求网站(流量)日志数据集/服务器日志数据集
求网站日志数据集,web服务器日志数据集,nginx日志数据集,apache日志数据集,
数据集内包含数据越完整越好,可以做日志可视化系统的数据
有文件最好,也可以是下载链接,只要有用就多打赏的。
[](链接:https://pan.baidu.com/s/1A9r5xBmcU68TCJqifCshdw?pwd=finl
提取码:finl )这里面是日志原始文件和参考源码
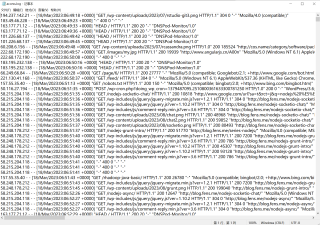
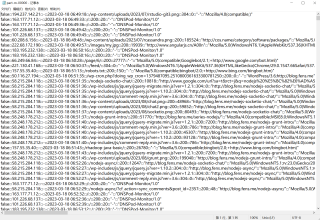
mapreduce 处理上面这个原始文件可以得到下面这样的结果文件
该回答引用GPTᴼᴾᴱᴺᴬᴵ
1. 公共数据集库:许多公共数据集库,如UCI Machine Learning Repository(https://archive.ics.uci.edu/ml/index.php)、Kaggle(https://www.kaggle.com/)等,提供了各种类型的数据集,包括网站日志数据集和服务器日志数据集。您可以通过这些网站搜索并下载符合您需求的日志数据集。
2. 开放数据源:一些开放数据源,如美国政府的数据门户网站(https://www.data.gov/)或各大学的开放数据资源库,也可能包含了网站日志数据集或服务器日志数据集。您可以通过这些网站进行搜索并下载相关数据集。
3. 日志生成器:如果您无法找到合适的现有日志数据集,您还可以考虑使用日志生成器工具来生成自定义的网站日志数据集或服务器日志数据集。例如,对于Nginx和Apache服务器,您可以使用日志生成器工具,如Fake Apache Log Generator(https://github.com/kiritbasu/Fake-Apache-Log-Generator)和Nginx Log Generator(https://github.com/kiritbasu/Fake-Apache-Log-Generator/tree/master/log_samples/nginx),来生成虚拟的日志数据。
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
这里有一些公开可用的日志数据集:
NASA HTTP Server Access Log:一份 NASA 服务器日志,其中包含约 200,000 条记录,涵盖了两个月的期间。数据集可以从该链接进行下载:http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html
AOL Search Query Logs:涵盖了 AOL 搜索引擎用户 90 天的搜索查询历史记录。数据集可以从该链接进行下载:http://research.microsoft.com/en-us/um/people/sdumais/aoldata/
AWStats Sample Pages:AWStats 是一种流行的服务器日志分析工具,提供了一些示例网站数据,可以用于测试。这些示例可以在 AWStats 的官方网站上找到:https://awstats.sourceforge.io/docs/awstats_sample.html
ELK Stack Sample Data:Elasticsearch、Logstash 和 Kibana(ELK Stack)是一个用于日志分析的流行工具,它们提供了一些样本数据,可以用于测试和学习。数据集可以从该链接进行下载:https://www.elastic.co/guide/en/kibana/current/tutorial-load-dataset.html
代码示例:
Python 中使用 pandas 库可以方便地读取和分析日志数据集。以下是一份读取 NASA HTTP Server Access Log 数据集的代码示例:
import pandas as pd
# 读取数据集
log = pd.read_csv("NASA_access_log_Jul95.gz",
compression="gzip",
header=None,
sep=" ",
quotechar='"',
error_bad_lines=False)
# 设定列名
log.columns = ["remote_host", "rfc931", "authuser", "date_time",
"request", "status", "bytes"]
# 转换时间格式
log["date_time"] = pd.to_datetime(log["date_time"], format="[dd/%b/%Y:%H:%M:%S")
# 输出前 5 条记录
print(log.head())
以上代码将 NASA HTTP Server Access Log 数据集中的 gzipped 文件读取后,设定数据集中的列名,并将时间格式转换为 pandas 中的 DateTime 格式。
希望这些
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/761530
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:从零开发短视频电商 Nginx日志格式详解、自定义日志格式、按天按月切割日志
- 除此之外, 这篇博客: 如何实现nginx动静分离与网页优化?了解一下?(Web服务器群集,版本号,缓存时间,日志切割,网页压缩,防盗链优化)中的 1.2:反向代理的原理是什么? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- Nginx不仅能作为Web服务器,还具有反向代理、负载均衡和缓存的功能
- Nginx通过 proxy模块实现将客户端的请求代理至上游服务器,此时ngInx与上游服务器的连接是通过http协议进行的
- Nginx在实现反向代理功能时的最重要指令为proxy pass,它能够并能够根据UR、客户端参数或其它的处理逻辑将用户请求调度至上游服务器
- 您还可以看一下 蒋小波老师的适合网络系统管理赛项的Nginx系列基础教程课程中的 第七节课:实战5:Nginx Web安全认证模块应用小节, 巩固相关知识点