yolov8,实例分割

谁能告诉我,这玩意是什么?
yolov8里面实例分割的目标像素点怎么找啊?
阴阳怪气:jia人们,谁懂啊?
如果您是人,我对您的耐心和工作量表示感谢以及跪拜;
如果您是AI,我不得不骂两句了....写的什么牛马,和问题都对不上
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7408653
- 你也可以参考下这篇文章:目标检测之YOLOv5算法分析
- 除此之外, 这篇博客: 运用yolov5人脸识别模型生成标准的一寸照视频中的 三:用人脸识别模型对图片识别,并且进行一寸照人脸的裁剪,保存为新的图片 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
这个时候就需要用到我们训练好的YOLOv5人脸识别模型了,利用训练好的YOLOv5人脸识别模型,在detect.py中对代码进行修改,读取出识别框的四个a、b、c、d坐标值。下列代码对应的是detect.py的第168行,直接在下面加即可
if save_img or save_crop or view_img: # Add bbox to image c = int(cls) # integer class label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}') annotator.box_label(xyxy, label, color=colors(c, True)) #xyxy中保存的就是识别框的四个坐标值,我们可以直接把它取出来用修改后的代码如下:
if save_img or save_crop or view_img: # Add bbox to image c = int(cls) # integer class label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}') annotator.box_label(xyxy, label, color=colors(c, True)) #xyxy中保存的就是识别框的四个坐标值,我们可以直接把它取出来用 # wrote by ym a = xyxy[0].item() b = xyxy[1].item() c = xyxy[2].item() d = xyxy[3].item() rate=1.3 w=c-a cw = int((a + c) / 2) h=d-b ch = int((d + b) / 2) h = int(413 * w / 295) box = (cw - rate * w, ch - rate * h, cw + rate * w, ch + rate * h) #print(box) #box保存的是识别框的四个坐标 # save_path保存的的是处理的每张图片的名字和路径,例如 runs/detect/exp52/133.jpg #print(save_dir) # 值为runs/detect/exp19 #p保存的是每张待处理图片的路径! img=Image.open(str(p)) print(p) ss = str(p).rsplit("\\",1)[1] im=img.crop(box) im2 = im.resize((295, 413),Image.ANTIALIAS) if save_crop: save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)关于对人脸的一寸照裁剪,参考如下:https://aistudio.baidu.com/aistudio/projectdetail/438751
只要从中截取一寸照裁剪的代码即可同时在detect.py的下面配置文件处进行修改:

只需要修改训练好的模型pt文件、需要识别的人脸图片保存的路径和yaml配置文件就可以了。顺便贴上我的face.yaml文件的配置:
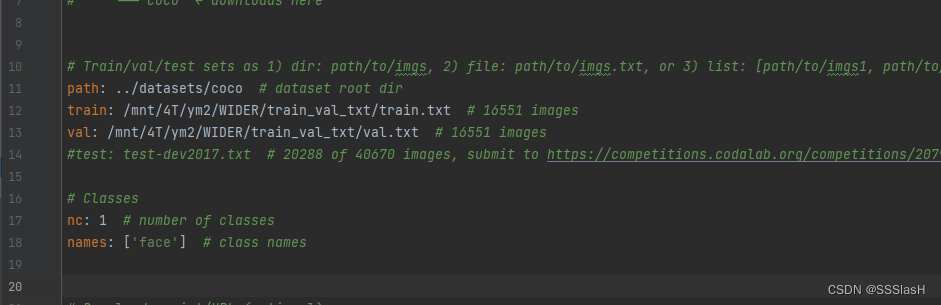
由于只需要训练人脸一个目标,因此nc设为1即可- 您还可以看一下 白勇老师的YOLOv5实战垃圾分类目标检测课程中的 测试训练出的网络模型及性能统计小节, 巩固相关知识点