关于#YOLO#classloss的问题
YOLOv5中的class loss数值越大越好还是越小越好,我在训练模型的时候这个值总是在变大,最后变成接近1了这对吗?
在YOLOv5中,class loss的数值越小越好。与其他深度学习模型一样,YOLOv5使用梯度下降优化算法来训练模型,通过最小化损失函数来更新模型参数,使得模型的输出结果更加准确。而class loss是YOLOv5损失函数中的一项,它用于评估检测结果中类别预测的准确性,因此数值越小表示检测结果越准确。
在训练过程中,如果class loss的数值不断增加,可能是由于以下原因之一:
1.数据集存在噪声或错误标注,导致了训练数据的不准确性,以及模型的泛化能力较差。
2.训练参数配置不当,如学习率设置过高或过低、批量大小不合适等,都可能影响到模型的收敛效果。
3.模型结构选择不合理,或者网络层数太少或太多,都可能导致训练过程出现过拟合或欠拟合等问题,进而影响到class loss的变化。
因此,在训练YOLOv5模型时,应该密切关注class loss的变化趋势,并尝试分析其原因,对训练过程进行调整和优化。当class loss的数值在训练过程中有所增加时,可以通过调整上述因素来限制其增长速度,以避免损失函数过大导致模型性能下降。最后,需要注意的是,在模型训练完全结束后,应该对模型进行评估并参考其他指标(如mAP)来判断模型的实际效果,并进行必要的改进和优化。
- 这篇博客: YOLO v3论文模型解读中的 Loss函数 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
https://blog.csdn.net/weixin_43384257/article/details/100986249
ps: 损失函数计算的为偏移量的损失,作者将真实的标签宽高转换为对应特征图尺寸上宽高的偏移量,然后与预测出的宽高偏移量计算误差。并不是将预测出的偏移转换为真实值和标签计算误差。 即计算的为偏移量的误差不是真实值之间的误差。同理中心点误差计算也是特征图上的中心点坐标。
特征图1的Yolov3的损失函数抽象表达式如下:
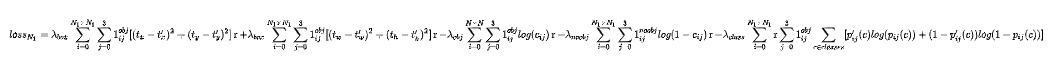

Yolov3 Loss为三个特征图Loss之和:
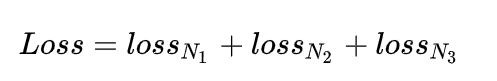

- 训练策略解释:
- ground truth为什么不按照中心点分配对应的预测box?
(1)在Yolov3的训练策略中,不再像Yolov1那样,每个cell负责中心落在该cell中的ground truth。原因是Yolov3一共产生3个特征图,3个特征图上的cell,中心是有重合的。训练时,可能最契合的是特征图1的第3个box,但是推理的时候特征图2的第1个box置信度最高。所以Yolov3的训练,不再按照ground truth中心点,严格分配指定cell,而是根据预测值寻找IOU最大的预测框作为正例。
(2)笔者实验结果:第一种,ground truth先从9个先验框中确定最接近的先验框,这样可以确定ground truth所属第几个特征图以及第几个box位置,之后根据中心点进一步分配。第二种,全部4032个输出框直接和ground truth计算IOU,取IOU最高的cell分配ground truth。第二种计算方式的IOU数值,往往都比第一种要高,这样wh与xy的loss较小,网络可以更加关注类别和置信度的学习;其次,在推理时,是按照置信度排序,再进行nms筛选,第二种训练方式,每次给ground truth分配的box都是最契合的box,给这样的box置信度打1的标签,更加合理,最接近的box,在推理时更容易被发现。
2. Yolov1中的置信度标签,就是预测框与真实框的IOU,Yolov3为什么是1?
(1)置信度意味着该预测框是或者不是一个真实物体,是一个二分类,所以标签是1、0更加合理。
(2)笔者实验结果:第一种:置信度标签取预测框与真实框的IOU;第二种:置信度标签取1。第一种的结果是,在训练时,有些预测框与真实框的IOU极限值就是0.7左右,置信度以0.7作为标签,置信度学习有一些偏差,最后学到的数值是0.5,0.6,那么假设推理时的激活阈值为0.7,这个检测框就被过滤掉了。但是IOU为0.7的预测框,其实已经是比较好的学习样例了。尤其是coco中的小像素物体,几个像素就可能很大程度影响IOU,所以第一种训练方法中,置信度的标签始终很小,无法有效学习,导致检测召回率不高。而检测框趋于收敛,IOU收敛至1,置信度就可以学习到1,这样的设想太过理想化。而使用第二种方法,召回率明显提升了很高。
3. 为什么有忽略样例?
(1)忽略样例是Yolov3中的点睛之笔。由于Yolov3使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分。比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。
(2)笔者实验结果:如果给全部的忽略样例置信度标签打0,那么最终的loss函数会变成 与 的拉扯,不管两个loss数值的权重怎么调整,或者网络预测趋向于大多数预测为负例,或者趋向于大多数预测为正例。而加入了忽略样例之后,网络才可以学习区分正负例。
- 优化器
作者在文中没有提及优化器,Adam,SGD等都可以用,github上Yolov3项目中,大多使用Adam优化器。
作者在文中没有提及优化器,Adam,SGD等都可以用,github上Yolov3项目中,大多使用Adam优化器。