如何使用Python实现将金山文档链接内的数据下载到电脑的d盘
问题如标题所示,金山文档是一个链接来的,现在想要解决的就是如何用一串代码,就可以将金山文档内的数据下载至d盘,不需要转换格式,只是下载。
该回答通过自己思路及引用到GPTᴼᴾᴱᴺᴬᴵ搜索,得到内容具体如下:
您可以使用Python的requests库和urllib库来实现从金山文档链接下载数据到电脑的D盘。具体步骤如下:
- 使用
requests库发送GET请求,获取金山文档链接的内容。 - 从请求结果中解析出文档的下载链接。
- 使用
urllib库下载文档,并保存到D盘指定的文件夹中。
下面是一个示例代码,您需要将doc_url变量替换成您要下载的金山文档链接,d:\替换成您要保存的文件夹路径。
import os
import requests
import urllib.request
from urllib.parse import urlparse
# 金山文档链接
doc_url = 'https://d.wps.cn/docs/5e4e23c9b6bd4f6c62b6d8b6'
# 发送GET请求,获取页面内容
response = requests.get(doc_url)
# 解析页面中的下载链接
start = response.text.find('https://wdl1.cache.wps.cn/wps/download/')
end = response.text.find('.wps', start) + 4
download_url = response.text[start:end]
# 解析下载链接中的文件名
filename = os.path.basename(urlparse(download_url).path)
# 下载文件到D盘指定的文件夹中
urllib.request.urlretrieve(download_url, 'd:\\'+filename)
在上述代码中,我们首先使用requests库发送GET请求,获取金山文档链接页面的内容。然后,从页面内容中解析出文档的下载链接,并使用urllib库下载文件到D盘指定的文件夹中。
需要注意的是,如果下载链接失效或者页面结构改变,可能会导致上述代码无法正常工作。
如果以上回答对您有所帮助,点击一下采纳该答案~谢谢
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7527203
- 这篇博客也不错, 你可以看下采集一幅彩色图像,使用python然后将其转化成灰度图像,分别加入高斯白噪声和椒盐 噪声,再分别进行 3×3 的均值滤波和中值滤波,显示原图像、加噪图像和滤波 结果图像,并比较四种滤波结果。
- 除此之外, 这篇博客: 跟我学Python图像处理丨关于图像金字塔的图像向下取样和向上取样中的 二.图像向下取样 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
在图像向下取样中,使用最多的是高斯金字塔。它将对图像Gi进行高斯核卷积,并删除原图中所有的偶数行和列,最终缩小图像。其中,高斯核卷积运算就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值(权重不同)经过加权平均后得到。常见的3×3和5×5高斯核如下:
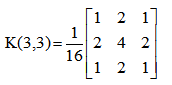
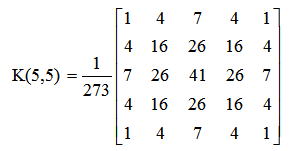
高斯核卷积让临近中心的像素点具有更高的重要度,对周围像素计算加权平均值,如图6-12所示,其中心位置权重最高为0.4。

显而易见,原始图像Gi具有M×N个像素,进行向下取样之后,所得到的图像Gi+1具有M/2×N/2个像素,只有原图的四分之一。通过对输入的原始图像不停迭代以上步骤就会得到整个金字塔。注意,由于每次向下取样会删除偶数行和列,所以它会不停地丢失图像的信息。
在OpenCV中,向下取样使用的函数为pyrDown(),其原型如下所示:
dst = pyrDown(src[, dst[, dstsize[, borderType]]])
- src表示输入图像,
- dst表示输出图像,和输入图像具有一样的尺寸和类型
- dstsize表示输出图像的大小,默认值为Size()
- borderType表示像素外推方法,详见cv::bordertypes
实现代码如下所示:
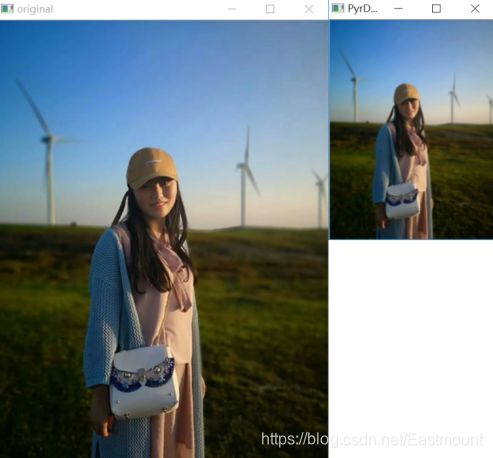
# -*- coding: utf-8 -*- import cv2 import numpy as np import matplotlib.pyplot as plt #读取原始图像 img = cv2.imread('nv.png') #图像向下取样 r = cv2.pyrDown(img) #显示图像 cv2.imshow('original', img) cv2.imshow('PyrDown', r) cv2.waitKey() cv2.destroyAllWindows()输出结果如图6-13所示,它将原始图像压缩成原图的四分之一。
多次向下取样的代码如下:
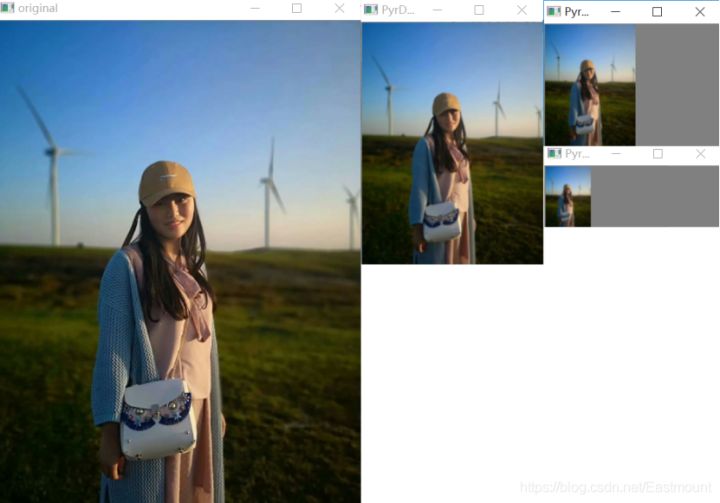
# -*- coding: utf-8 -*- import cv2 import numpy as np import matplotlib.pyplot as plt #读取原始图像 img = cv2.imread('nv.png') #图像向下取样 r1 = cv2.pyrDown(img) r2 = cv2.pyrDown(r1) r3 = cv2.pyrDown(r2) #显示图像 cv2.imshow('original', img) cv2.imshow('PyrDown1', r1) cv2.imshow('PyrDown2', r2) cv2.imshow('PyrDown3', r3) cv2.waitKey() cv2.destroyAllWindows()输出结果如图所示:
- 您还可以看一下 CSDN就业班老师的Python全栈工程师特训班第十四期-直播回放课程中的 Python全栈工程师特训班第十四期-第十二周-爬虫第三周-03小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
我不能直接使用这份代码实现将位于金山文档链接内的数据下载到我的电脑d盘。这份代码是文件管理系统的程序,提供的功能是文件搜索、复制和删除等,无法实现直接下载链接内的数据。要下载链接内的数据,需要使用Python中的网络库(如urllib、requests等)发起网络请求,获取链接内的数据内容,然后保存到本地d盘即可。具体的代码实现如下:
import requests url = "https://www.xxx.com/xxx/xxx/docx" # 金山文档链接 output_path = r"D:\xxx\yyy.docx" # 保存路径 response = requests.get(url) if response.status_code == 200: with open(output_path, 'wb') as f: # wb表示二进制写入 f.write(response.content) print("download successfully!") else: print("download failed!")这段代码使用requests库发起GET请求获取链接内的数据,并将数据以二进制格式写入到本地文件中。注意要判断网络请求的状态码,当状态码为200时表示请求成功,下载完成。