AODnet图像处理pytorch去雾

这是什么问题呀大一第一次碰科研导师布置的代码调试真的啥也不知道不知道你这个问题是否已经解决, 如果还没有解决的话:
- 你可以参考下这篇文章:【去雾】|去雾算法AODNet pytorch 雾天数据集下载链接
- 除此之外, 这篇博客: Pytorch ----注意力机制与自注意力机制的代码详解与使用中的 5、AAnet 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
self attention是
注意力机制 中的一种,也是transformer中的重要组成部分,利用输入样本自身的关系构建注意力模型。 自 注意力机制 要解决的问题是:当神经网络的输入是多个大小不一样的向量,并且可能因为不同向量之间有一定的关系,而在训练时却无法充分发挥这些关系,导致模型训练结果较差。self-attention 最终得到的是:给定当前输入样本( 为了更好地理解,把输入进行拆解),产生一个输出,假设这个输出能看到所有输入的样本信息,那么这个输出是序列中所有样本的加权和,根据不同权重选择自己的注意力点。本质上,对于每个输入向量,Self-Attention产生一个向量,该向量在其邻近向量上加权求和,其中权重由单词之间的关系或连通性决定。
注意力机制可以分为三步:一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均。
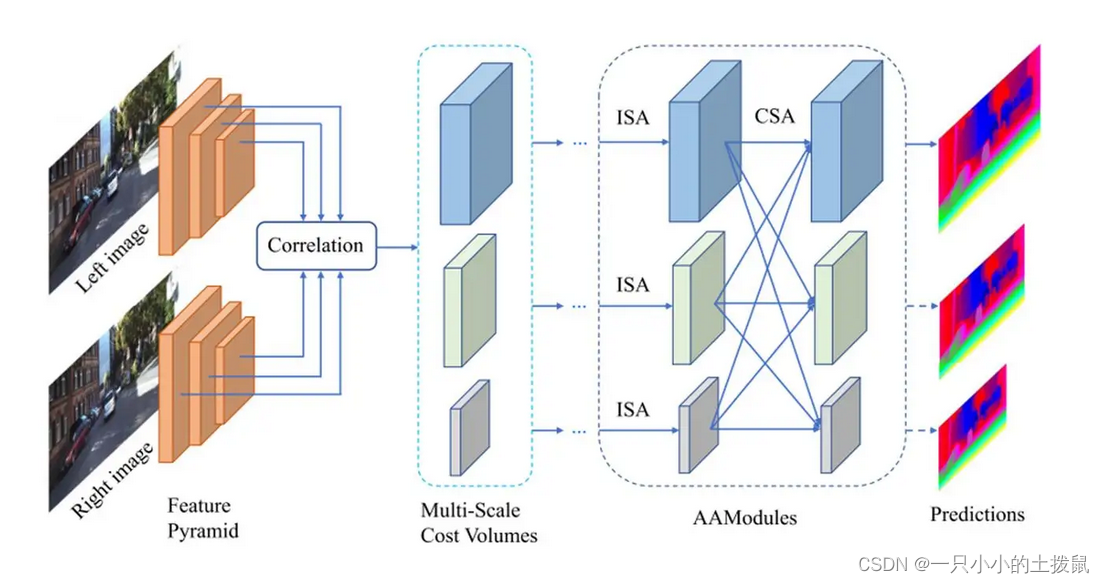
AANet,它由两个模块组成:同尺度聚合模块(ISA)和跨尺度聚合模块(CSA)。AANet可用来代替基于匹配代价体(cost volume)的3D卷积,在加快推理速度的同时保持较高的准确率。 对于AANet而言,其网络结构大致可以分成三部分。第一部分是特征提取,即利用CNN卷积得到不同尺度的特征。
第二部分是“代价聚合”,包括“匹配代价计算”(Multi-Scale Cost Volumes)和“多尺度代价融合”(AAModules)。
第三部分是深度图优化部分
PyTorch版本的实现(参考)
代码:https://github.com/leaderj1001/Attention-Augmented-Conv2d
论文:https://arxiv.org/pdf/1904.09925.pdf
class AugmentedConv(nn.Module): def __init__(self, in_channels, out_channels, kernel_size, dk, dv, Nh, shape=0, relative=False, stride=1): super(AugmentedConv, self).__init__() self.in_channels = in_channels self.out_channels = out_channels self.kernel_size = kernel_size self.dk = dk self.dv = dv self.Nh = Nh self.shape = shape self.relative = relative self.stride = stride self.padding = (self.kernel_size - 1) // 2 assert self.Nh != 0, "integer division or modulo by zero, Nh >= 1" assert self.dk % self.Nh == 0, "dk should be divided by Nh. (example: out_channels: 20, dk: 40, Nh: 4)" assert self.dv % self.Nh == 0, "dv should be divided by Nh. (example: out_channels: 20, dv: 4, Nh: 4)" assert stride in [1, 2], str(stride) + " Up to 2 strides are allowed." self.conv_out = nn.Conv2d(self.in_channels, self.out_channels - self.dv, self.kernel_size, stride=stride, padding=self.padding) self.qkv_conv = nn.Conv2d(self.in_channels, 2 * self.dk + self.dv, kernel_size=self.kernel_size, stride=stride, padding=self.padding) self.attn_out = nn.Conv2d(self.dv, self.dv, kernel_size=1, stride=1) if self.relative: self.key_rel_w = nn.Parameter(torch.randn((2 * self.shape - 1, dk // Nh), requires_grad=True)) self.key_rel_h = nn.Parameter(torch.randn((2 * self.shape - 1, dk // Nh), requires_grad=True)) def forward(self, x): # Input x (batch_size, channels, height, width) # batch, _, height, width = x.size() # conv_out (batch_size, out_channels, height, width) conv_out = self.conv_out(x) batch, _, height, width = conv_out.size() # flat_q, flat_k, flat_v (batch_size, Nh, height * width, dvh or dkh) # dvh = dv / Nh, dkh = dk / Nh # q, k, v (batch_size, Nh, height, width, dv or dk) flat_q, flat_k, flat_v, q, k, v = self.compute_flat_qkv(x, self.dk, self.dv, self.Nh) logits = torch.matmul(flat_q.transpose(2, 3), flat_k) if self.relative: h_rel_logits, w_rel_logits = self.relative_logits(q) logits += h_rel_logits logits += w_rel_logits weights = F.softmax(logits, dim=-1) # attn_out (batch, Nh, height * width, dvh) attn_out = torch.matmul(weights, flat_v.transpose(2, 3)) attn_out = torch.reshape(attn_out, (batch, self.Nh, self.dv // self.Nh, height, width)) # combine_heads_2d (batch, out_channels, height, width) attn_out = self.combine_heads_2d(attn_out) attn_out = self.attn_out(attn_out) return torch.cat((conv_out, attn_out), dim=1) - 以下回答来自chatgpt:
鉴于参考资料与问题无关,以下是解决方案:
针对AODnet图像处理库在pytorch中进行去雾处理的问题,可以按照以下步骤逐一排查: 1. 确认代码的运行结果是否与期望的结果相同,确定代码是否存在问题。 2. 如果代码存在问题,可以尝试对代码进行调试,例如增加调试日志或打印中间结果,逐行排查代码的正确性。 3. 如果代码正确,但结果不符合期望,可以检查数据的输入是否正确,是否存在数据预处理或数据加载的问题。 4. 检查代码使用的库或依赖是否正确安装或版本是否匹配,例如是否缺少必要的库或使用了不合适的版本。 5. 如果以上步骤都没有发现问题,可以尝试寻求帮助,例如向开发者或其他相关专家提问或请求帮助。
根据所提供的信息,缺乏具体的代码和输出结果,因此无法针对具体问题给出更为详细的解决方案。建议向科研导师或其他相关人员寻求帮助,或者提供更为具体的信息以便其他人员给出更准确的建议。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^