,而不是普通的变量),那说明pytorch对这个=进行了重载。找找源代码- 没找到/因为看不懂,但是确实从结果可以知道是重载了,所以
赋值运算符才会新建一个 Tensor变量, - 参考:PyTorch的初始化
- 感觉上实现应该在:这个文件,点击这里,可惜是cpp的,看起来太费劲了
- 使用