请问如何把字符串末尾的0打印出来
请问如何把字符串末尾的0打印出来
比如
```c++
char str[]={"HEllo"}
不是说通常字符串的某位以0结束吗?怎么把str的末尾的0打印出来呢,另外为什么统计str的元素个数时,0并没有算在里面呢
```
字符串格式是规定以“\0”结尾,在答应的时候“\0”并不会显示,统计长度的时候也是统计有效长度。这单纯地只是一个标志位,如果没有这个标志,那么如果有两段字符串在内存中连续存储,就无法判断是两端字符串还是一段字符串。就像你上面这个字符串,在内存中存的是“\H\E\l\l\o\0”, 最后这个“\0”是加上了一个结束标志。
\0是字符串结束符,不是可见字符
不可见字符很多,比如空格就是个典型的不可见字符,它只能通过前后字符的位置间接看见
还有些字符是完全不可见的,连占位都没有
并不是所有字符都能打印出来
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7492759
- 这篇博客也不错, 你可以看下找出不重复的元素个数(先递增然后递减)
- 除此之外, 这篇博客: 菜鸟白嫖的牛客算法课程第一讲的复习中的 输入输出样例 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
输入 #1复制
10 20 40 32 67 40 20 89 300 400 15输出 #1复制
8 15 20 32 40 67 89 300 400NOIP 2006 普及组 第一题
题解1:暴力求解法:1.首先外层循环遍历数组,内层循环再次遍历,若发现两值相同,则将之剔除;2.冒泡法进行排序
#include<stdio.h> int main() { int N,i,j,count_0=0; scanf("%d",&N); int array[1001]; for(i=1;i<=N;i++) scanf("%d",&array[i]); for(i=1;i<N;i++) { if(array[i]==0) continue; for(j=i+1;j<=N;j++) if(array[i]==array[j]) { array[j]=0; count_0++; } } for(i=N;i>1;i--) for(j=1;j<=i-1;j++) if(array[j]>array[j+1]) { int temp=array[j]; array[j]=array[j+1]; array[j+1]=temp; } printf("%d\n",N-count_0); for(i=1;i<=N;i++) if(array[i]) printf("%d ",array[i]); return 0; }这种算法的时间复杂度是O(n^2),但是这个算法在洛谷上面可以运行出来。
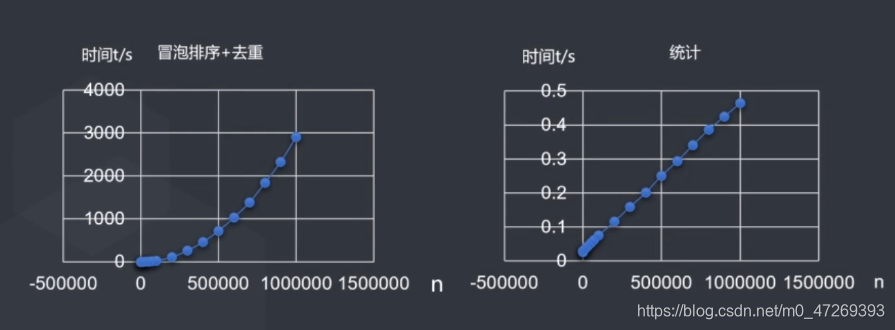
暴力求解法2:可以先进行排序,再进行去重操作,但是洛谷题目要求输出不重复的个数,我不太会写如何在冒泡排序中记录重复元素的个数;(冒泡排序+去重)这种代码的运行时间大概是第一种的1/2;
统计思想算法(桶排序)3:利用一个数组b[n]={0},其中b[i]代表i这个数是否出现过,若i元素出现,则b[i]++。这种算法的时间复杂度是O(n)。最后输出的时候对b数组输出非零值。
#include<stdio.h> int main() { int N,i,temp,count=0; int b[1001]={0}; scanf("%d",&N); for(i=1;i<=N;i++) { scanf("%d",&temp); b[temp]++; } for(i=1;i<=1000;i++) if(b[i]) count++; printf("%d\n",count); for(i=1;i<=1000;i++) if(b[i]) printf("%d ",i); return 0; }两种代码的时间复杂度:
算法的特征:
1.有穷性:有限步后停止。 2.确定性 3.输入:有0个或者1个输入 4.输出:有一个或者多个输出
5.可行性
算法的评价:
1.正确性
2.可读性:要多写注释,多利用规范的变量名
3.健壮性(容错性)——对于不规范的数据输入要有处理的能力。
4.时间复杂度; 大O表示法的定义在我的理解中 相当于高数的等价无穷大(忽视系数)
其中:速度上
O(1)> O(logn)(底数一般为二,不过可应用换底公式,然后忽略系数)> O(sqrt(n))> O(n)(线性查找,明明的算法的第三种算法,图像为一条直线) > O(n^2> O (n^3) .... > O(C^n) > O(n!)。
关于O(C^n)的证明 需应用高数上学期学习的极限知识。(好像最大时间复杂度一旦>=10^8,oj上就可能limit)
5.空间复杂度
int 32位二进制最大值为2147483648 10位。 注意:两个int的相加,相减,相乘都会溢出,在本学期oj系统习题上 ,老师出过相关溢出的编程题。
关于double 和 float :double : 64位二进制 double的科学计数法存储是 eg:2.33*10^2333;
double 占 8 个字节,64 位 :第一位为符号位(0表示正数,1表示负数);第2-12位表示指数部分
13-64 表示小数部分; 由于整数转换成二进制,在小数部分可能存在除不尽的情况,比如十进制0.3在转换成
二进制在小数部分会出现无限循环小数,因此double 存在精度差问题;
所以判断两double数相等时 是采用fabs(a-b)<eps; 其中eps=1e-6 或者1e-9;
在使用中不建议用float,float的精度过低。
8位二进制 = 1字节
1024字节 = 1 KB
1024KB = 1 MB
1024MB = 1 GB
注意一般对于编程的空间限制是512M,此时若按上值计算在最大可开10^8的int数组;
一个长度为10^6的double类型数组大约占8M;
注意:一般函数的递归使用对于空间的占据很大,所以一般将递归使用改为循环可减少空间复杂度。
二. 枚举
*一 一 列举 *不重复,不遗漏 但此时时间复杂度都比较大,会limit.
所以枚举算法的重点在于
1.选择合适的枚举对象。
2.选择合适的枚举方向-排除不符合条件的情况
3.选择合适的数据维护方法 - 转化问题。
题目1:最大正方形
在一个n*m的只包含0和1的矩阵里找出一个不包含0的最大正方形,输出边长。
输入文件第一行为两个整数n,m(1<=n,m<=100),接下来n行,每行m个数字,用空格隔开,0或1.
一个整数,最大正方形的边长
输入 #1复制
4 4 0 1 1 1 1 1 1 0 0 1 1 0 1 1 0 1输出 #1复制
2思路:使用枚举,判断所枚举的正方形是否符合条件。重点:如何简化枚举数量。
应用中学数学知识,在一个平面上两个对角线点可确定一个正方形。假设对角线上两点为:A:(X1,Y1),C;(X4,Y4) 则可求出
B:( (X1+X4)/2-(Y4-Y1)/2 ,(Y1+Y4)/2-(X4-X1)/2 ) D:( (X1+X4)/2+(Y4-Y1)/2 , (Y1+Y4)/2+(X4-X1)/2);
这样正方形的四个点就确定了 ,再按照题意判断是否符合条件。
代码:小姐姐讲的题目是 判断正方形四点是#的最大边长,洛谷里的题目是不包含0的最大边长,不太会写呀。准备看习题课小姐姐的代码了
题目2: 数列求和问题
给你一个数列{an}(1<=n<=100000),有q(1<=q<=100000)次询问,每次询问数列的第li个元素到第ri个元素的的和。
1.暴力求解法
直接双重循环计算。 此时最大的时间复杂度则是 10^5*10^5=10^10,肯定会出现limit。 一般情况下最大为10^8才可以过oj
2.简化思路,用sum[i]存储数组an中前i个数的和,那么sum[i]=sum[i-1] + a[i] , 当查询第li个元素到ri个元素的和时,可以用
sum[ri] - sum[li-1];
其中sum在算法中叫做前缀和,还有前缀最大和等,要注意,一般两个前缀和相减可得出子区间相关的值此时采用前缀和。
题目3:给你一个数列{an}(1<=n<=100000),有q(1<=q<=100000)次修改,每次把数列中的第li到ri的每个元素都加上一个值ki
,求所有的修改之后每个数的值。
题目2和题目3的复杂度瓶颈 在于对区间的修改需要对整个区间进行遍历。
所以要考虑转换: 将对区间的修改 改为 对区间端点的 修改,题目2 转化成对sum的修改
而本题则同理,此时区间每个元素都加上了ki,所以区间内每个元素减去前一个元素的差值不变,只有端点处的两处差值改变。
此时问题求解如2,设置一个delta数组记录数组an这个数与前一个数的差值。 若要还原数组,则只要delta的前缀和就是an;
我感觉这两个问题都可以理解为高中时的数列,sum是数列的前n项和,delta是各项数列之差。合理应用这两种前缀和和差分的
思想可以简化一定的时间复杂度。
题目4:校门外的树
某校大门外长度为 ll 的马路上有一排树,每两棵相邻的树之间的间隔都是 11 米。我们可以把马路看成一个数轴,马路的一端在数轴 00 的位置,另一端在 ll 的位置;数轴上的每个整数点,即 0,1,2,\dots,l0,1,2,…,l,都种有一棵树。
由于马路上有一些区域要用来建地铁。这些区域用它们在数轴上的起始点和终止点表示。已知任一区域的起始点和终止点的坐标都是整数,区域之间可能有重合的部分。现在要把这些区域中的树(包括区域端点处的两棵树)移走。你的任务是计算将这些树都移走后,马路上还有多少棵树。
第一行有两个整数,分别表示马路的长度 l 和区域的数目 m。
接下来 m行,每行两个整数 u, v,表示一个区域的起始点和终止点的坐标。
输出一行一个整数,表示将这些树都移走后,马路上剩余的树木数量。
输入 #1复制
500 3 150 300 100 200 470 471输出 #1复制
298数据规模与约定
- 对于 20\%20% 的数据,保证区域之间没有重合的部分。
- 对于 100\%100% 的数据,保证 1 \leq l \leq 10^41≤l≤104,1 \leq m \leq 1001≤m≤100,0 \leq u \leq v \leq l0≤u≤v≤l。
题解1:这道题我刚学c语言数组的时候接触过,第一遍做的时候就是暴力求解,初始数组为1,代表这个点有一颗树,然后进行m次遍历,每次将区间内的值改为0,最后对数组求和,计算出还剩多少棵树。
代码如下:
#include<stdio.h> int main() { int L , M,i,j; scanf("%d",&L); scanf("%d",&M); int b[2*M+1],a[L+1]; for(i=1;i<2*M+1;i=i+2) scanf("%d%d",&b[i],&b[i+1]); for(i=0;i<=L;i++) a[i]=1; for(i=1;i<2*M+1;i=i+2) for(j=b[i];j<=b[i+1];j++) a[j]=0; int count=0; for(i=0;i<=L;i++) count+=a[i]; printf("%d",count); return 0; }可以很明显地看出这是最笨的一种做法(奈何本人目前太菜,只能想出这样的作法),时间复杂度是O(N*M),若给的测试数据过大,最终肯定会limit;
题解2:那么如何用前缀和差分的思想求解呢?
很明显去掉树,就是对区间内的值进行减一,此时就是差分的算法。
题解3:若增大数据变为:1<=L<=10^9和1<=M<=100000,此时对于L长度为10^9,无法开数组,一般开int数组最大为10^8.
此时要用到离散化的思想,将对需要操作的M组数据进行存储并编排,因为M是<=100000,可以用数组存储。 对这M组对应数据排序,然后求树的数量只需对这M组数据进行操作。
题目5:给定长度为n的整数数列以及整数S,求出总和不小于S的连续字串的长度的最小值,如果解不存在,输出0
(n<=10^7).
题解1:三次循环,第一重循环遍历i,第二次循环遍历j,然后求i到j的和并比较。此时时间复杂度是O(n^3),肯定会limit
题解2:第一次循环 i,然后 j 从 i+1 开始遍历直到从 i 到 j 的和大于等于s,然后第二次i++,j从上次j+1开始遍历在直到>=s,然后比较长度。 这个很容易理解把S的和想象成一把尺子,这个尺子的长度不变,若尺子的前端往后移,则后端也一定往后移。
题目6:有一个N*M的灯泡(N<=10,M<=100),每次按某一个点可以使得其本身以及其上下左右共五个灯的额开关反向,给定初始状态(每个灯泡的亮或者灭),问:能否把所有灯都灭掉?
题解:如何减少枚举的次数? 当第1列 确定怎么按了的时候,此时只有第二列决定第一列灯泡的亮灭,而若要第一列的灯全部灭掉,此时第二列的开关按法也确定了。同理,第三列取决于第二列,第四列取决于第三列,第五列取决于第四列。这样第二三四五列都取决于第一列。这样问题变成对第一列进行枚举。此时时间复杂度是2^N*N*M=10^6,可以过。这种思想叫做(状态压缩)
此时对第一列的枚举,可以用位运算(可怜我一个大学生还不知道什么是位运算,我学了假的c语言?)
但位运算咋用咋也不知道,咋也听不懂!
关于这个熄灯问题,我有幸在b站上看过北大的一位老师的讲解:https://www.bilibili.com/video/BV1Hx411U7bh?p=4
我感觉这位老师讲的很详细,也有代码操作的实现与技巧,可以看一下。
位运算介绍(哎,作为一个大学生从来没接触过位运算,太丢人了!)
* << 左移 (1011)<<1 = (10110) 二进制1011左移一位为10110,相当于1011*2.
* >>右移 (1011)>>1= 101 二进制1011右移一位为101,相当于1011/2.
* |或 我感觉可以理解为 c语言 if语句中的||,不过运算符从两个竖杠变成了一个竖杠。
* & 与 我感觉可以理解为c语言中if语句中的&&,不过运算符从两个变成了一个。
* ~取反 相当于数学中的非,比如非0就是1,非1就是0. (我的理解)。
* ^异或 是不是不一样(相同为0,不同为1),在二进制中理解为不带进制的加法。 好处一个二进制
异或0不变,一个二进制异或1不变。
(我也是才学位运算才知道^这个符号怎么打的,原来必须要换成英文键盘后shift+6才会出来^,要不然会出来…… - - !)。
其中小姐姐说要注意注意位运算的优先级问题,她自己被坑了十多次,我还没用过位运算,咋也不知道,咋也不敢写。
三.贪心算法(早闻其名,今天终于知道啥叫贪心,贪心为什么正确了)
例1: 排队接水
有 n 个人在一个水龙头前排队接水,假如每个人接水的时间为Ti,请编程找出这 n 个人排队的一种顺序,使得 n 个人的平均等待时间最小。
第一行为一个整数 nn。
第二行 n 个整数,第 i 个整数Ti 表示第 i 个人的等待时间 Ti。
输出文件有两行,第一行为一种平均时间最短的排队顺序;第二行为这种排列方案下的平均等待时间(输出结果精确到小数点后两位)。
输入 #1复制
10 56 12 1 99 1000 234 33 55 99 812输出 #1复制
3 2 7 8 1 4 9 6 10 5 291.90- 您还可以看一下 吴京忠老师的计算机网络 静态路由和动态路由协议课程中的 01. 网络层实现的功能:只复杂路径选择且不可靠传输;网络排错准则小节, 巩固相关知识点